




文章目录
一、定义
我们在企业环境中由于数据库性能的不足,有时候要针对性地做出优化
但是我们在真实企业环境中一般都是优先考虑更换硬盘,再去考虑软件和操作系统方面的问题
二、索引优化
我们先去构建100万条测试数据,这样就能验证我们使用索引的高效性
-- 修改SQL结束符
delimiter //
-- 创建存储过程
CREATE PROCEDURE p_init_index_data ()
BEGIN
-- 生成学号和主键
DECLARE id BIGINT DEFAULT 100000;
-- 年龄
DECLARE age TINYINT DEFAULT 18;
-- 性别
DECLARE gender BIGINT DEFAULT 1;
-- 班级编号
DECLARE class_id BIGINT DEFAULT 1;
-- 循环计算
DECLARE count INT DEFAULT 0;
-- 创建表
DROP TABLE IF EXISTS index_demo;
CREATE TABLE index_demo (
id bigint auto_increment,
sn varchar(10) NOT NULL,
name varchar(20) NOT NULL,
mail VARCHAR(20),
age TINYINT(1),
gender TINYINT(1),
password VARCHAR(36) NOT NULL,
class_id bigint NOT NULL,
create_time DATETIME NOT NULL,
update_time DATETIME NOT NULL,
PRIMARY KEY (id),
index (class_id)
);
-- 插入一条测试数据
INSERT INTO index_demo VALUES (100000, '100000', 'testUser', '100000@qq.com', 18, 1, UUID(), 1, NOW(), NOW());
-- 循环构建数据
WHILE count < 1000000 DO
-- ID和学号
SET id := id + 1;
-- 年龄
IF count % 10 = 0 THEN
SET age := age + 1;
END IF;
IF age > 50 THEN
SET age := 16;
END IF;
-- 性别
IF count % 3 = 0 THEN
SET gender := 0;
ELSE
SET gender := 1;
END IF;
-- 班级编号
SET class_id := class_id + 1;
IF class_id > 10 THEN
SET class_id := 1;
END IF;
-- 写入数据
INSERT INTO index_demo VALUES (id, id, CONCAT('user_',id), CONCAT(id,'@qq.com'), age, gender, UUID(), class_id, NOW(), NOW());
-- 更新count
SET count := count + 1;
END WHILE;
END //
-- 还原SQL结束符
delimiter ;
-- 调用存储过程,开始构建数据,大约20 - 100分钟左右
CALL p_init_index_data();
好,现在我们来测试使用索引的效率,我们先来看看不使用索引查询的速度
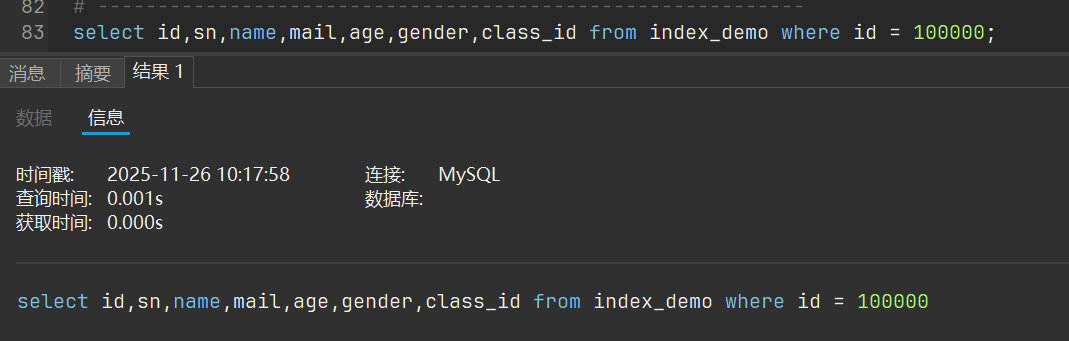
可以看到非常的快啊,我们再来看看如果不去使用索引
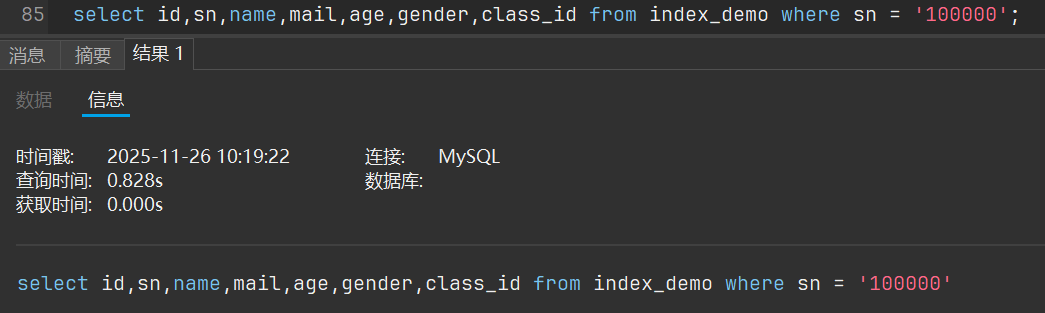
explain执行字段分析
好,接下来我们都通过explain关键字去分析我们的SQL语句

我们来逐一解释下各个字段的简单含义
1. id
表示select语句的查询的序号,如果你有子查询或者是合并查询,这个编号就会依次递增
