




 本文介绍了Python爬虫的基础知识,包括网页、URL和网页源代码的概念,以及爬取网页的简单和详细思路。通过两个代码示例展示了如何爬取数据,分别是从目标URL直接获取和通过其他URL返回的数据。讲解了使用requests和lxml库进行网络数据获取和HTML解析。此外,还强调了开发者工具在网络爬虫中的重要作用。
本文介绍了Python爬虫的基础知识,包括网页、URL和网页源代码的概念,以及爬取网页的简单和详细思路。通过两个代码示例展示了如何爬取数据,分别是从目标URL直接获取和通过其他URL返回的数据。讲解了使用requests和lxml库进行网络数据获取和HTML解析。此外,还强调了开发者工具在网络爬虫中的重要作用。
使用Python爬取一个网页并解析
1. 爬虫准备
1.1. Python基础语法
首先,当你看到这篇文章的时候,我们假定你本身了解Python的基础语法以及熟悉如何安装Python第三方库。在这个基础上,我们就可以继续往下看啦。
1.2. 爬取一个网页的整体思路
1.2.1. 基础概念
网页:网页是构成网站的基本元素,是承载各种网站应用的平台.
例:百度首页
URL:在WWW上,每一信息资源都有统一的且在网上唯一的地址.
例:百度首页
https://www.baidu.com/
网页源代码:一个网页的HTML文件内容。
