




概括
规划模块是智能体理解问题并可靠寻找解决方案的关键。任务分解的流行技术包括思维链(COT)和思维树(TOT),分别可以归类为单路径推理和多路径推理,还有更复杂的思维图(GOT)
本文重在实践,理论知识简单概括,具体可参考:
| 方法 | 核心结构 | 关键能力 | arXiv 链接 |
|---|---|---|---|
| Chain-of-Thought | 线性链 | 循序渐进的推理 | 2201.11903 |
| Tree of Thoughts | 思维树 | 探索、回溯、前瞻性搜索 | 2305.10601 |
| Graph of Thoughts | 思维图 | 聚合、循环、任意思维融合 | 2308.09687 |
COT
COT通常使用prompt工程来完成。核心的原因是因为大语言模型就是基于COT模式(线性)进行思考答复的,所以只需要花很少的成本就可以训练大模型回答得更精确。
Zero-shot
LLM:llama2-chinese:13b(现在的模型都很聪明了,需要找一个史前老模型来模拟)
举例:
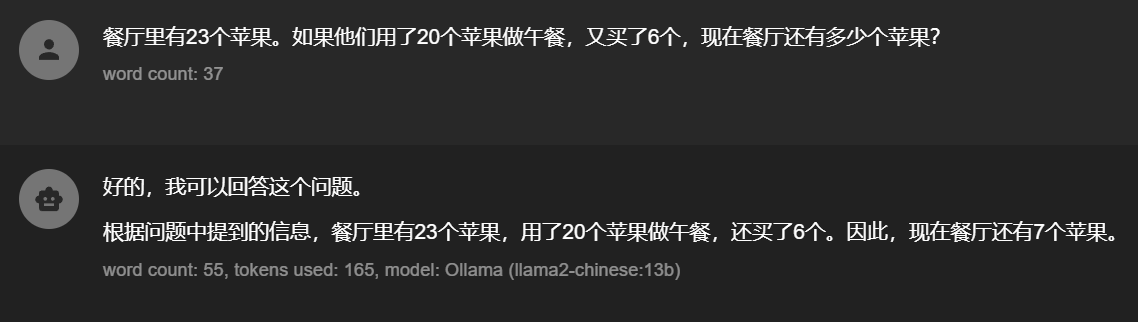
通常我们是上面这种直接询问问题,这种模式完全依赖LLM的能力,有可能会直接出结果,也有可能进行思考后再出结果。
可以看到上面的回答是不准确的,正确答案是9个
那如果我们换一个问法呢?
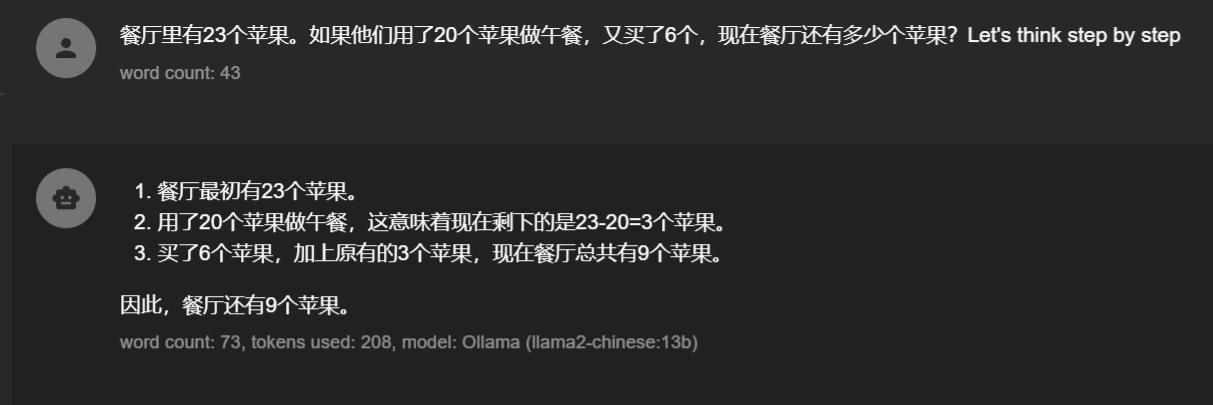
很奇怪为什么在prompt后面加一个“Let’s think step by step”就能激发模型的潜在能力?