我们新建学生表和成绩表,插入一些测试数据
-- 创建学生信息表
CREATE TABLE students (
student_id INT PRIMARY KEY AUTO_INCREMENT,
student_no VARCHAR(20) NOT NULL UNIQUE COMMENT '学号',
student_name VARCHAR(50) NOT NULL COMMENT '学生姓名',
gender ENUM('男', '女') NOT NULL DEFAULT '男' COMMENT '性别',
age TINYINT COMMENT '年龄',
class_name VARCHAR(50) NOT NULL COMMENT '班级名称',
enrollment_date DATE COMMENT '入学日期',
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建索引
CREATE INDEX idx_class_name ON students(class_name);
CREATE INDEX idx_student_name ON students(student_name);
-- 创建成绩表
CREATE TABLE scores (
score_id INT PRIMARY KEY AUTO_INCREMENT,
student_id INT NOT NULL COMMENT '学生ID',
course_name VARCHAR(50) NOT NULL COMMENT '课程名称',
score DECIMAL(5,2) NOT NULL COMMENT '成绩',
exam_date DATE NOT NULL COMMENT '考试日期',
semester VARCHAR(20) COMMENT '学期',
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (student_id) REFERENCES students(student_id) ON DELETE CASCADE
);
-- 创建索引
CREATE INDEX idx_course ON scores(course_name);
CREATE INDEX idx_exam_date ON scores(exam_date);
CREATE INDEX idx_student_course ON scores(student_id, course_name);
-- 插入学生数据(1000名学生)
DELIMITER //
CREATE PROCEDURE insert_test_data()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE student_count INT DEFAULT 1000;
DECLARE class_count INT DEFAULT 10;
-- 插入学生数据
WHILE i <= student_count DO
INSERT INTO students (
student_no,
student_name,
gender,
age,
class_name,
enrollment_date
) VALUES (
CONCAT('2024', LPAD(i, 4, '0')), -- 学号
CONCAT('学生', i), -- 姓名
IF(RAND() > 0.5, '男', '女'), -- 性别
FLOOR(16 + RAND() * 5), -- 年龄16-20
CONCAT('班级', FLOOR(1 + RAND() * class_count)), -- 班级
DATE_SUB(CURDATE(), INTERVAL FLOOR(RAND() * 365) DAY) -- 入学日期
);
SET i = i + 1;
END WHILE;
-- 为每个学生插入5门课程的成绩
SET i = 1;
