






 本文回顾了正则表达式,并详细介绍了Linux文本处理三剑客——grep、sed和awk的使用。grep主要用于查找匹配正则表达式的行,sed用于编辑流数据,实现增删改查功能,awk则是一种强大的文本分析工具,擅长处理和格式化文本。文中通过实例展示了三者在实际操作中的应用。
本文回顾了正则表达式,并详细介绍了Linux文本处理三剑客——grep、sed和awk的使用。grep主要用于查找匹配正则表达式的行,sed用于编辑流数据,实现增删改查功能,awk则是一种强大的文本分析工具,擅长处理和格式化文本。文中通过实例展示了三者在实际操作中的应用。
1. 正则表达式回顾:
| 正则表达式分类: | 命令: | |
| 基础正则 | ^ $ . * .* [] [^] | grep/sed/awk |
| 扩展正则 | | + () ? {} | egrep/sed -r/awk |
2. 三剑客特点及其适用场景:
| 命令 | 特点 | 场景 |
| grep | 过滤 | grep命令过滤速度是最快的 |
| sed | 替换,修改文件内容,取行 | 如果要进行替换/修改文件内容 取出某个范围的内容(日志中具体从几点到几点的) |
| awk | 取列,统计计算 | 取列 对比,比较 统计,计算(awk数组) |
3. 三剑客——grep
(1)选项及含义:
| 选项: | 含义: |
| --color=auto | 对匹配到的文本着色后高亮显示 |
| -i | 忽略字符的大小写 |
| -o | 仅显示匹配到的字符串本身 |
| -v | 显示不能被模式匹配到的行;取反 |
| -c | 统计出现了多少行,类似于wc -l |
| -n | 显示行号 |
| -w | 精确匹配整个单词 |
| -E | =egrep;支持扩展正则:遇到 | + ?(){} |
| -A | -A5:匹配你想要的内容后并且显示接下来的5行 |
| -B | -B5:匹配你想要的内容后并且显示接上面的5行 |
| -C | -C5:匹配你想要的内容后并且显示接上下的5行 |
(2)应用案例:
1)显示/etc/passwd文件中不以/bin/bash结尾的行:
[root@WWcentos ~]# grep -v "/bin/bash$" /etc/passwd2)找出/etc/passwd文件中的两位数或三位数:
[root@WWcentos ~]# grep -E "[0-9]{2,3}" /etc/passwd或者:
[root@WWcentos ~]# grep "\<[0-9]\{2,3\}" /etc/passwd3)找出/etc/rc.d/rc.sysinit或者/etc/grub2.cfg文件中,以至少一个空白字符开头,且后面非空白的行:
[root@WWcentos ~]# grep "^[[:space:]]\+[^[:space:]]" /etc/grub2.cfg4)找出"netstat -tan" 命令中的以'LISTEN'后跟0,1或多个空白字符结尾的行:
[root@WWcentos ~]# netstat -tan |grep "LISTEN[[:space:]]*$"5)找出/proc/meminfo文件中,所有以大写或小写s开头的行,至少三种方式:
[root@WWcentos ~]# grep -i '^s' /proc/meminfo[root@WWcentos ~]# grep -E "^(s|S)" /proc/meminfo[root@WWcentos ~]# grep "^[sS]" /proc/meminfo6)显示当前系统上root,centos,或者user1用户的信息:
[root@WWcentos ~]# grep -E "^(root|centos|user1)\>" /etc/passwd4. 三剑客——sed
(1)sed用法:sed [OPTION] {sed - commands} [input-file]
sed 选项 sed 内置命令符 输入文件
常用选项:
| 选项: | 含义: |
| -n | 输出模式空间的内容至屏幕; 取消默认sed的输出,常与sed内置命令符p一起使用 |
| -e | 多次编辑,不需要管道符 |