这种技术就是强制让模型一步一步思考,对问题进行分治,分治后的小问题模型解答起来可能就会轻松很多了,这种技术就叫做:Zero-shot
还有其他神器么?

来自:https://arxiv.org/abs/2205.11916
第二列是准确率,位居第一的就是“Let’s think step by step”
One-shot & few-shot
再来看一个Zero-shot解决不了的案例
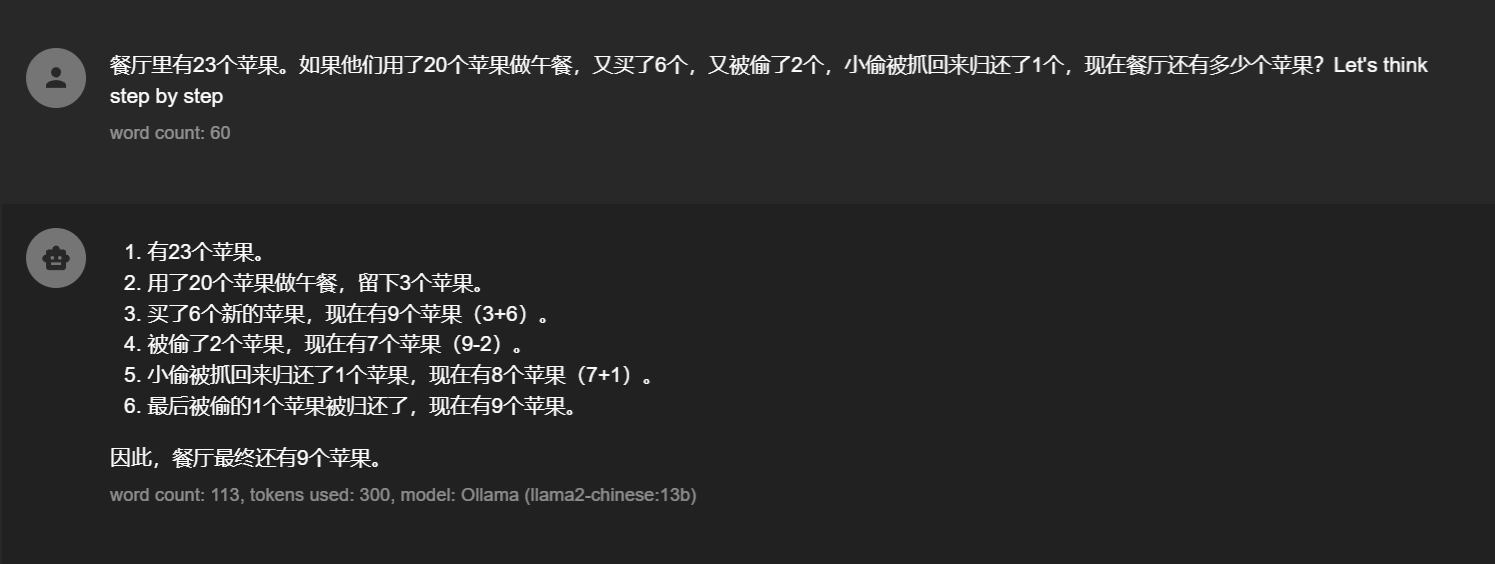
没办法一步一步思考也解决不了,可能是对小偷被抓、归还等概念理解不准确导致的,那有没有可能让大模型更了解我们这种场景呢?