WHILE i <= student_count DO
-- 语文
INSERT INTO scores (student_id, course_name, score, exam_date, semester)
VALUES (i, '语文', ROUND(50 + RAND() * 50, 1), CURDATE(), '2024-2025上学期');
-- 数学
INSERT INTO scores (student_id, course_name, score, exam_date, semester)
VALUES (i, '数学', ROUND(50 + RAND() * 50, 1), CURDATE(), '2024-2025上学期');
-- 英语
INSERT INTO scores (student_id, course_name, score, exam_date, semester)
VALUES (i, '英语', ROUND(50 + RAND() * 50, 1), CURDATE(), '2024-2025上学期');
-- 物理
INSERT INTO scores (student_id, course_name, score, exam_date, semester)
VALUES (i, '物理', ROUND(50 + RAND() * 50, 1), CURDATE(), '2024-2025上学期');
-- 化学
INSERT INTO scores (student_id, course_name, score, exam_date, semester)
VALUES (i, '化学', ROUND(50 + RAND() * 50, 1), CURDATE(), '2024-2025上学期');
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
-- 执行插入测试数据
CALL insert_test_data();
然后我们进行子查询试下
explain select * from scores where student_id = (select student_id from students where student_name = '学生1');

可以看到我们子查询的id号是2
2. select_type
这个表示我们的语句类型,参照上图,我们类型一般分为这几种
simple不包含union和子查询的select查询primary key表示主键查询union表示union连接的后续的语句union result表示union查询的结果subquery表示子查询insert表示插入update表示更新delete表示删除
3. table
表示我们数据行所在的表名
4. partiotions
表示一张表的不同分区,但是现在一般少用了
5. possible_key
表示语句中可能会用到的索引,如果不使用索引则表示为null
6. key
表示语句中实际用到的索引,同理如果是null表示没有索引可用
7. key_len
表示索引的字节长度
8. ref
表示语句中哪些列或者是常量和索引列比较
9. rows
表示语句需要检查的行数,数值越小效率越高
10. filtered
表示对结果筛选的百分比,数值越大表示数据需要过滤的程度就越小
11. type列
性能由好到差依次为
system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unqiue_subquery>index_subquery>range>index>all
system
当我们的表中只有一条数据的时候,不用进行全表扫描或者是索引树扫描,它是const的特殊情况
const
表示通过主键/唯一索引和常量值进行比较,结果仅仅匹配一行的精准匹配
eq_ref
表示表连接查询,并且表A的一条记录仅仅和表B的一条记录匹配,即一对一关系
ref