| -f | 每行一个编辑命令 |
| -r | 支持使用扩展正则表达式 |
| -i | 直接编辑原文件;直接将修改结果写入文件;不用-i,sed修改的是内部数据 |
sed匹配范围(地址定界):
| 范围: | 含义: |
| 空地址 | 对全文进行处理 |
| 单地址 | #:指定行 /pattern/:被此模式所匹配到的每一行 |
| 地址范围 | #,#p:第#行到第#行 #,+#p:第#行到向下的#行 $p:最后一行 |
| 步进:~ | 1~2:所有奇数行1 3 5 7 ... 2~2:所有偶数行2 4 6 8 ... |
sed命令核心功能:增删改查:
| 编辑命令 | 含义: |
| d | 删除匹配行 |
| p | 显示模式空间中的内容;打印匹配到的行,通常与 -n 一起使用 |
| a \text | 在行后追加文本“text”,支持使用 \n 实现多行追加 |
| i \text | 在行前插入文本“text”,支持使用 \n 实现多行插入 |
| c \text | 把匹配到的行替换为此处指定的文本“text” |
| w /PATH/TO/SOMEFILE | 保存模式空间匹配到的行至指定的文件中 |
| r /PATH/FROM/SOMEFILE | 读取指定文件的内容至当前文件被模式匹配到的行后面;文件合并 |
| = | 为模式匹配到的行打印行号 |
| ! | 条件取反 |
| s/// | 查找替换; 替换标记:g:全局替换 |
(2)sed命令执行过程: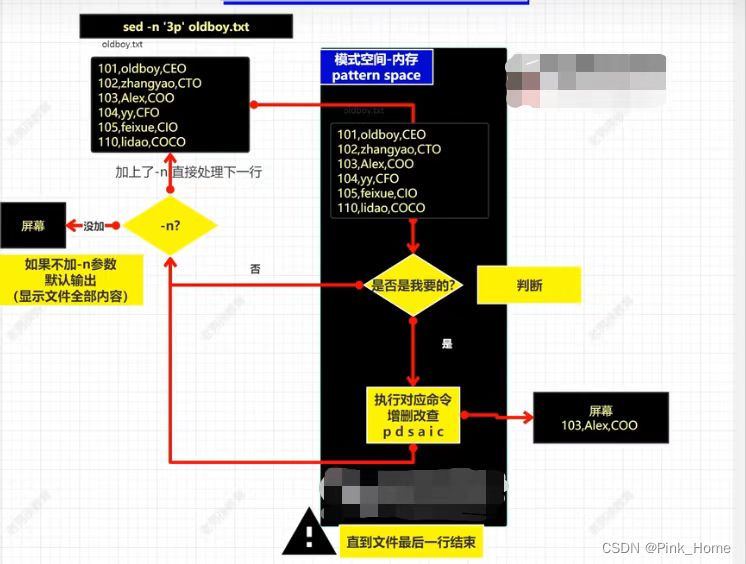
(3)sed核心应用:
1)sed——查找p(与选项-n一起使用)
| 查找格式: | 含义: |
| '2p' | 指定行号进行查找 |
| '1,5p' | 指定行号范围进行查找 |
| '/lidao/p' | 类似于grep过滤,//里面可以写正则 |
| '/10:00:00/,/11:00:00/p' | 表示范围的过滤; (一般用于日志中,时间范围的过滤); 表示范围过滤的时候,如果结尾的内容匹配不到,则一直显示到最后一行 |
·实际生产环境日志统计:
ll -h access.log #查看日志的大小
别用cat/vim #一般都很大,很占内存
可以head/tail/less/more/sed/grep/awk2)sed——删除(无需选项-n)
使用方法与查找的方法一致,即:
'#d' 指定删除#行删除
·企业案例:删除文件中的空行和包含的#号的行
egrep -v "^$|#" /etc/ssh/ssh_config
sed -r '/^$|#/d' /etc/ssh/ssh_config
!的妙用(find/awk/sed命令中取反:)
sed -nr '/^$|#/!p' /etc/ssh/ssh_config3)sed——增加
| 命令: | 含义: |
| a | append 追加,向指定的行或每一行追加内容(行下面) |
| i | insert 插入,向指定的行或每一行插入内容(行上面) |
| c | replace 替代这行内容 |
·企业案例:向文件中追加内容
例子:向文件里面追加内容:
向config里面追加以下内容:
UseDNS no
GSSAPIAUTCATION no
PermitRootLogin no
#方法一:cat
cat >>config<<'EOF'
UseDNS no
GSSAPIAUTCATION no
PermitRootLogin no
EOF
#方法二:sed
sed '$a UseDNS no\n GSSAPIAUTCATION no\n PermitRootLogin no' config
(注意:\n的含义为enter,表示下一行)4)sed——替换s
·s——sub 替换。(sed默认只替换每行的第一个匹配到的内容)
·g——global 全局替换,sed替换每行所有匹配到的内容。
| 替换格式 | 含义 |
| 's#old#new#g' | 将全文中每行的old替换成new |
| s///g s@@@g | 都可表示 |
5)后向引用,反向引用:
口诀:先保护,再使用
例如:
[root@WWcentos ~]# echo 123456 输出123456到终端