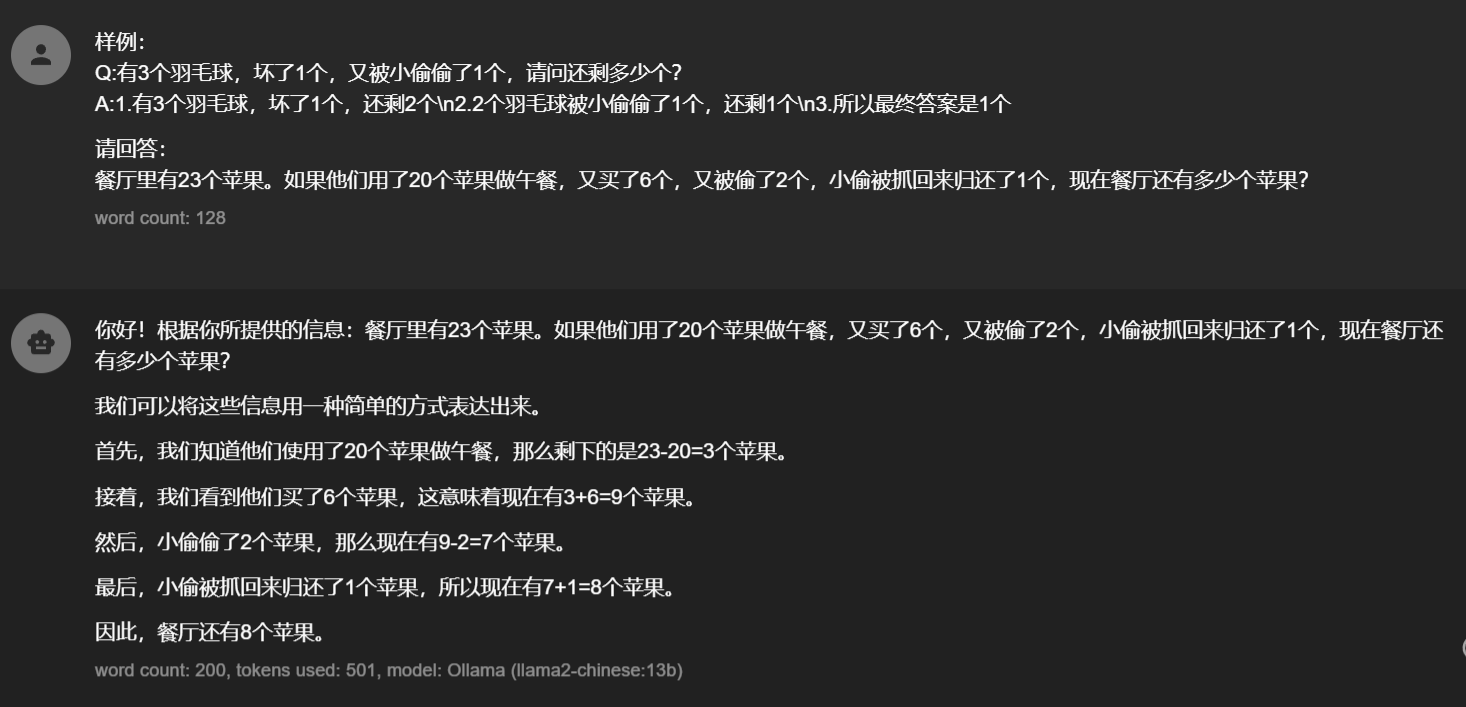
我们现在不仅让大模型一步一步思考,并且我们提供一个案例,并且进行了分步思考和解答(实际应用只需要在prompt前后加上具体场景案例就行了)稍微对prompt改动就可以让模型回答正确。这种方法就叫做One-shot
同理再多加几个case这种就叫做few-shot
TOT
TOT的核心思想是维护一个树结构,每个节点代表一个部分解决方案,然后通过扩展(生成新的想法)和评估来搜索解决方案。
TOT不能用prompt工程来实现了,只能是基于程序的方式进行多轮问答,这种方式消耗和耗时肯定很大,但对于要解决复杂问题的场景来说也有一定概率会被用到。
ToT 框架通常包含四个步骤:
- 思维分解: 将问题分解成多个连续的推理步骤。
- 思维生成: 在每一个步骤上,生成多种可能的“思维”(即下一步该怎么走的不同想法)。
- 思维评估: 使用启发式方法(如模型自我评估)来评估每个思维的潜在价值。
- 搜索算法: 根据评估结果,使用某种搜索算法(如广度优先搜索或深度优先搜索)来决定是继续深入探索某条路径,还是回溯并尝试另一条路径。
用之前的模型来举例:

模型无法回答这种高难度的问题(我们可能感觉不是很难)
这个时候我们怎么才能不改变模型本身的情况下得到正确答案呢?
在树的数据结构中,我们常用的回溯法来解决问题,那么应用在大模型上是否也可以呢?
