




提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
本文可用于机器学习作业,我们这里使用了三种方法进行判定,因为现在很多研究中经常会用MNIST的分类性能作为基准任务。
一、MNIST
MNIST是一个广泛使用的手写数字数据集,主要用于训练和测试机器学习模型。以下是对MNIST的简短介绍:
-
手写数字识别:MNIST包含60,000个训练样本和10,000个测试样本,全部为0-9的手写数字图像。
-
灰度图像:每个样本都是28x28像素的灰度图像,像素值范围为0-255。
-
简单任务:MNIST常被用作机器学习入门任务,因为它的数据集规模适中,且任务难度较低。
-
基准测试:MNIST常用于评估机器学习算法的性能,作为入门级的基准测试。
-
应用广泛:MNIST被广泛应用于深度学习、计算机视觉等领域,是机器学习领域的经典数据集之一。
二、方法
1.KNN
(1)KNN的结构如下图:
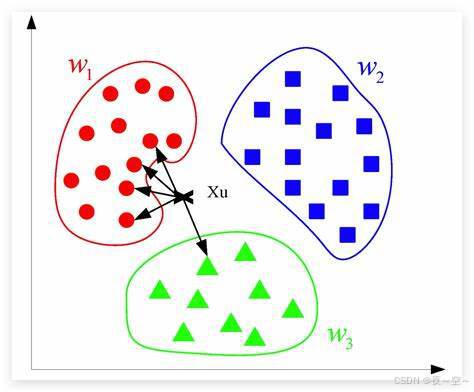
KNN,K近邻算法,找出待测样本距离最近的K个样本,根据计算距离,取最近距离的为它的标记。 具体的想要多加学习的朋友可以看一看算法详解,以及学习函数 neighbors.KNeighborsClassifier() 的参数
(2)代码如下:
import pandas as pd
from sklearn import neighbors
from sklearn.metrics import accuracy_score, confusion_matrix
import numpy as np
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 加载数据
train_data = pd.read_csv("./train.csv") #这里这个train文件是使用Kaggle提供的csv文件,若是想要修改,改成和下面test—_data类似的格式,查一下就好了
train_dataset = train_data.iloc[:, 1:].values # 提取特征
train_label = train_data.iloc[:, 0].values # 提取标签
test_dataset = MNIST(root='./data', train=False, download=True, transform=transforms.ToTensor())
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False)
# 初始化KNN模型
knn = neighbors.KNeighborsClassifier(n_neighbors=5)
# 训练模型
knn.fit(train_dataset, train_label)
# 在训练集上进行预测
train_pred = knn.predict(train_dataset)
# 计算训练集上的准确率
train_accuracy = accuracy_score(train_label, train_pred)
print(f'Train accuracy: {train_accuracy:.4f}')
# 预测测试集结果
all_labels = [] # 用于存储真实标签
test_data = []
for data, label in test_loader:
data = data.numpy().flatten()
test_data.append(data)
all_labels.extend(label.numpy())
# 将列表转换为NumPy数组
test_data = np.array(test_data) * 255
all_labels = np.array(all_labels).flatten()
# 确保标签是整型
all_labels = all_labels.astype(int)
# 将测试数据转换为DataFrame
test_data = pd.DataFrame(test_data)
# 预测测试集结果
all_predictions = knn.predict(test_data)
# 计算准确率
accuracy = accuracy_score(all_labels, all_predictions)
print(f'Test accuracy: {accuracy:.4f}')
# 将预测结果保存到CSV文件
a = pd.Series(all_predictions)
b = pd.Series(np.arange(1, len(all_predictions) + 1))
c = pd.DataFrame([a, b])
d = pd.DataFrame(c.T)
d.to_csv("./result/knn_mnist_torch.csv", index=False)
# 计算混淆矩阵
conf_matrix = confusion_matrix(all_labels, all_predictions)
# 归一化混淆矩阵以显示百分比
conf_matrix_norm = conf_matrix.astype('float') / conf_matrix.sum(axis=1)[:, np.newaxis]
# 绘制混淆矩阵
plt.figure(figsize=(10, 8))
plt.imshow(conf_matrix_norm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('KNN Confusion Matrix')
#plt.colorbar()
tick_marks = np.arange(10)
plt.xticks(tick_marks, tick_marks)
plt.yticks(tick_marks, tick_marks)
# 在每个方格中添加百分比数值
thresh = conf_matrix_norm.max() / 2.