123456
[root@WWcentos ~]# echo 123456 |sed -r 's#(.*)#<\1>#g' 将123456加上<>
<123456>
注意:(.*)是将123456这一部分内容使用正则匹配后保护起来,当作一个整体。\1是指前面()内匹配到的内容 练习题:
(1)echo oldboy_newgirl
通过sed后向引用,显示为newgirl_oldboy:
(1)echo oldboy_newgirl
通过sed后向引用,显示为newgirl_oldboy:
[root@WWcentos ~]# echo oldboy_newgirl
oldboy_newgirl
方法一:
[root@WWcentos ~]# echo oldboy_newgirl |sed -r 's#(.*)_(.*)#\2_\1#g'
newgirl_oldboy
方法二:
[root@WWcentos ~]# echo oldboy_newgirl |sed -r 's#(^.*)_(.*$)#\2_\1#g'
newgirl_oldboy
方法三:
[root@WWcentos ~]# echo oldboy_newgirl |sed -r 's#(^[a-z]+)_([a-z]+$)#\2_\1#g'
newgirl_oldboy
方法四:特殊正则符号:perl正则:\w 指[0-9a-zA-Z_]这些内容
[root@WWcentos ~]# echo oldboy_newgirl |sed -r 's#(^\w+)_(\w+$)#\2_\1#g'
newgirl_oldboy
(2)ip a 通过反向引用取出ens33的网卡ip
(2)ip a 通过反向引用取出ens33的网卡ip
方法一:
[root@WWcentos ~]# ip a show ens33 |sed -n '3p' |sed -r 's#(^.*inet )(.*)(/.*$)#\2#g'
192.168.137.128
方法二:
[root@WWcentos ~]# ip a show ens33 |sed -n '3p' |sed -r 's#^.*inet (.*)/.*$#\1#g'
192.168.137.128
精简:
[root@WWcentos ~]# ip a show ens33 |sed -nr '3s#^.*inet (.*)/.*$#\1#gp'
192.168.137.128
图解:
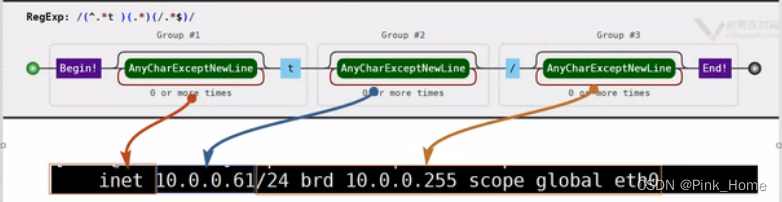
(3)stat /etc/hosts取出权限644
(3)stat /etc/hosts取出权限644:
[root@WWcentos ~]# stat /etc/hosts |sed -n '4p' |sed -r 's#(^.*\(0)(.*)(/-.*$)#\2#g'
644
[root@WWcentos ~]# stat /etc/hosts |sed -n '4p' |sed -r 's#^.*\(0(.*)/-.*$#\1#g'
644
精简:
[root@WWcentos ~]# stat /etc/hosts |sed -nr '4s#^.*\(0(.*)/-.*$#\1#gp'
644
注意:在达到想要的结果时,先看看这个命令帮助,别急着使用管道。
比如:想达到上述预期的效果:
[root@WWcentos ~]# man stat
-c --format=FORMAT
use the specified FORMAT instead of the default; output a newline after each use of FORMAT
#-c 格式
使用指定格式而不是默认格式;每次使用格式后输出换行符
%a access rights in octal
# %a %八进制中的访问权限
此时解决方法:
[root@WWcentos ~]# stat -c%a /etc/hosts
644
5. 三剑客——awk:
awk 是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入、一个或多个文件, 或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它 在命令行中使用,但更多是作为脚本来使用。
(1)awk语法格式:awk [OPTIONS] 'commands [action]' filenames
awk可选参数 + 模式[动作] + 文件
注意:action指的是动作,awk擅长文本格式化,且输出格式化后的结果,因此最常用的动作就是print
#OPTIONS:(选项)
| 选项: | 含义: |
| -F | 定义输入字段分隔符,默认的分隔符是空格或制表符(tab) |
| -v | 定义或修改一个awk内部的变量 |
| -f | 从脚本文件中读取awk命令 |
#command:
| BEGIN{} | {} | END{} |
| 行处理前 | 行处理 | 行处理后 |
注意:awk默认以空格为分隔符,且多个空格也识别为一个空格,作为分隔符。
例如:没有使用参数和模式
[root@WWcentos ~]# awk 'BEGIN {print "name"}'
name[root@WWcentos home]# cat awk.txt
northwest NW Charles Main 4.0 .99 3 35
western WE Sharon Gray 8.3 .97 5 23
southwest SW Lewis Dalsass 4.7 .8 2 19
southern SO Suan Chin 5.1 .96 4 15
southeast SE Patricia Hemenway 4.0 .7 4 16
eastern EA TB Savage 7.7 .84 5 22
northeast NE AM Main Jr. 5.1 .96 3 13
north NO Margot Weber 3.4 .87 5 8
[root@WWcentos home]# awk '{print $2}' awk.txt
NW
WE
SW
SO
SE
EA
NE
NO#awk内置变量:
| 内置变量 | 含义 |
| NR | 记录好,行号 |
| NF | 每行有多个字段(列);$NF表示最后一列 |
| FS | 字段分隔符,每个字段结束标记 |
| OFS | 输出字段分隔符(awk显示每一列的时候,每一列之间通过什么分割,默认是空格) |
(2)awk取行:
| NR==1 | 取出第一行 |
| NR>=1 && NR<=5 | 范围;取出第一行到第五行 |
| /指定字符串/ | |
| /指定字符串/,/到指定字符串/ |
注意:符号可使用: > < >= <= == !=
(3)awk取列:
· -F 指定分隔符,指定每一行结束标记(默认是空格,连续的空格-tab键)
· $数字,指取出某一列
· $0,指取出整行的内容
· $NF,指取出最后一列
(4)awk命令执行过程:
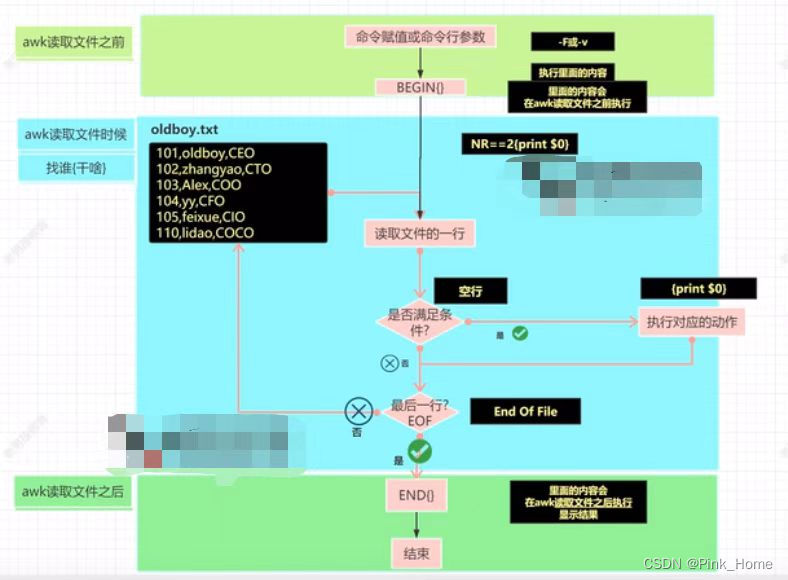
(5)awk模式匹配:
| awk | -F"[ /]+" | 'NR==3{print $3}' |
| 命令 | 选项 | '模式{动作}' |
1)正则:
· //支持扩展正则
· awk可以精确到某一列,某一列中包含或者不包含具体内容
· ~表示包含
· !~表示不包含
| 正则 | awk 正则 |
| ^ 表示以...开头的行 | ^ 表示某一列的开头 例: $1~/^ro/ |
| $ 表示以...结尾的行 | $ 表示某一列的结尾 例:$1~/ot$/ |
| ^$ 表示空行 | ^$ 表示某一列是空的 |
例如:找出/etc/passwd文件中第四列以1开头的行
[root@work ~]# awk -F: '$4~/^1/' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin2)表示范围:
· /开始/,/结束/ 表示从哪里开始,到哪里结束
· NR==1,NR==5 表示从第一行开始到第五行结束
例如:显示日志中指定范围内容的ip地址:
awk '/11:00:00/,/11:00:30/{print $1}' access.log3)特殊模式BEGIN{}和END{}