例:谷歌浏览器打开百度首页,右键,查看网页源代码
调试模式:谷歌浏览器自带的开发者工具。
例:百度首页
PS:这里关于开发者工具的操作不多展开。
1.2.2. 简单思路
- 打开一个具体的网页
- 编写代码访问这个网页并返回数据
- 解析自己想要的数据
很多时候我们会发现爬虫有时候并不是那么顺利,有时候需要加入很多细节,但整体思路都不会离开这三个步骤。显然这远远不够,因此需要更加详细的步骤
1.2.3. 详细思路
- 打开一个具体的网页
- 查看网页的源代码并查找(CTRL+F)自己所要找的数据是否在网页中。
2.1. 如果有,这时候打开开发者模式,点击network,刷新。这个时候你会发现你所需要的数据刚好在第一个网址返回。如下
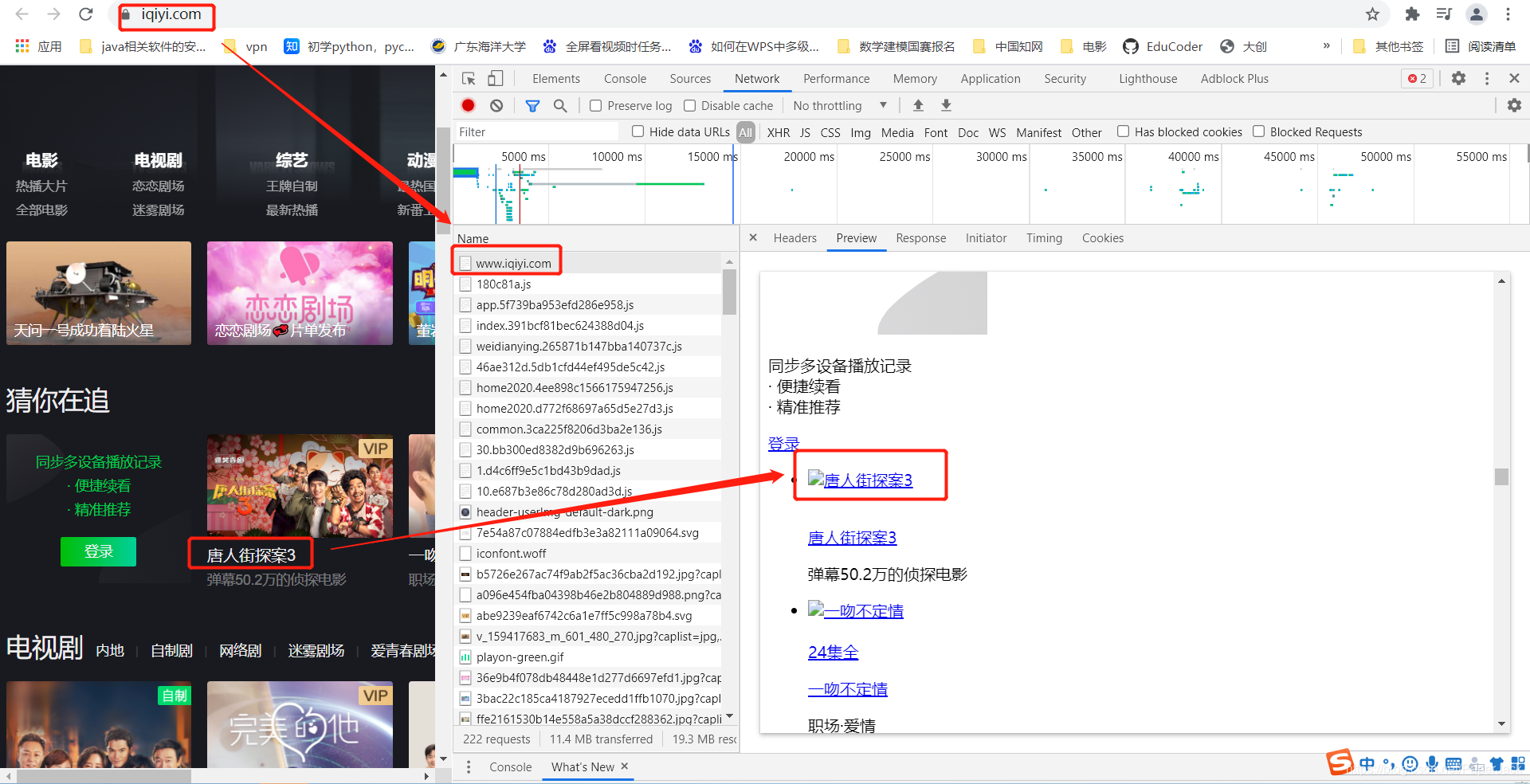
最后编写代码爬取网页并使用xpath解析
2.2. 如果没有,这时候需要打开开发者模式,点击network,刷新。这个时候你会发现并不能像2.1里面一样,在第一个网站中就返回数据。这个时候数据是藏在其他的js等文件中。(这里需要一点前端开发的基础)。我们需要找到数据存在哪个链接中,而查找的方法很多时候是手动以及根据经验筛选,可以优先先筛选XHR数据。如图:
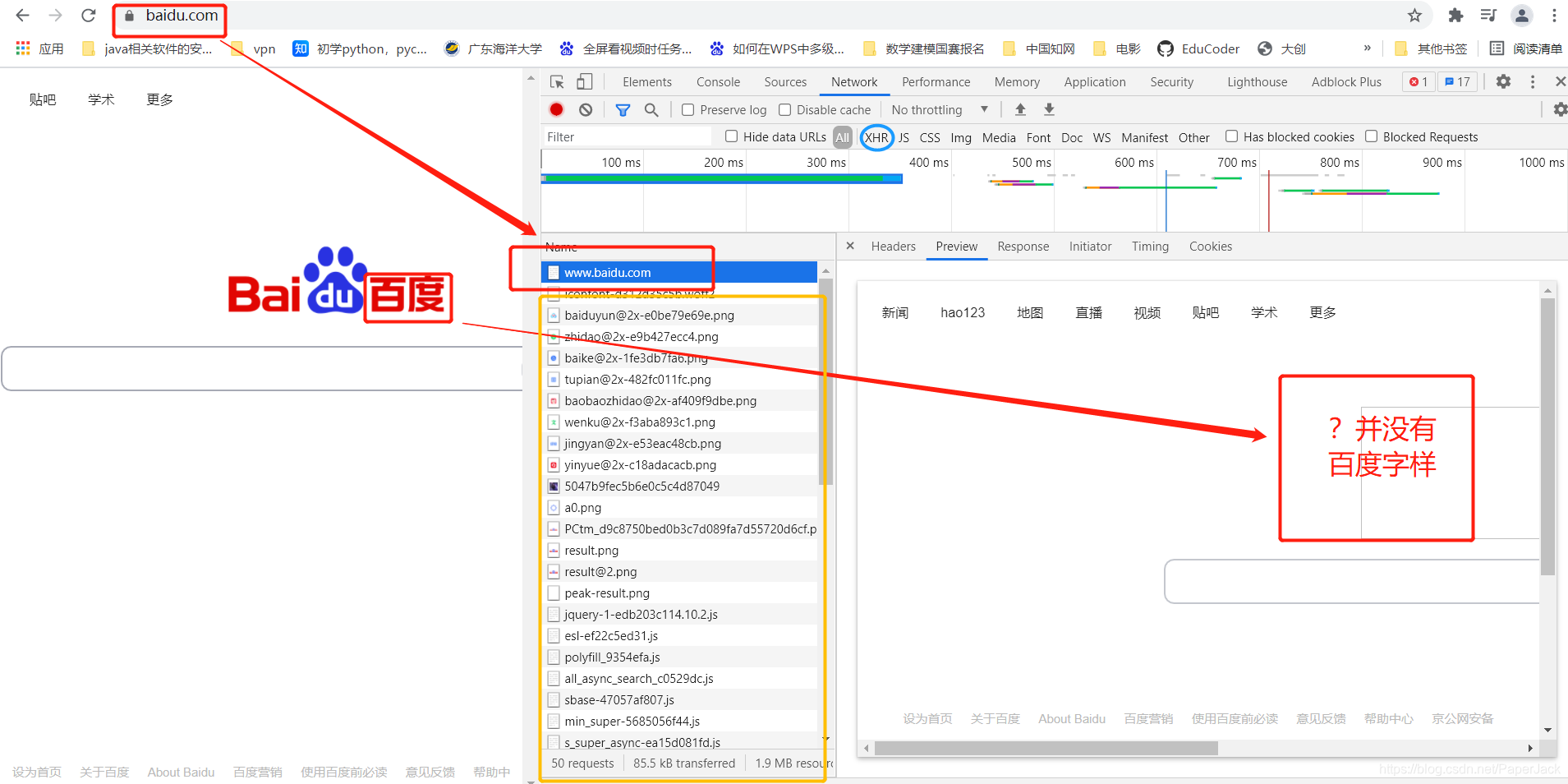
