




摘要:在工业物联网(IIoT)数据爆发式增长的今天,通用数据库已难以应对海量测点的高频写入与复杂聚合查询。本文将从工程落地的角度出发,探讨时序数据库(TSDB)的选型关键维度,并深入解析 Apache IoTDB 在架构设计、数据模型及端边云协同方面的技术特性。
文章目录

一、 引言:为什么我们需要专用的时序数据库?
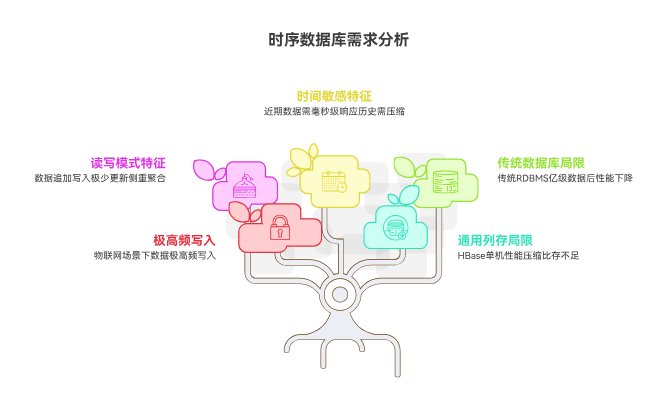
随着“工业4.0”和数字化转型的推进,企业面临的数据形态发生了根本性变化。不同于传统的交易型数据(OLTP)或文档型数据,物联网场景下的数据具有极为显著的特征:
- 极高频写入:一台风机可能有 500 个测点,以 100ms 的频率采集,秒级写入量即达 5000 点。若是整个风场,数据量级是惊人的。
- 写多读少,主要为聚合分析:数据通常是追加写入(Append Only),极少更新。查询往往不是查“某一行”,而是查“过去一小时的平均温升”。
- 时间敏感性:数据价值随时间衰减,近期数据需要毫秒级响应,历史数据则需要高压缩比存储。
传统的 RDBMS(如 MySQL)在数据量突破亿级后B+树索引维护成本过高,写入性能断崖式下跌;而基于 Hadoop 生态的通用列存(如 HBase)虽然解决了扩展性问题,但在单机性能、压缩比和运维复杂度上往往让中小团队望而却步。
因此,时序数据库(Time Series Database, TSDB) 应运而生。在进行 TSDB 选型时,我们不仅要看 Benchmark 分数,更要看其数据模型是否贴合业务、架构是否支持弹性扩展以及生态集成能力。
二、 选型核心维度与 IoTDB 的设计哲学
在评估一款 TSDB 时,工程团队通常关注三个核心指标:写入吞吐、存储成本(压缩比)、查询延迟。而在实际落地中,还有一个常被忽视但至关重要的维度:数据模型与物理世界的映射关系。
2.1 数据模型:树形结构 vs 标签模型
目前主流的 TSDB(如 InfluxDB, Prometheus)多采用 Tag-Value(标签)模型。这种模型在云原生监控(Kubernetes Metrics)场景下非常灵活,但在工业场景下却面临挑战。
工业场景的痛点: 工业设备通常具有严格的层级关系(集团 -> 工厂 -> 车间 -> 产线 -> 设备 -> 测点)。如果使用 Tag 模型,不仅会导致“高基数(High Cardinality)”带来的索引膨胀问题,且在描述物理层级时不够直观。
IoTDB 的解法:树形 Schema(Tree-based Schema)
Apache IoTDB 独创了“树形模式”来管理时间序列。它将设备层级直接映射为一条“路径”。
例如,我们要存储“北京工厂(ln) -> 1号车间(wf01) -> 钻机(wt01) -> 温度(temperature)”的数据,在 IoTDB 中,这条序列的名称就是:
root.ln.wf01.wt01.temperature
这种设计带来了两个巨大的工程优势:
- 无需复杂的索引设计:路径本身就是索引,前缀匹配查询(如“查询北京工厂所有设备的温度”)效率极高。
- 避免基数爆炸:在工业场景下,设备层级是相对固定的,树形结构完美规避了 Tag 组合产生的笛卡尔积爆炸问题。
2.2 存储引擎:LSM Tree 与 TsFile 的深度优化
写入性能是 TSDB 的生命线。IoTDB 底层采用了基于 LSM Tree (Log-Structured Merge Tree) 优化的存储引擎,并配合自研的 TsFile 文件格式。
核心技术拆解
-
极致压缩比的秘密
不同于通用数据库的块压缩(如 Snappy, GZIP),IoTDB 针对时序数据特性实现了列式编码压缩。- Gorilla 算法:针对浮点数(Float/Double),利用前后两个数据点变化不大的特性,只存储 XOR 差值。
- TS_2DIFF:针对二阶差分数据(如匀加速运动的数据)进行优化。
- RLE (Run-Length Encoding):针对状态量(如设备开关机状态 0/1),长时间不变化的数据可压缩至极致。
实测数据表明,在工业场景下,IoTDB 的磁盘占用通常仅为原数据的 1/10 甚至 1/50。
-