表示普通索引列,可以重复但是不能为空,即多对一关系
就比如我们之前查询的图片里就是ref种类
fulttext
表示全文索引,这个目前不讨论
ref_or_null
表示索引可以为空的情况
index_merge
表示使用了多个索引,使用or进行连接,并且两边必须是单独的索引,我们使用我们之前创建的100万条数据的表
explain select * from index_demo where class_id = 1 or id = 1;

unqiue_subquery
表示进行子查询的时候,返回的结果是主键索引或者是唯一索引
index_subquery
在unqiue_subquery中返回的是普通索引列
range
表示使用范围查询
index
表示扫描了整棵索引树,效率低下
explain select * from index_demo order by class_id limit 1000;

all
这个是效率最低下的全表扫描
12. extra列
如果出现using filesort表示使用文件排序,这是非常不好的情况,会创建一个临时文件并且频繁IO
同理如果出现using tempory表示使用临时表排序,当我们使用非索引列排序,就会先把数据加载到临时表中,这会占用内存空间,导致内存占满
我们接下来再看其他几种
using where
表示我们使用了非索引列进行检索,并且进行了索引树扫描或者是全表扫描
using index
using index
表示发生索引覆盖
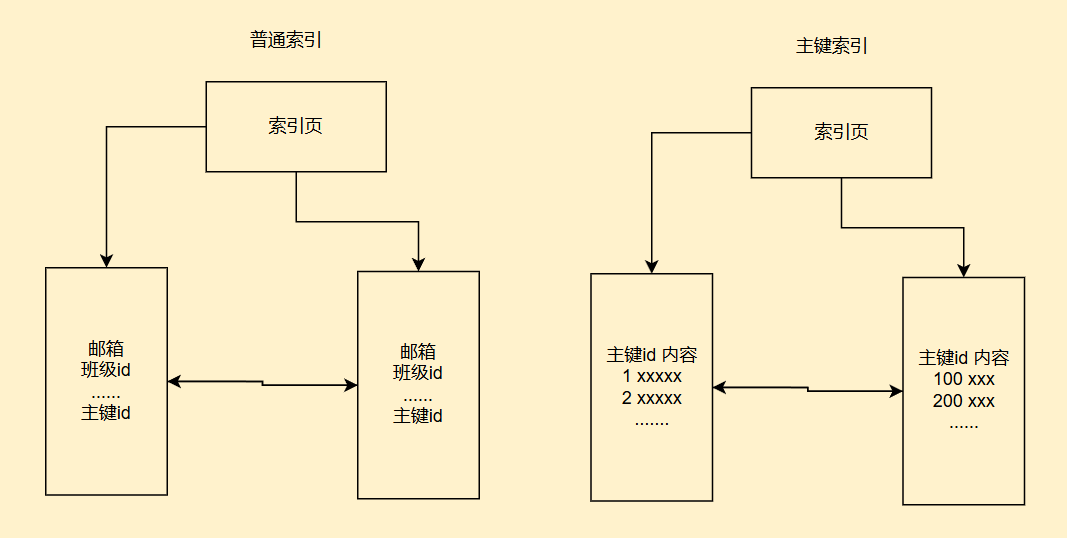
索引覆盖指的就是我们查询的结果列就是我们的索引列,无需进行回表操作
因为我们innodb存储引擎就算没有索引,也会给每一张表默认生成一个索引,这个索引的id值存放的就是一条条数据,而我们建立普通索引,这个普通索引中就存放着我们默认索引树的主键id
当我们的查询中包含了不是索引的列,就会拿着这个主键id的值回到默认的全表索引树中进行查询
我们画个图来说明
三. MySQL对select语句优化
1. where子句优化
- 删除不必要的括号
有时候我们程序员为了方便阅读和指明执行的优先级,会加入一些括号
((a and b) and c or ((a and b) and (c and d)));
那么MySQL逻辑优化就会变成
(a and b and c) or (a and b and c and d);
- 合并常量
(a < b and b = c) and a = 5;
那么MySQL逻辑优化就会变成
5 < b and b = c and a = 5;
- 去除不必要的常量,去掉不合理的常量逻辑判断
(b >= 5 and b = 5) or (b = 6 and 5 = 5) or (b = 7 and 5 = 6);
那么MySQL逻辑优化就会变成
b = 5 or b = 6;
- 删除超出范围或者是无效的值
比如我们有一列是unsigned int类型,是一个字节只能填入0~255范围内的数据,但是如果你指定where id < 255,MySQL会认为你这个数据合理,自动优化成where 1
- 优化查询常量表,即通过
where语句筛选后只包含一个条数据的表,便于快速带入这个条件查询
- 提前去检测无效的常量表达式,返回空结果集
- 如果你不去使用聚合函数,你的
having子句和where子句合并,它们两本质上都是一个东西 where条件中count(*)直接会从ISAM和MEMORY表中去检索信息
以下是一些高效查询的示例代码,只是建议这么写,具体还要看业务场景
-- 使用覆盖索引避免回表查询
SELECT key_part1, key_part2 FROM tbl_name
WHERE key_part1 = 'value';
-- 利用索引进行范围查询后排序
SELECT * FROM tbl_name
WHERE key_part1 > 100
ORDER BY key_part1 LIMIT 5;
-- 复合索引最左前缀匹配查询