| 模式 | 含义 | 应用场景 |
| BEGIN{} | {}里面的内容会在awk读取文件之前执行。 | 1)进行简单统计,计算;不涉及读取文件 2)用来处理文件之前,列的前面添加个表头 |
| END{} | {}里面的内容会在awk读取文件之后执行。 | 1)awk进行统计的一般过程:先进性计算,最后END里面输出结果 2)awk使用数组,用来输出数组结果 |
· END{}统计计算:
| 统计方法 | awk简写形式 | 应用场景 |
| i=i+1 | i++ | 计数;统计次数 |
| sum=sum+??? | sum+=??? | 求和;累加 |
| a[]=a[]+1 | a[]++ | 数组分类计数 |
| 注意:i sum 都是变量 | ||
例子:统计/etc/service文件中的空行数目
[root@work ~]# awk '/^$/{i++}END{print i}' /etc/services
17例子:从1加到10
[root@work ~]# seq 10 |awk '{sum=sum+$0}END{print sum}'
55
[root@work ~]# seq 10
1
2
3
4
5
6
7
8
9
10例子:加的过程:
[root@work ~]# seq 10 |awk '{sum=sum+$0;print sum}END{print sum}'
1
3
6
10
15
21
28
36
45
55
55(6)awk数组:
一般应用于统计日志文件中:·统计次数:统计每个ip出现次数,统计每种状态码出现次数,统计系统中每个用户被攻击次数,统计攻击者ip出现次数。 ·累加求和:统计每个ip消耗的流量。
| awk数组 | |
| 形式 | a[0]=oldboy a[1]=hello |
| 使用 | print a[0] print a[1] |
| 批量输出数组内容 | for( i in a ) print a[i] |
| 注意:awk数组专用循环,变量获取到的是数组的下标,你想要的数组内容是 a[i] | |
例子:
#awk加字母时,会被识别为变量,如果只是想使用字符串需要使用双引号引起来。
[root@work ~]# awk 'BEGIN{a[0]="oldboy";a[1]="hello";print a[0],a[1]}'
oldboy hello#awk数组专用循环:
[root@work ~]# awk 'BEGIN{a[0]="oldboy";a[1]="hello";for(i in a)print i}'
0
1[root@work ~]# awk 'BEGIN{a[0]="oldboy";a[1]="hello";for(i in a)print a[i]}'
oldboy
hello
[root@work ~]# awk 'BEGIN{a[0]="oldboy";a[1]="hello";for(i in a)print i, a[i]}'
0 oldboy
1 hello经典案例:
处理以下文件内容,将域名取出来并统计排序处理:
httpd://www.etiantian.org/index.html
httpd://www.etiantian.org/1.html
httpd://post.etiantian.org/index.html
httpd://mp3.etiantian.org/index.html
httpd://www.etiantian.org/3.html
httpd://post.etiantian.org/2.html[root@work ~]# awk -F"[///]+" '{a[$2]++}END{for(i in a)print i,a[i]}' test.txt
mp3.uplooking.com 1
www.uplooking.com 3
post.uplooking.com 2总结:a[]++ 统计什么,[]里面就是什么(某一列)
比如:统计access.log文件中ip出现次数,即a[$1]++

















 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