存算分离的基石:TsFile
TsFile 是一个类似于 Parquet/ORC 的独立文件格式。这意味着 Spark、Flink、Hive 等大数据引擎可以直接读取底层 TsFile 文件,而无需经过数据库引擎的查询层。
这种设计极大地消除了 ETL 过程中的序列化/反序列化开销,使得“一份数据,多处计算”成为可能。
架构流程图:IoTDB 写入与压缩流程
TsFile 的技术亮点:
- 列式存储与编码压缩:不同类型的数据采用不同的编码。例如,时间列采用 Delta 编码,数值列采用 Gorilla 或 TS_2DIFF 算法,文本列采用 Dictionary 编码。这使得 IoTDB 通常能达到 10:1 甚至 20:1 的压缩比,极大地降低了存储成本。
- 独立格式:TsFile 是一个类似于 Parquet 的独立文件格式。这意味着 Spark、Flink 等大数据引擎可以直接读取 TsFile 文件,而无需经过数据库引擎,实现了计算与存储的解耦。
2.3 分布式架构:MPP 与 共识协议
当单机性能达到瓶颈时,分布式集群的能力显得尤为重要。IoTDB 1.0 之后引入了全新的分布式架构,包含 ConfigNode (管理元数据与分区) 和 DataNode (存储数据)。
-
MPP (Massively Parallel Processing) 查询框架:
查询不再由单节点串行处理。例如,一个聚合查询select avg(temp) from root.sg.*会被拆解为多个 Fragment,分发到不同的 DataNode 并行计算,最后由协调节点汇总。这使得查询延迟随着节点增加而线性降低。 -
多级共识协议 (Consensus):
针对不同的一致性需求,IoTDB 提供了多种选择:- IoTConsensus:专为时序优化的共识协议,支持高可用和高写入吞吐。
- Ratis (Raft 实现):强一致性保障,适用于元数据管理。
- SimpleConsensus:单副本极速写入。
这种灵活的架构设计,让 IoTDB 既能运行在 1 核 2G 的边缘网关上,也能运行在数百节点的云端集群中,真正实现了“端边云统一内核”。
三、 实战演练:从定义到分析
为了更直观地理解 IoTDB 的易用性,我们通过一个简单的代码示例来演示如何构建一个物联网数据存储方案。
3.1 环境准备
首先,你需要下载 IoTDB 的运行包。
- IoTDB 下载链接:
https://iotdb.apache.org/zh/Download/ - 企业版服务(Timecho):
https://timecho.com
启动服务后,我们可以使用 CLI 或编程语言 SDK 进行交互。
3.2 SQL 交互:类 SQL 的低门槛体验
IoTDB 的查询语言(IoTDB-SQL)与标准 SQL 高度兼容,降低了学习成本。
-- 1. 创建存储组(相当于数据库)
CREATE STORAGE GROUP root.ln
-- 2. 创建时间序列(定义测点)
-- 路径:root.ln.wf01.wt01.status, 类型:BOOLEAN, 编码:RLE
CREATE TIMESERIES root.ln.wf01.wt01.status WITH DATATYPE=BOOLEAN, ENCODING=RLE
-- 3. 插入数据
INSERT INTO root.ln.wf01.wt01(timestamp, status) values(1700000000000, true)
-- 4. 降采样查询(Downsampling)
-- 查询过去1天内,每1小时的状态变化次数
SELECT COUNT(status)
FROM root.ln.wf01.wt01
GROUP BY ([now() - 1d, now()), 1h)
3.3 Java Native API:高性能写入
对于高吞吐场景(如每秒百万点写入),推荐使用 Java Session API(基于 RPC 优化的原生接口)。
import org.apache.iotdb.session.Session;
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