SELECT * FROM tbl_name
WHERE key_part1 = 'abc' AND key_part2 LIKE 'prefix%';
-- 索引列分组统计(避免全表扫描)
SELECT key_part1, COUNT(*) FROM tbl_name
GROUP BY key_part1;
-- 利用索引优化DISTINCT去重
SELECT DISTINCT key_part1 FROM tbl_name;
-- 联合查询时驱动表使用索引过滤
SELECT t1.* FROM table1 t1
INNER JOIN table2 t2 ON t1.indexed_col = t2.indexed_col
WHERE t1.indexed_col = 'filter';
2. 范围查询优化
1. 单部索引范围访问
即一张表中只有一个索引列,什么是范围条件呢
- 在B+树和哈希表中索引使用了
= <=> in()等索引值和常量值的比较 - 在B+树中使用了
> < >= <= between()索引值和常量值的比较 like关键字比较的不是以通配符开头的字符串,比如张%- 用多个
or and组合形成的范围条件
综上,我们MySQL优化思路就是不能用于构建范围的条件将被删除,范围重叠则进行合并,如果是一个空范围则删除
比如就有一条示例代码,其中key为索引列,nokey为非索引列
(key < 'abc' and (key like 'abcd%' or key like '%c')) or
(key < 'bac' and nokey = 2) or
(key < 'ppx' and key > 'z')
删除不符合范围的,不是索引的范围
(key < 'abc' and (key like 'abcd%' or true)) or
(key < 'bac' and true) or
(key < 'ppx' and key > 'z')
再去删除空条件,整合语句
(key < 'abc' and true) or (key < 'bac' and true) or false
再进一步整合,根据ASCII码值大小进行取舍判断
key < 'bac'
2. 多部索引范围访问
我们之前已经明确了每张表会默认存在个存放全表数据的索引树
当我们使用B+树的索引,并且有下面一条示例语句
key1 = 'aaa' and key2 > 10 and key3 < 15;
当我们第一个条件key1 = 'aaa'的时候,如果是= <=> is null的时候就回去使用索引
一旦我们任意一个条件使用了范围查询,那么后续的范围查询将不再使用索引,因此key2 > 10可以去使用索引,key3 < 15则不能使用索引
如果使用了or表示了多个范围,则最后的结果是取并集操作
3. 索引合并优化
以前的版本,由于我们之前说过如果查询非索引列,就需要拿着主键id进行一个一个的回表查询操作,消耗大量的磁盘IO
现在版本就可以针对多个索引树进行扫描,把查询到的不同的索引结果集放在内存中取并集或者是交集,再进行回表操作
用到了交叉访问算法、联合访问算法,排序联合算法
4. 索引下推优化
对于这样一句SQL
select * from user where name like '李%' and age = 20;
如果没有优化,则我们查出姓李的人后,还要根据其主键id进行回标操作,寻找age = 20的人再把结果返回,消耗大量IO
MySQL进行优化后,直接查出姓李的人,然后直接在内存中判断哪些满足age = 20,然后再一次筛选,把筛选后的主键id再进行回表操作,这样就减少了回表次数,节省了IO
5. 外连接优化
比如一个左外连接a left join b 连接条件
- 表
b是依赖于表a的,如果表a还依赖其他表,则表b也依赖这些表 - 表
a依赖于连接条件中的表,比如这种情况就是表a依赖于表b
aleft join a.列 = b.列 and a.列 = c.列
- 在不包含where子句中,连接条件约束的是表