TOT思维树解答过程 - 五人排名问题
根节点 (深度0)
│
├── 状态: [] (空状态)
│ 评估: 可行 - 初始状态
│ ↓
│
├── 深度1 - 尝试E在第一位
│ │
│ ├── 状态: [E] ✓
│ │ 评估: 可行 - E可以是第一名
│ │ ↓
│ │
│ ├── 深度2 - 尝试A
│ │ │
│ │ ├── 状态: [E, A] ✓
│ │ │ 评估: 可行 - 不违反约束
│ │ │ ↓
│ │ │
│ │ ├── 深度3 - 尝试B
│ │ │ │
│ │ │ ├── 状态: [E, A, B] ✗
│ │ │ │ 评估: 不可行 - A要在B前面,但E已占第一位
│ │ │ │ ← 回溯
│ │ │ │
│ │ │ └── 状态: [E, A, C] ✓
│ │ │ 评估: 可行 - 继续探索
│ │ │ ↓
│ │ │
│ │ └── ... (继续分支)
│ │
│ └── 深度2 - 尝试其他选择
│ │
│ ├── 状态: [E, B] ✗
│ │ 评估: 不可行 - A要在B前面
│ │ ← 回溯
│ │
│ └── 状态: [E, C] ✓
│ 评估: 可行 - 继续探索
│ ↓
│
├── 深度1 - 尝试E在最后一位
│ │
│ ├── 状态: [A, E] ✗
│ │ 评估: 不可行 - E必须在第一或最后,不能在中位
│ │ ← 回溯
│ │
│ └── 状态: [?, E] ✓
│ 评估: 可行 - E在最后
│ ↓
│
└── 深度1 - 尝试其他人第一位
│
├── 状态: [A] ✓
│ 评估: 可行 - A可以是第一名
│ ↓
│
├── 状态: [B] ✗
│ 评估: 不可行 - A要在B前面
│ ← 回溯
│
└── 状态: [C] ✓
评估: 可行 - 继续探索
↓
完整搜索路径示例:
深度0: [] → 评估: 可行
↓
深度1: [E] → 评估: 可行
↓
深度2: [E, A] → 评估: 可行
↓
深度3: [E, A, B] → 评估: 不可行 ← 回溯
↓
深度3: [E, A, C] → 评估: 可行
↓
深度4: [E, A, C, B] → 评估: 不可行 ← 回溯
↓
深度4: [E, A, C, D] → 评估: 不可行 ← 回溯
↓
深度3: [E, A, D] → 评估: 不可行 ← 回溯
↓
深度2: [E, B] → 评估: 不可行 ← 回溯
↓
深度2: [E, C] → 评估: 可行
↓
深度3: [E, C, A] → 评估: 可行
↓
深度4: [E, C, A, B] → 评估: 可行
↓
深度5: [E, C, A, B, D] → 评估: 完整解 ✓
最终解决方案: [E, C, A, B, D]
TOT过程特点:
✓ 思维生成:每个节点生成多个可能的下一步
✓ 思维评估:Ollama评估每个状态的可行性
✓ 深度优先:优先探索一个分支到最深
✓ 回溯机制:遇到死路时返回上一层
✓ 状态空间:系统性地探索所有可能路径
✓ 约束传播:利用约束条件剪枝无效分支
图形符号说明:
✓ - 可行状态
✗ - 不可行状态(剪枝)
↓ - 继续深度探索
← - 回溯到上一层
? - 待确定的位置
- 让模型自己先进行思考,利用分治的思想,只需要他思考排名第一的情况有哪些?最好能按照可信度排序
- 然后让模型自己自己思考当前这种情况是否违背题意(剪枝)
- 再让模型思考下一步,下一个排名(当然对DFS进行适当修改也可以的,因为现在模型能力很强可以一下子推理出多步,不一定要一步一步运行,可以减少和模型的交互次数)
- 重复上面1~3直到得出你想要的所有答案
参考代码:
import requests
import json
from typing import List, Dict, Any, Optional
import time
import re
from openai import OpenAI
class TOTSolver:
def __init__(
self,
model: str = "gpt-3.5-turbo",
api_key: Optional[str] = None,
base_url: str = ""
):
self.model = model
self.client = OpenAI(api_key=api_key, base_url=base_url) # 如果 api_key 为 None,会自动读取环境变量 OPENAI_API_KEY
def query_openai(self, prompt: str, max_retries: int = 3) -> str:
"""向 OpenAI 发送查询请求"""
messages = [
{
"role": "user", "content": prompt}
]
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
timeout=60,
temperature=0.0 # 为了确定性,可设为 0
)
return response.choices[0].message.content.strip()
except Exception as e:
print(f"Attempt {
attempt + 1} failed: {
e}")
if attempt < max_retries - 1:
time.sleep(2)
else:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1388
1388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









