







 本文介绍了正则表达式的基本概念、语法,包括普通字符、元字符和修饰符,并详细讲解了JavaScript中的RegExp对象及其方法如test()和exec(),还提及了在HTMLinputpattern属性中的应用。
本文介绍了正则表达式的基本概念、语法,包括普通字符、元字符和修饰符,并详细讲解了JavaScript中的RegExp对象及其方法如test()和exec(),还提及了在HTMLinputpattern属性中的应用。
文章の目录
search() 方法、replace() 方法、split() 方法
正文
正则表达式简介
正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”)。
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式语法
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern)。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为“元字符”)组成的文字模式。
模式描述在搜索文本时要匹配的一个或多个字符串。
正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
模式
普通字符
普通字符包括没有显式指定为元字符的所有字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
元字符
\
将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。
例如:"n" 匹配字符 "n";"\n" 匹配一个换行符。
^
匹配输入字符串的开始位置。
$
匹配输入字符串的结束位置。
*
匹配前面的子表达式零次或多次。
例如:"zo*" 能匹配 "z"、"zo"、"zoo" 等。
* 等价于 {0,}。
+
匹配前面的子表达式一次或多次。
例如:"zo+" 能匹配 "zo"、"zoo" 等,但不能匹配 "z"。
+ 等价于 {1,}。
?
匹配前面的子表达式零次或一次。
例如:"do(es)?" 能匹配 "do" 或 "does"。
? 等价于 {0,1}。
{n}
n 是一个非负整数。匹配确定的 n 次。
例如:"o{2}" 不能匹配 "Bob" 中的 "o",但是能匹配 "food" 中的 "oo"。
{n,}
n 是一个非负整数。至少匹配 n 次。
例如:"o{2,}" 不能匹配 "Bob" 中的 "o",但是能匹配 "fooood" 中的 "oooo"。
{1,} 等价于 +,{0,} 等价于 *。
{n,m}
m 和 n 均为非负整数,其中 n<=m。最少匹配 n 次且最多匹配 m 次。
例如:"o{1,3}" 将匹配 "foooood" 中的前三个 "o"("ooo")。
{0,1} 等价于 ?。
请注意在逗号和两个数之间不能有空格。
?
当该字符紧跟在任何一个其它限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。
非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。
例如:对于字符串"oooo","o+?" 将匹配单个 "o",而 "o+" 将匹配所有 "o"("oooo")。
.
匹配除换行符(\n、\r)之外的任何单个字符。
要匹配包括 "\n" 在内的任何字符,请使用像 "(.|\n)" 的模式。
x|y
匹配 x 或 y。
例如:"z|food" 能匹配 "z" 或 "food"。"(z|f)ood" 则匹配 "zood" 或 "food"。
[xyz]
字符集合。匹配所包含的任意一个字符。
例如:"[abc]" 可以匹配 "plain" 中的 "a"。
[^xyz]
负值字符集合。匹配未包含的任意字符。
例如:"[^abc]" 可以匹配 "plain" 中的 "p"、"l"、"i"、"n"。
[a-z]
字符范围。匹配指定范围内的任意字符。
例如:"[a-z]" 可以匹配 "a" 到 "z" 范围内的任意小写字母字符。
[A-Z]、[0-9] 同理。
[^a-z]
负值字符范围。匹配任何不在指定范围内的任意字符。
例如:"[^a-z]" 可以匹配任何不在 "a" 到 "z" 范围内的任意字符。
\b
匹配一个单词边界,也就是指单词和空格间的位置。
例如:"er\b" 可以匹配 "never" 中的 "er",但不能匹配 "verb" 中的 "er"。
\B
匹配非单词边界。
例如:"er\B" 能匹配 "verb" 中的 "er",但不能匹配 "never" 中的 "er"。
\d
匹配一个数字字符。
等价于 [0-9]。
\D
匹配一个非数字字符。
等价于 [^0-9]。
\w
匹配字母、数字、下划线。
等价于 [A-Za-z0-9_]。
\W
匹配非字母、数字、下划线。
等价于 [^A-Za-z0-9_]。
\s
匹配任何空白字符。包括空格、制表符、换页符等等。
等价于 [\f\n\r\t\v]。
\S
匹配任何非空白字符。
等价于 [^\f\n\r\t\v]。
\xn
匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。
例如:"\x41" 匹配 "A"。
正则表达式中可以使用 ASCII 编码。
\f
匹配一个换页符。
等价于 \x0c。
\n
匹配一个换行符。
等价于 \x0a。
\r
匹配一个回车符。
等价于 \x0d。
\t
匹配一个制表符。
等价于 \x09。
\v
匹配一个垂直制表符。
等价于 \x0b。
修饰符(标记)
标记也称为修饰符,正则表达式的标记用于指定额外的匹配策略。
标记不写在正则表达式里,标记位于表达式之外,格式如下:
/pattern/flags正则表达式常用修饰符