b的行为 - 读取顺序是先读取依赖表,再去读取当前的表,如果存在循环依赖则报错。比如
a<--b,c<--c,但是b<--c这样会导致循环依赖,就会报错 - 如果表
a中有一行条件匹配,但是在表b中不存在这一个数据行,则会使用null表示
当进行连接的时候就会
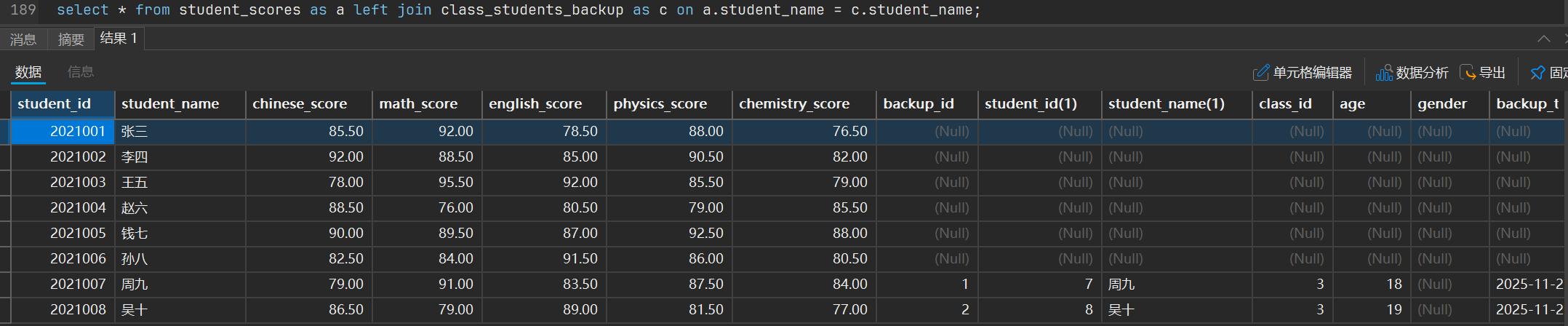
6. is null优化
分为在可以为空的索引列使用is null和在不可以为空的索引列使用is null
通俗理解,你在不可以为空的索引列使用is null不是多此一举吗,因此这个条件就永远为假,就会自动优化掉
7. order by优化
如果我们不去使用索引列进行作为排序依据,则会使用一个临时文件进行IO操作,浪费资源
并且我们在使用复合索引时候,一定要按照你创建的顺序使用,如果顺序乱了可能会导致用临时文件IO了
当然,如果你不使用索引作为order by条件,你也可以把它作为where的条件
但是,我想说,如果你改变了索引的值,不论怎么改,都会导致索引直接失效
8. group by&distinct优化
原理就是先会把符合where条件的数据放进临时表中,再去分离每个组,如果用了聚合函数则会应用到每个组
但是我们知道,索引它是连续的,在B+树中是可以前后访问的,因此就没有必要使用临时表
9. 函数使用优化
如果是确定性函数就会使用索引,对于不确定性函数如果你把其结果使用一个变量接收,后续对这个变量使用的时候也会用到索引
四、再谈索引失效问题
这里给出我之前的文章博客链接
总之,到底是否要使用索引,都是优化器自己决定的
五、索引使用原则
- 建议每张表都必须有索引,可以使用
bigint主键自增 - 使用
distinct,order by等条件使用索引列 - 对于频繁增删改查的表,不能规定太多索引以免影响效率
- 遵守最左原则,即使用索引时按照创建的顺序使用,并且不能断开,像
key1 key3就不行,中间少了key2 - 多表
join如果可以简化,建议用多个单表查询提高效率,再把查询结果在程序中进行合并,即不推荐使用多表连接,如果硬要则要在三个以内 - 避免在值太单一的列创建索引,比如性别
- 你可以指定是否使用索引:
建议 use index(...) 强制 force index(...) - 创建索引时可以去指定索引树的排序方式:
create index (key1 desc,key2 asc) - 创建索引的时候要保证服务器压力是最小的时候,以免影响主业务
- 不常用的索引要进行清理,以免占用内存
总之,如果你使用explain关键字后发现其效率低下,则要进行索引优化
有索引就尽量使用索引,创建索引,提高我们数据库的增删改查效率
五、索引使用原则
- 建议每张表都必须有索引,可以使用
bigint主键自增 - 使用
distinct,order by等条件使用索引列 - 对于频繁增删改查的表,不能规定太多索引以免影响效率
- 遵守最左原则,即使用索引时按照创建的顺序使用,并且不能断开,像
key1 key3就不行,中间少了key2 - 多表
join如果可以简化,建议用多个单表查询提高效率,再把查询结果在程序中进行合并,即不推荐使用多表连接,如果硬要则要在三个以内 - 避免在值太单一的列创建索引,比如性别
- 你可以指定是否使用索引:
建议 use index(...) 强制 force index(...) - 创建索引时可以去指定索引树的排序方式:
create index (key1 desc,key2 asc) - 创建索引的时候要保证服务器压力是最小的时候,以免影响主业务
- 不常用的索引要进行清理,以免占用内存
总之,如果你使用explain关键字后发现其效率低下,则要进行索引优化
有索引就尽量使用索引,创建索引,提高我们数据库的增删改查效率

















 1854
1854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









