




爬取喜马拉雅
- 网址喜马拉雅
- 查看播放音频时的网络请求
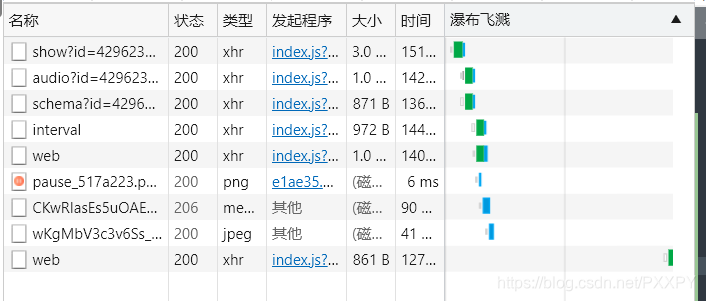
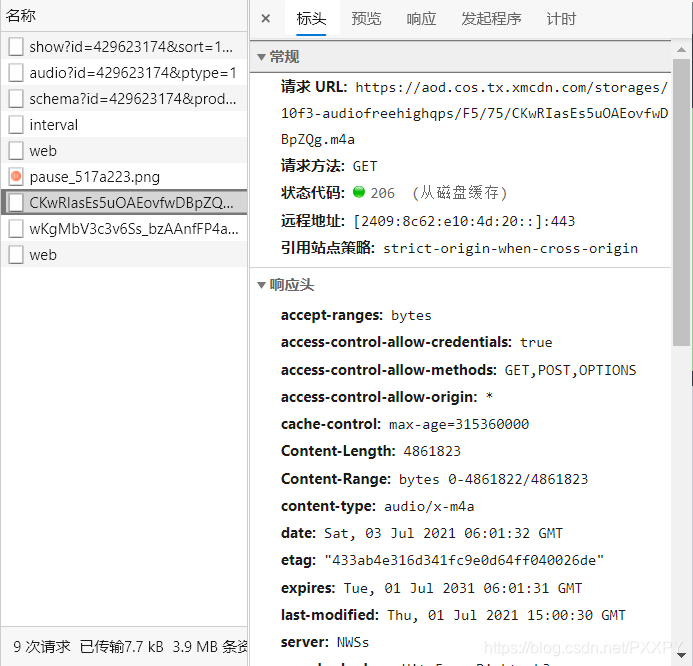
如图所示的请求便是音频信息
- 寻找音频信息url来源
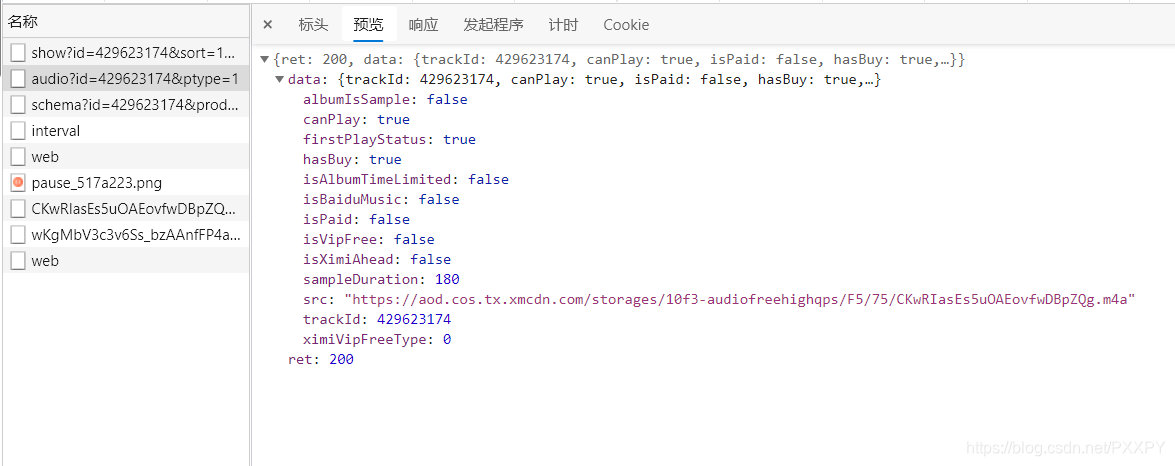
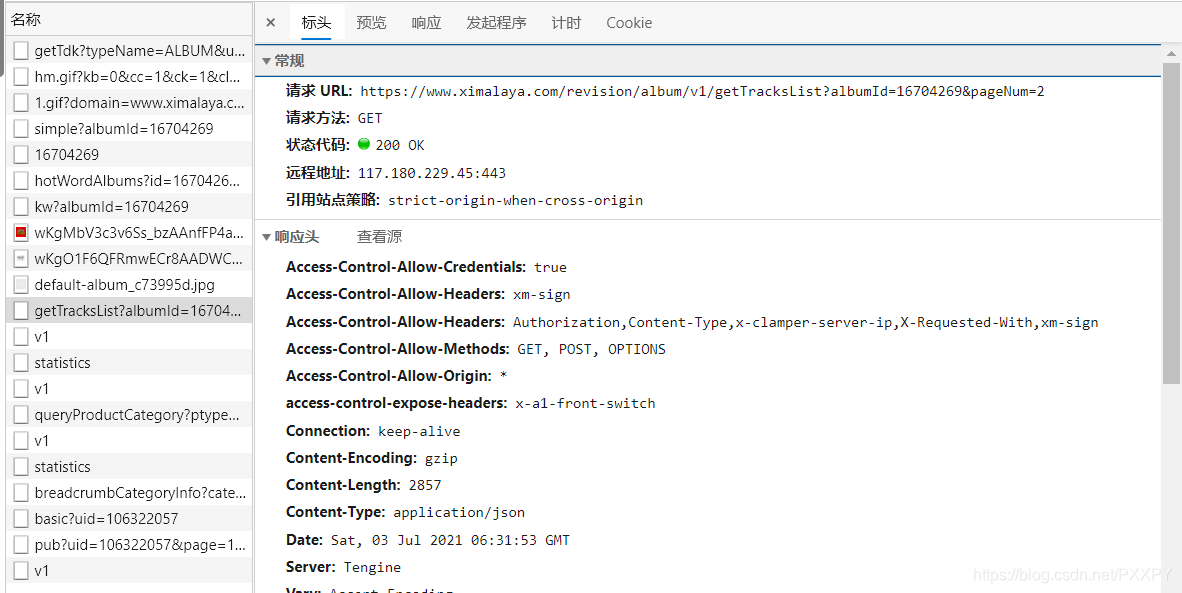
如图所示便是请求获取音频url的请求网址
浏览器单独访问会发现:

于是添加上xm-sign和user-agent发送请求

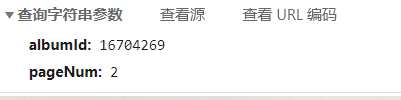
观察url发现带有2个信息id和ptype

ptype必须要的,id便是音频的ID
到了此刻问题转化为了如何寻找目标音频的ID
- 寻找ID
确认信息位于源码中

显然在庞大杂乱无章的源码中去找还是有点麻烦
找啊找,终于找到了调用的api
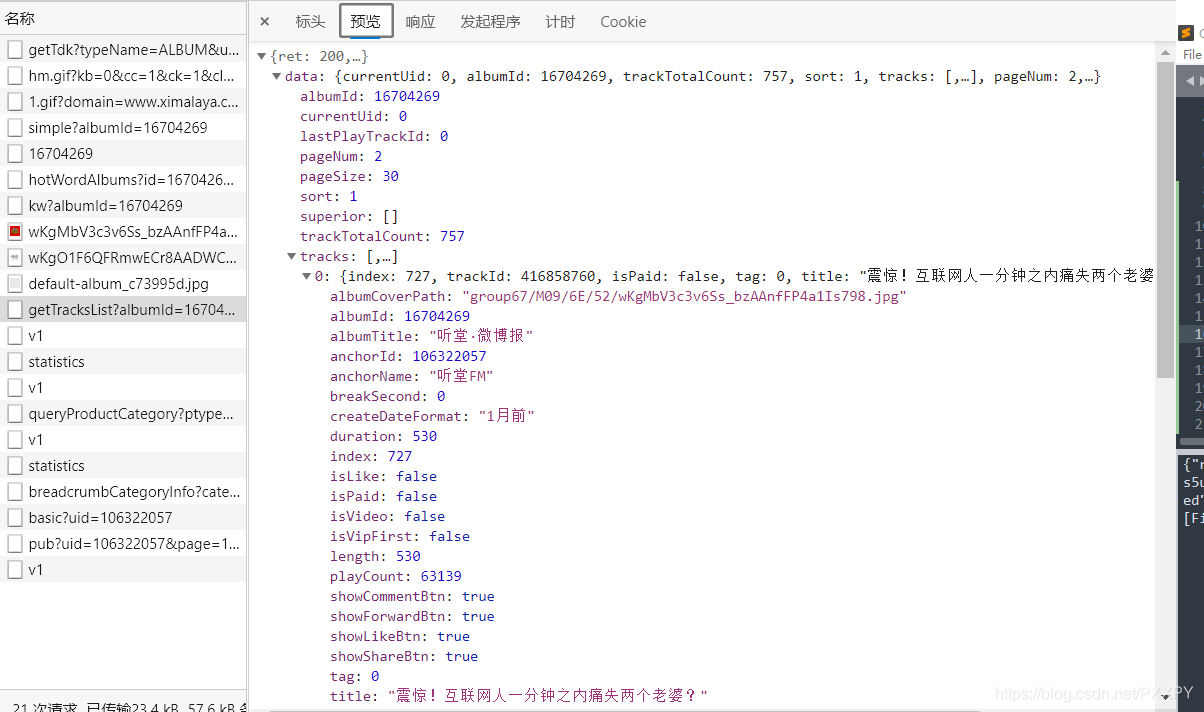
这次便明晓了
- 代码
分析完了,直接上源码
'''
开发者:Anxun
时间:2021-07-03 14:03:23
网站:www.clouded.top
请尊重版权,保留此信息
'''
#print('欢迎使用更多访问:www.clouded.top')
import requests,json,os,time,hashlib,random
'''
https://aod.cos.tx.xmcdn.com/storages/10f3-audiofreehighqps/F5/75/CKwRIasEs5uOAEovfwDBpZQg.m4a
https://aod.cos.tx.xmcdn.com/storages/7313-audiofreehighqps/10/12/CKwRIRwEsk6WAEDdTADBJy9m.m4a
https://aod.cos.tx.xmcdn.com/storages/b15b-audiofreehighqps/AB/22/CKwRIasEsPkuAE8v_ADApeoF.m4a
https://aod.cos.tx.xmcdn.com/storages/dca0-audiofreehighqps/E2/68/CKwRIMAEr6ihAEUpKADAJDwE.m4a
'''
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36"
}
def get_xm_sign():#破解xm-sign加密
global headers
serverTimeUrl = "https://www.ximalaya.com/revision/time"#获取喜马拉雅服务器的时间戳
response = requests.get(serverTimeUrl,headers = headers)
serverTime=response.text
#md5(ximalaya-服务器时间戳)(100以内随机数)服务器时间戳(100以内随机数)现在时间戳
nowTime = str(round(time.time()*1000))
sign = str(hashlib.md5("himalaya-{}".format(serverTime).encode()).hexdigest()) + "({})".format(str(round(random.random()*100))) + serverTime + "({})".format(str(round(random.random()*100))) + nowTime
headers["xm-sign"] = sign# 将xm-sign添加到请求头中
