



聚合报告(aggregate report)
对于每个请求,它统计响应信息并提供请求数,平均值,最大,最小值,错误率,大约吞吐量(以请求数/秒为单位)和以kb/秒为单位的吞吐量.
吞吐量是以取样目标点的视角来统计的(例如:HTTP请求样例中设置的远程服务器). JMeter会把已生成请求的总响应时间考虑在内,所以,如果相同线程组中有其它取样器或定时器,将增加总时间,进而减少吞吐量的值。因此,两个仅名称不同的取样器,其吞吐量为该两个取样器吞吐量总和的一半。正确的选择取样器名字对于重聚合报告中获取最佳的结果来说很重要。
个人理解:不管是否有其它取样器还是定时器,这里主要是基于时间和请求数的计算,吞吐量= 请求数/总时间,拿定时器来说,它具有线程延迟功能,不增加请求数的情况下,增大总时间,自然吞吐量就减少了。
这笔者做了个实验,每次运行一次,每次手动运行,且每次运行前不清空结果,运行测试,查看聚合报告显示。因为手动运行,每两次运行期间,都有空闲期,在这段空闲期有时候还比较长,几分钟到几十分钟不等。
结果发现,聚合报告是累加的,即每次运行的结果统计都是基于前一次运行的结果进行统计,包括发起的请求样本数等都是叠加的,比如我11:00运行一次,发起10个请求,11:20运行一次,发起10个请求,这时聚合报告显示请求数为20个,而此时的吞吐量和第一次运行相差甚远,个人猜测它把11:00到11:20期间非运行状态的时间也算进去了。所以,总时间大大增加。
不勾选“标签中不包含名称(include group name in label)”复选框
注意:使用聚合报告时,测试计划中不要用相同的的请求取样器名称
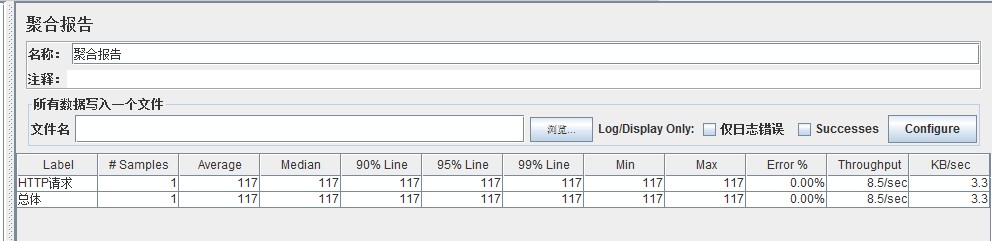
Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name 属性的值
#Samples:表示你这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100
Average:平均响应时间——默认情况下是单个 Request 的平均响应时间,当使用了 Transaction Controller 时,也可以以Transaction 为单位显示平均响应时间
Median:中位数,也就是 50% 用户的响应时间
90% Line:90% 用户的响应时间
Note:关于 50% 和 90% 并发用户数的含义,请参考下文
http://www.cnblogs.com/jackei/archive/2006/11/11/557972.html
Min:最小响应时间
Max:最大响应时间
Error%:本次测试中出现错误的请求的数量/请求的总数
Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second),当使用了 Transaction Controller 时,也可以表示类似 LoadRunner 的 Transaction per Second 数
KB/Sec:每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec


















 3267
3267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









