







 超级会员免费看
超级会员免费看
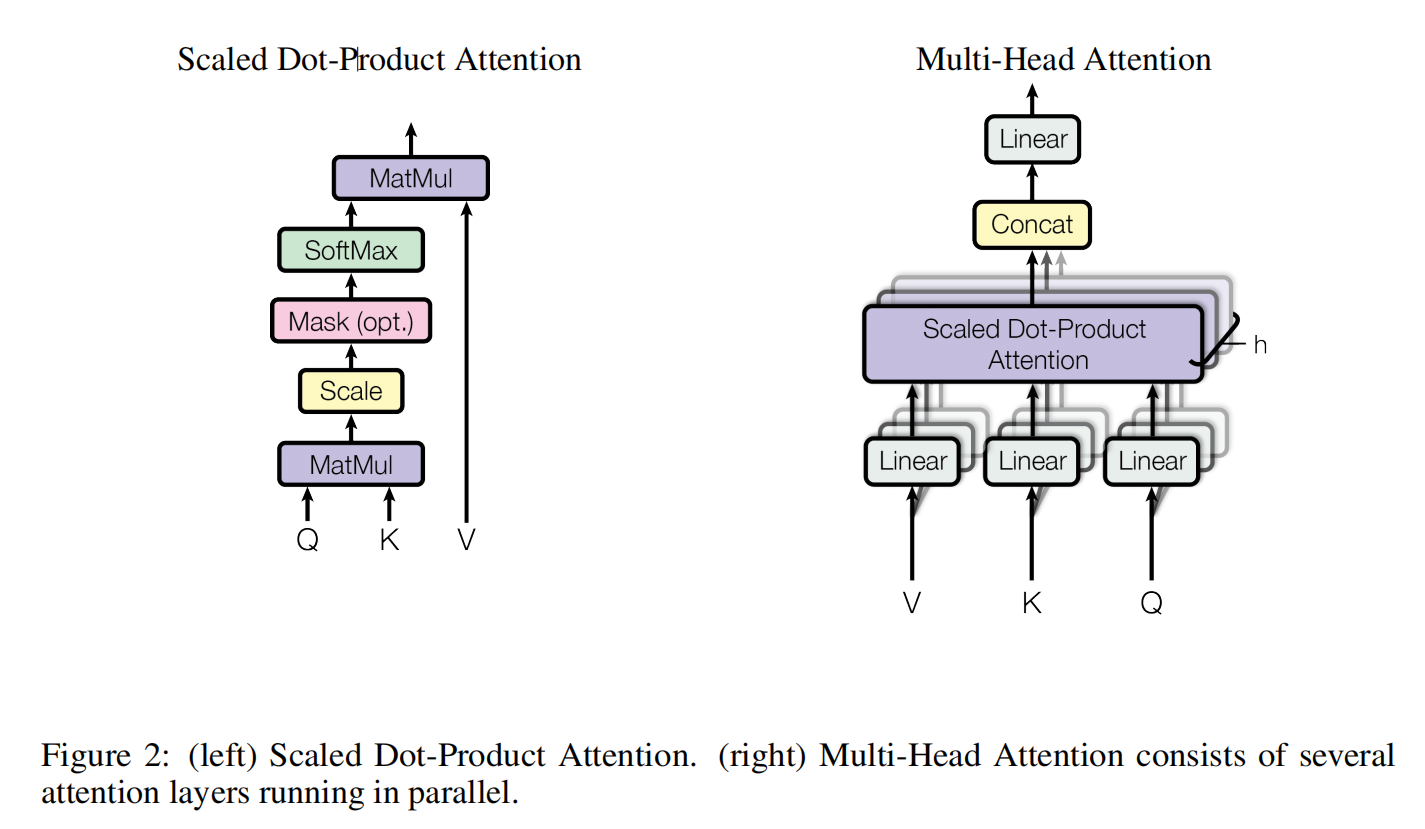
Figure 2展示了Transformer模型中的两个关键组件:Scaled Dot-Product Attention(缩放点积注意力)和Multi-Head Attention(多头注意力)。这两张图分别对应这两个机制的工作原理。
1. Scaled Dot-Product Attention(缩放点积注意力)
左图展示的是缩放点积注意力的计算过程。这个机制是Transformer中自注意力机制的核心部分。它的作用是通过计算输入序列中每个元素之间的相关性,来决定每个元素在输出中的权重。
1.1 输入
- Query(查询):可以理解为当前要处理的元素。
- Key(键):可以理解为序列中其他元素的标识。
- Value(值):可以理解为序列中其他元素的实际内容。
1.2 计算步骤
- 计算点积:首先,计算Query和Key的点积。这个点积表示Query和Ke

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