#print(headers)
def get_url(ID,path):#获取下载链接
get_xm_sign()#更新sign
global headers
url='https://www.ximalaya.com/revision/play/v1/audio?id={}&ptype=1'.format(ID)#含有url的json数据
html=requests.get(url,headers=headers).text
#print(html)
html=json.loads(html)#转化为json
url=html["data"]["src"]
print(ID,path,url)
get_aduio(url,path)
def get_aduio(url,path):#下载m4a文件
music = requests.get(url, headers=headers).content
with open(path, 'wb') as f:
f.write(music)
print('下载完成')
def get_IDlist(albumId,pageNum):#获取音频列表
get_xm_sign()#更新sign
global headers
url='https://www.ximalaya.com/revision/album/v1/getTracksList?albumId={}&pageNum={}'.format(albumId,pageNum)#组成url获取列表信息
html=requests.get(url,headers=headers).text
html=json.loads(html)#转化为json
info=html["data"]["tracks"]
title_list=[]#标题列表
trackId_list=[]#id列表
for a in info:
title=a["title"]#获取标题
trackId=a["trackId"]#获取音频ID
title_list.append(title)
trackId_list.append(trackId)
#print(title,trackId)
try:
os.makedirs('./喜马拉雅爬取')#建立存储目录
except:
pass
for path in range(len(title_list)):
ID=trackId_list[path]#id
path=title_list[path]
path='./喜马拉雅爬取/{}.m4a'.format(path)#组成路径
get_url(ID,path)
albumId=16704269#频道ID
pageNum=1#页数
get_IDlist(albumId,pageNum)
#get_url('417171885','./喜马拉雅爬取/扎心了!yyds有了新含义!.m4a')
另外提一下遇到了xm-sign反爬虫
emm
自己操作参考xm-sign反爬虫破解

















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









