




 本文介绍了如何使用Python的scikit-learn库实现Adaboost和Bagging集成学习算法,特别是针对西瓜数据集3.0a。通过分析,发现Adaboost在不剪枝决策树作为基学习器时可能导致过拟合,而Bagging在决策树桩作为基学习器时效果不佳,但在全决策树时能有效降低方差。
本文介绍了如何使用Python的scikit-learn库实现Adaboost和Bagging集成学习算法,特别是针对西瓜数据集3.0a。通过分析,发现Adaboost在不剪枝决策树作为基学习器时可能导致过拟合,而Bagging在决策树桩作为基学习器时效果不佳,但在全决策树时能有效降低方差。
scikit-learn及其安装
scikit-learn
scikit-learn是一个python的机器学习工具,可以进行简单高效的数据挖掘和数据分析,基于NumPy,SciPy和matplotlib构建。
| 功能 | 简介 | 应用举例 |
|---|---|---|
| 分类(Classification) | 识别物体属于哪个类别 | 图像识别 |
| 回归 (Regression) | 预测与对象关联的连续值属性 | 预测趋势 |
| 聚类(Clustering) | 自动将相似对象归为一组 | 分组实验结果 |
| 降维(Dimensionality reduction) | 减少要考虑的随机变量的数量 | 可视化 |
| 模型选择(Model selection) | 比较,验证和选择参数和模型 | 提高准确性 |
| 预处理(Preprocessing) | 特征提取和归一化 | 转换输入数据 |
安装
本文中的安装主要是基于PyCharm,如果不是的话建议在网上寻找相对应的安装方法,在这里就不再赘述。
-
点击File(文件)菜单,在下拉菜单中选择settings(设置)
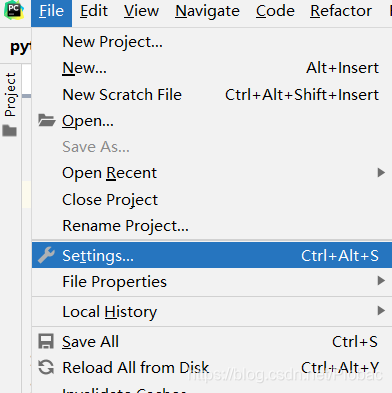
-
其次,在project interpreter(项目解释器)中点击“+”号
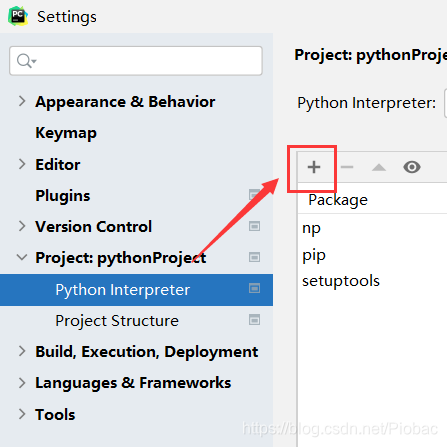
-
在搜索框中输入所要添加的第三方库的名称,如NumPy,然后在左下角点击第一个选项Install Package。
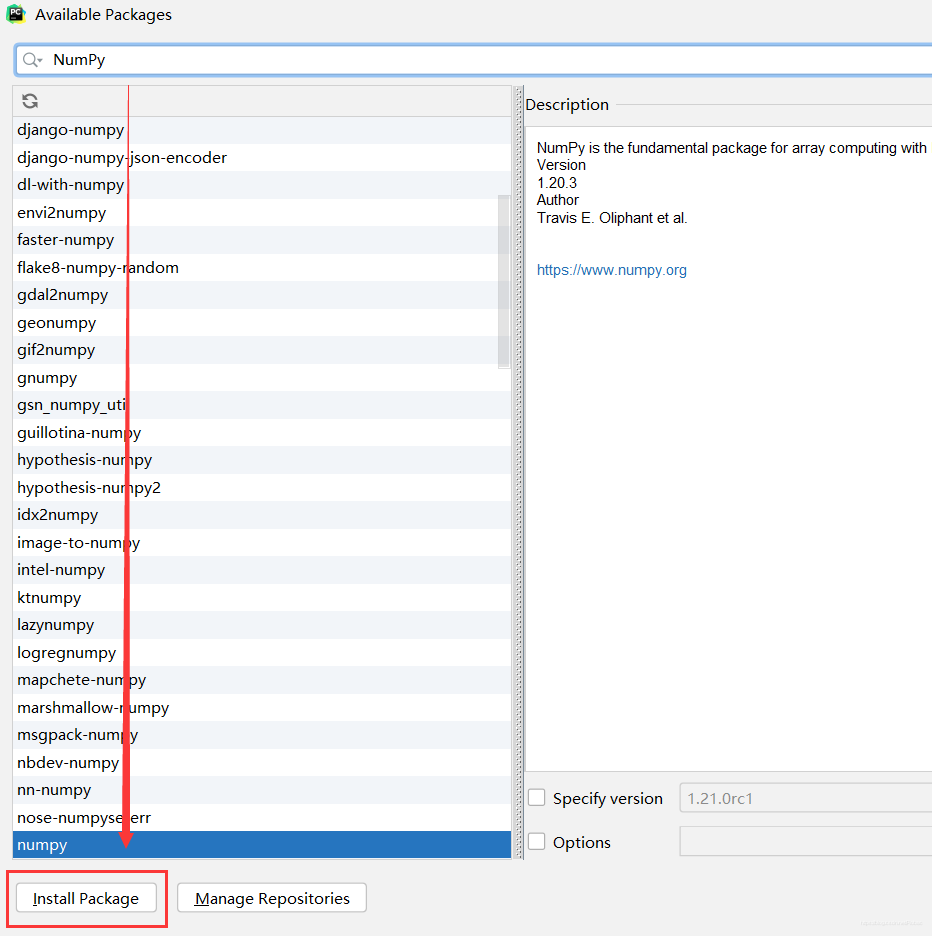
-
安装完成之后就会有提示。
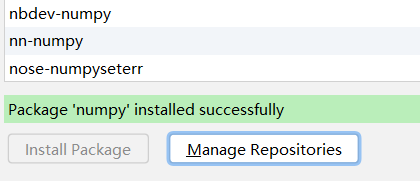
-
等到安装好下面所示的这些库之后关闭重启即可。
-
下面是前置清单:
- Python (>= 3.5)
- NumPy (>= 1.11.0)
- SciPy (>= 0.17.0)
- joblib (>= 0.11)
- Matplotlib版本(>=1.5.1)
- scikit-image(> = 0.12.3)
- pandas(> = 0.18.0)
集成学习
一、利用sklearn库进行分析
直接上代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import BaggingClassifier, AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
# 西瓜数据集3.0a
D = np.array([
[1, 1, 1, 1, 1, 1, 0.697, 0.460, 1],
[2, 1, 2, 1, 1, 1, 0.774, 0.376, 1],
[2, 1, 1, 1, 1, 1, 0.634, 0.264, 1],
[1, 1, 2, 1, 1, 1, 0.608, 0.318, 1],
[3, 1, 1, 1, 1, 1, 0.556, 0.215, 1< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









