






 本文深入解析Spark工作原理,涵盖Job、Stage和Task的关系,以及Executor的角色。重点讲解了Spark任务拆分策略和资源调度,还介绍了org.apache.spark.SparkException的解决方法。此外,讨论了Spark运行角色和配置,以及常见错误案例分析。
本文深入解析Spark工作原理,涵盖Job、Stage和Task的关系,以及Executor的角色。重点讲解了Spark任务拆分策略和资源调度,还介绍了org.apache.spark.SparkException的解决方法。此外,讨论了Spark运行角色和配置,以及常见错误案例分析。
一、spark原理
参考:
Hive on Spark调优_窗外的屋檐-优快云博客_spark.executor.instancesSpark资源参数调优参数_TURING.DT-优快云博客_spark 资源参数
1、Job——对应action算子:
包含很多task的并行计算,可以认为是Spark RDD 里面的action,每个action的计算会生成一个job。
用户提交的Job会提交给DAGScheduler,Job会被分解成Stage和Task。
2、Stage——对应Shuffle过程:
一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage, Reduce Stage。
Stage的划分在RDD的论文中有详细的介绍,简单的说是以shuffle和result这两种类型来划分。在Spark中有两类task,一类是shuffleMapTask,一类是resultTask,第一类task的输出是shuffle所需数据【Map阶段】,第二类task的输出是result【Reduce阶段】,stage的划分也以此为依据,shuffle之前的所有变换是一个stage,shuffle之后的操作是另一个stage。
3、Task——对应一个rdd有多少个partition:
即 stage 下的一个任务执行单元,一般来说,一个 rdd 有多少个 partition,就会有多少个 task,因为每一个 task 只是处理一个 partition 上的数据.
4、Executor:
Executor是一个执行Task的容器,应用程序运行的监控和执行容器
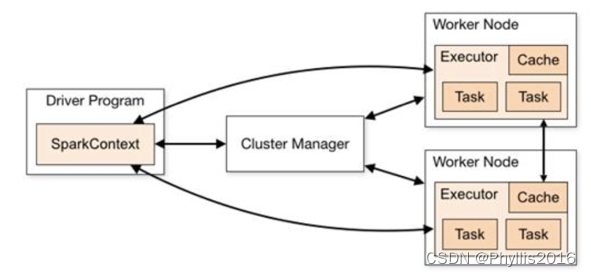
1)一个spark任务需要拆分成多个job,一个job拆分成多个步骤Stage完成,一个Stage包含不同的Task【job是一个完成的mapreduce的概念的抽象,Task是每一个阶段的具体的实例,比如maptask和reducetask】
2)然后每个步骤里的具体任务Task要分配到不同的executor完成,分配的主要原则就是适合的任务分配到适合的excutor,即数据本地化处理
3)drive跟踪exector执行情况
整个过程中,部门领导就起到了driver的作用,不同的组起到了executor的作用,组内的每个成员就是cpu和memory的结合负责就是执行task
二、常见错误和解决方法
org.apache.spark.SparkException: Could not execute broadcast in 1500 secs. You can increase the timeout for broadcasts via spark.sql.broadcastTimeout or spark.sql.broadcastMaxRetries or disable broadcast join by setting spark.sql.autoBroadcastJoinThreshold to -1
它的主要职责是:
1、初始化程序要执行的上下文SparkEnv,解决应用程序需要运行时的jar包的依赖,加载类。
2、同时还有一个ExecutorBackend向cluster manager汇报当前的任务状态,这一方面有点类似hadoop的tasktracker和task。
总结:
Spark application的运行单元是task,资源分配单元是executor。task数的多少是和RDD的分区数相关的,整个application的并行度是 Executor数 * Task
三、一些概念
1、spark运行角色:
Master:集群资源管理(ResourceManager)
Worker:单机资源管理(NodeManager)
Driver:单任务管理者(ApplicationMaster)
Executor:单任务执行者(yarn容器里的task)
2、SparkConf、SparkContext、SparkContext区别:
任何Spark程序都是从SparkContext开始的,SparkContext的初始化需要一个SparkConf对象,SparkConf包含了Spark集群配置的各种参数. 初始化后,就可以使用SparkContext对象所包含的各种方法来创建和操作RDD的共享变量.
1)使用:
val conf = new SparkConf()
.setMaster("master")
.setAppName("appName")
val sc = new SparkContext(conf)
或者
val sc = new SparkContext("master","appName")
2)SparkSession实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext),所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的.
SparkSession内部封装了SparkContext,所以计算实际上是由SparkContext完成的.
spark = (SparkSession
.builder
.appName("causal-test-DockerLinuxContainer")
.enableHiveSupport()
.config("spark.executor.instances", "200")
.getOrCreate())
spark.sql(""""")
四、常见错误
1、Job aborted due to stage failure: Total size of serialized results of 3979 tasks (1024.2 MB) is bigger than spark.driver.maxResultSize (1024.0 MB)
锁定了是spark.driver.maxResultSize引起的,该参数控制worker送回driver的数据大小,一旦操过该限制,driver会终止执行。所以,我加大了该参数,结果执行成功。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