通过上面那个案例,我们筛选到百度首页的“百度”字样如图:
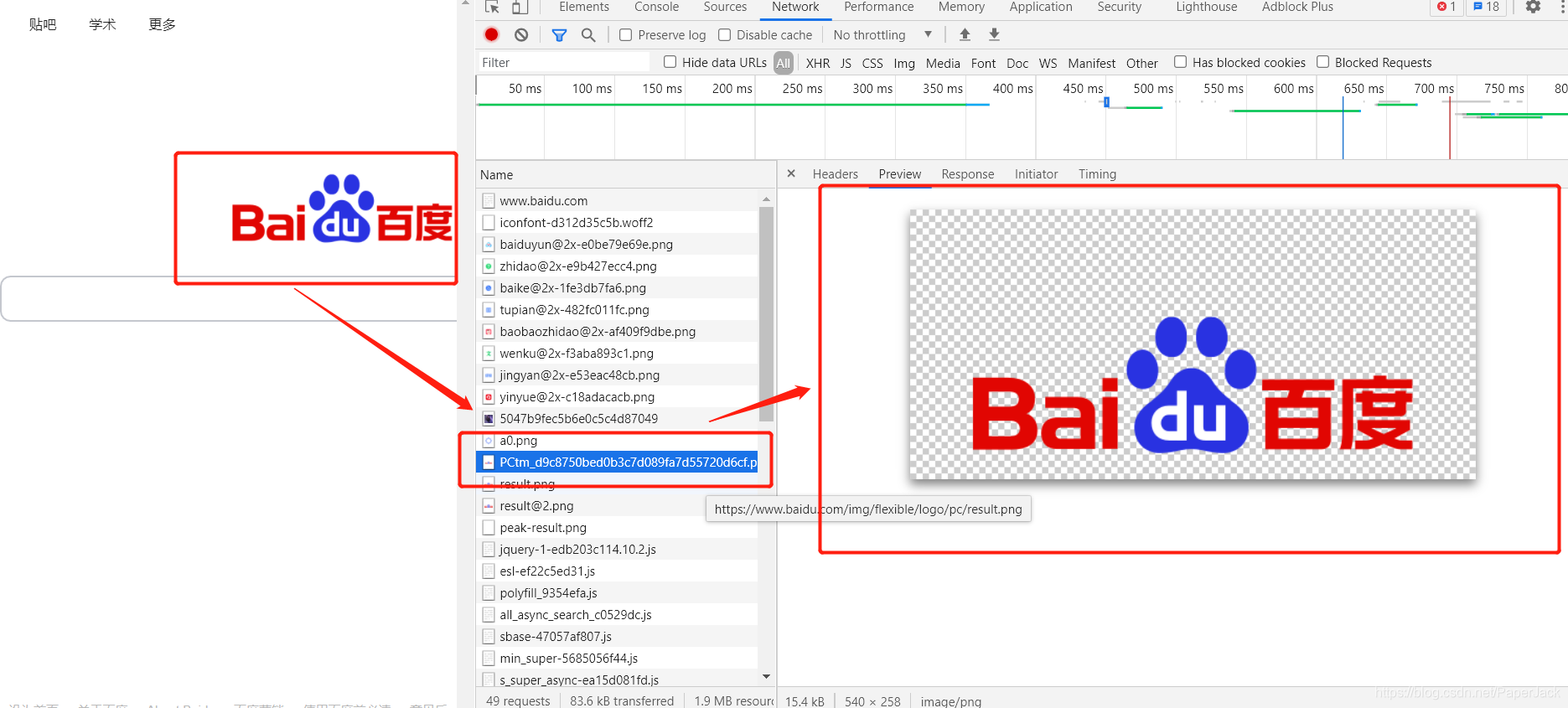
最后编写代码爬取网页并使用json解析(多数情况下)
1.3. 需要安装的第三方库
requests: 获取网络数据
lxml: 解析html等格式文件的数据
2. 代码示例
2.1. 数据在目标url中
Demo1:爬取bilibili热门信息
from lxml import etree
import requests
# 要爬取的url,注意:在开发者工具中,这个url指的是第一个url
url = "https://www.bilibili.com/v/popular/rank/all"
# 模仿浏览器的headers
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36"
}
# get请求,传入参数,返回结果集
resp = requests.get(url,headers=headers)
# 将结果集的文本转化为树的结构
tree = etree.HTML(resp.text)
# 定义列表存储所有数据
dli = [ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