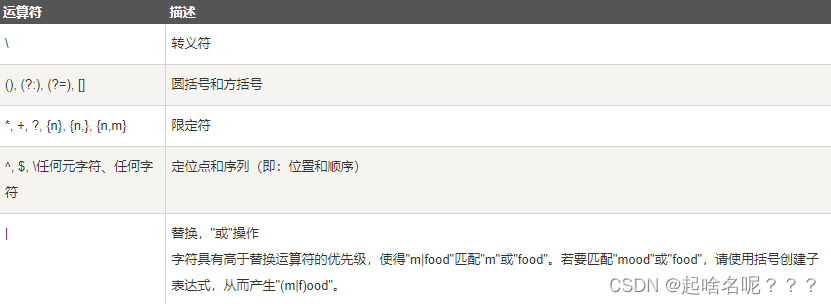
优先级
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常相似。
相同优先级的从左到右进行运算,不同优先级的运算先高后低。
下图从最高到最低说明了各种正则表达式运算符的优先级顺序:
JavaScript RegExp 对象
RegExp:是正则表达式(regular expression)的缩写。
RegExp 对象
正则表达式是描述字符模式的对象。
正则表达式用于对字符串模式匹配及检索替换,是对字符串执行模式匹配的强大工具。
语法
var patt = new RegExp(pattern, modifiers);
// 或者更简单的方式
var patt = /pattern/modifiers;
/*
pattern(模式)描述了表达式的模式
modifiers(修饰符)用于指定全局匹配、区分大小写的匹配和多行匹配
*/RegExp 对象方法
test() 方法
test() 方法用于检测一个字符串是否匹配某个模式。
如果字符串中有匹配的值返回 true,否则返回 false。
语法:
RegExpObject.test(string)
/*
string:必需。要检测的字符串。
*/exec() 方法
exec() 方法用于检索字符串中的正则表达式的匹配。
如果字符串中有匹配的值返回该匹配值,否则返回 null。
语法:
RegExpObject.exec(string)支持正则表达式的 String 对象的方法
search() 方法、replace() 方法、split() 方法
(如需了解这三个字符串方法的用法,请阅读笔者另一篇文章:JS 字符串及字符串方法)
match() 方法
match() 方法可在字符串内检索指定的值,或找到一个或多个正则表达式的匹配。
注:
- match() 方法将检索字符串 String Object,以找到一个或多个与 regexp 匹配的文本。
- 这个方法的行为在很大程度上依赖于 regexp 是否具有标志 g。如果 regexp 没有标志 g,那么 match() 方法就只能在 stringObject 中执行一次匹配。
- 如果没有找到任何匹配的文本,match() 将返回 null。
语法:
string.match(regexp)
/*
regexp:必需。规定要匹配的模式的 RegExp 对象。如果该参数不是 RegExp 对象,则需要首先把它传递给 RegExp 构造函数,将其转换为 RegExp 对象。
返回值:Array。存放匹配结果的数组。该数组的内容依赖于 regexp 是否具有全局标志 g。如果没找到匹配结果返回 null。
*/HTML input pattern 属性
pattern 属性规定用于验证 <input> 元素的值的正则表达式。
注:
- pattern 属性适用于下面的 input 类型:text、search、url、tel、email 和 password。
- pattern 属性是 HTML5 中的新属性。
语法:
<input pattern="regexp">
<!--
regexp:规定用于验证 <input> 元素的值的正则表达式。
-->
















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









