




 当面临大文件无法一次性加载到内存时,可以利用pandas的read_csv函数配合chunkSize参数进行分块读取。通过设置chunkSize或iterator=True,返回可迭代的TextFileReader对象,实现大文件的逐块处理。
当面临大文件无法一次性加载到内存时,可以利用pandas的read_csv函数配合chunkSize参数进行分块读取。通过设置chunkSize或iterator=True,返回可迭代的TextFileReader对象,实现大文件的逐块处理。
最近,下载了一个csv结构的数据集,有1.2G。对该文件试图用pd.read_csv进行读取的时候,发现出现内存不足的情况

,电脑内存不足,不能一次性的读取。此时我们就需要对csv文件进行分块读取。
在对数据进行分块读取之前,我们需要对pd.read_csv()中的参数进行一定的了解,pandas.read_csv()官方文档。如果英文看不懂的可以去网上找一下别人翻译出来的。
在官方文档中,read_csv()函数有一个chunkSize参数,通过指定一个chunk Size分块大小来读取文件,返回的是一个可迭代的对象Text FileReader
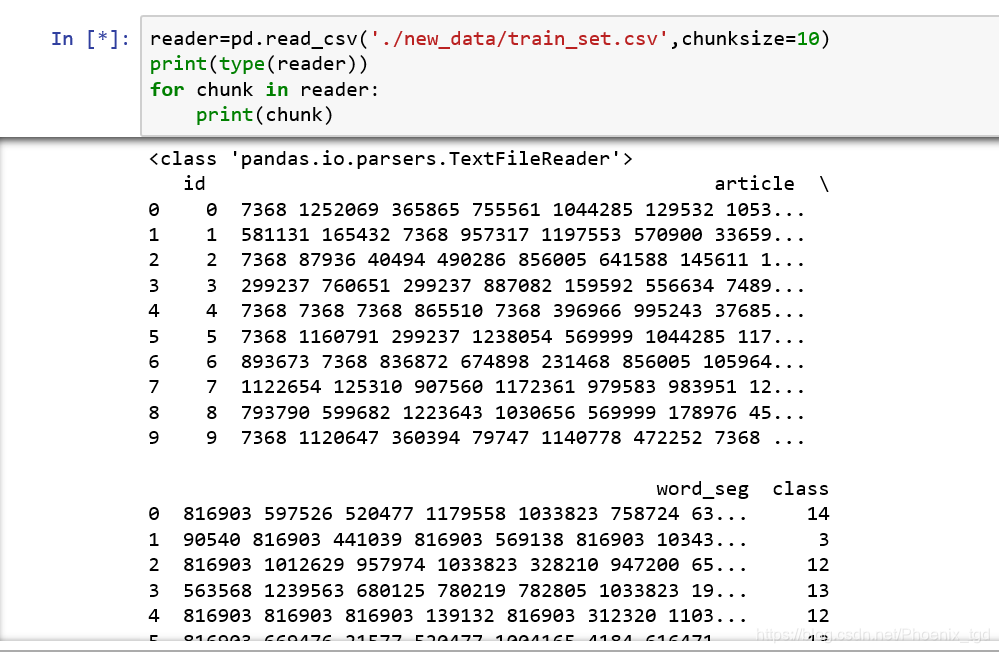
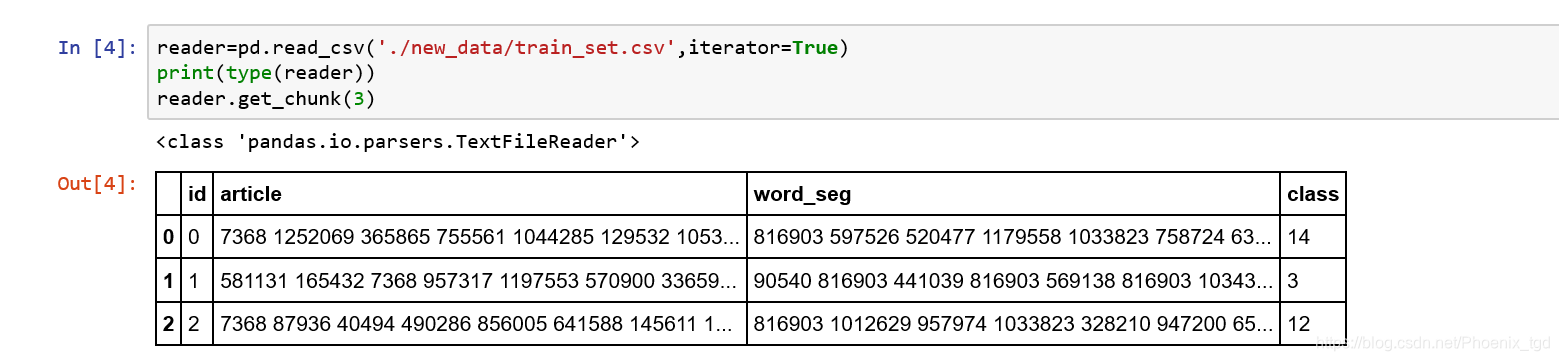
当我们指定read_csv()中的iterator参数为True时,也可以返回一个可以迭代的对象TextFileReader。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