import java.util.ArrayList;
import java.util.List;
public class IoTDBExample {
public static void main(String[] args) throws Exception {
// 1. 初始化 Session
Session session = new Session("127.0.0.1", 6667, "root", "root");
session.open();
// 2. 准备批量数据
String deviceId = "root.ln.wf01.wt01";
List<Long> times = new ArrayList<>();
List<String> measurements = new ArrayList<>();
List<List<Object>> values = new ArrayList<>();
List<TSDataType> types = new ArrayList<>();
measurements.add("temperature");
types.add(TSDataType.FLOAT);
for (long i = 0; i < 100; i++) {
times.add(System.currentTimeMillis() + i);
List<Object> row = new ArrayList<>();
row.add(20.0 + Math.random() * 10); // 模拟温度数据
values.add(row);
}
// 3. 批量插入 (InsertTablet 模式,性能最高)
// 注意:实际生产中建议使用 SessionPool
// session.insertTablet(...); // 省略 Tablet 构建细节,InsertTablet 比 InsertRecords 快数倍
System.out.println("数据写入完成");
session.close();
}
}
四、 进阶特性:端边云协同(Edge-Cloud Sync)
这是 IoTDB 区别于许多国外开源 TSDB 的一大杀手锏。
在工业现场,网络环境往往是不稳定的。如果边缘端的网关直接连接云端数据库,网络中断会导致数据丢失。传统的做法是自己开发一套“缓存+重传”的中间件,复杂且难以维护。
IoTDB 提供了一套开箱即用的数据同步框架(IoTDB-Pipe / Sync)。
架构图:端边云同步机制
工作机制:
- 轻量级部署:在资源受限的工控机或树莓派上部署 IoTDB 边缘版。
- 本地存储:数据先落盘到边缘端,保证数据的绝对安全和本地实时控制的低延迟。
- 断点续传:Pipe 模块负责将数据异步发送到云端。如果网络断开,Pipe 会自动记录传输进度(Offset),待网络恢复后从断点处继续传输,彻底解决了数据完整性问题。
五、 总结与建议
在时序数据库的选型中,没有绝对的“最好”,只有“最合适”。
- 如果你的场景是IT 运维监控,Prometheus 依然是事实标准。
- 如果你的场景是工业物联网(IIoT),面临着设备层级复杂、写入吞吐量大、网络环境不稳定等挑战,那么 Apache IoTDB 凭借其树形数据模型、极高的压缩比(降低硬件成本)以及原生的端边云协同能力,无疑是当前极具竞争力的选择。
IoTDB 不仅仅是一个数据库,更是一个连接物理世界与数字世界的桥梁。对于追求自主可控、高性能和架构简洁的工程团队来说,IoTDB 值得深入探索。
附录:资源链接
- Apache IoTDB 官方下载:
https://iotdb.apache.org/zh/Download/

- 商业化支持与企业版(天谋科技):
https://timecho.com

- GitHub 仓库:https://github.com/apache/iotdb
本文旨在从技术角度解析时序数据库选型思路,内容基于 Apache IoTDB 现有技术架构编写,供开发者参考。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