for i, j in np.ndindex(conf_matrix.shape):
plt.text(j, i, f"{conf_matrix_norm[i, j]:.2%}",
horizontalalignment="center",
color="white" if conf_matrix_norm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
# 保存混淆矩阵为图片
plt.savefig("./result/KNN_confusion_matrix.png") # 保存为PNG图片
# 显示混淆矩阵
plt.show()
2.CNN
(1)CNN模型的结构如下:
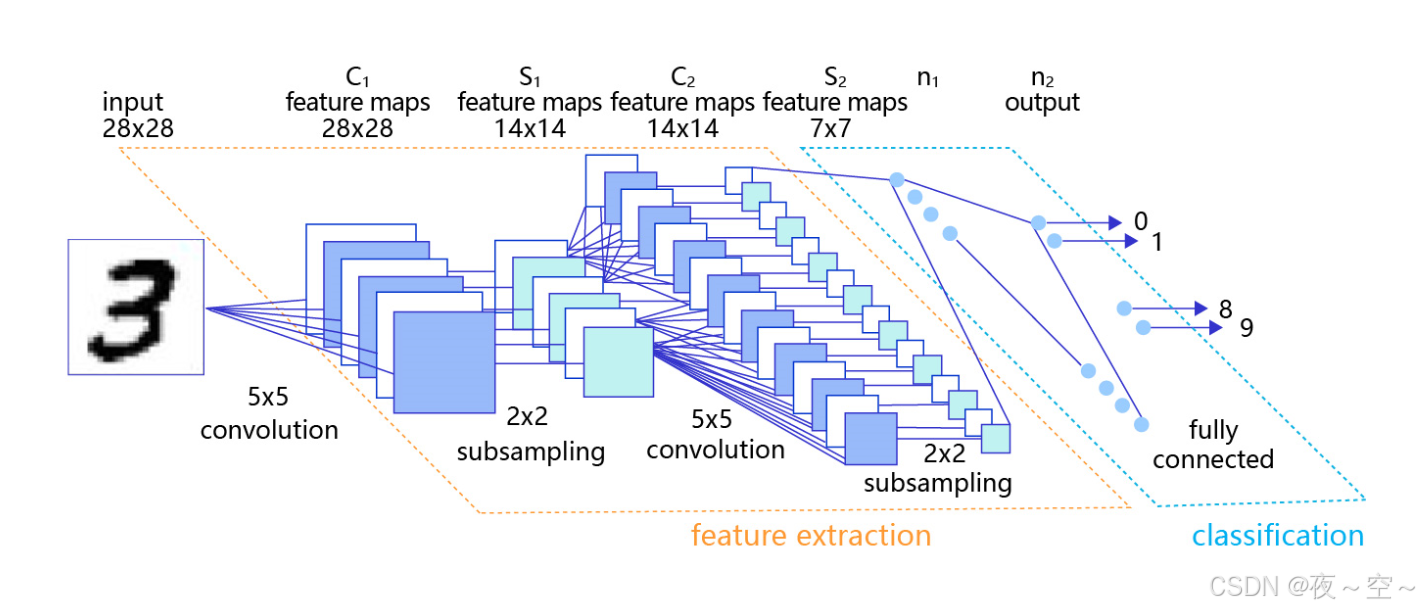
卷积神经网络的组成是卷积层,池化层和全连接层,可以调用函数。这里的MNIST可以作为一个简单的入门。
(2)代码如下:
import itertools
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import OneHotEncoder
from torchvision import transforms
from torchvision.datasets import MNIST
# 设置随机种子
np.random.seed(2)
torch.manual_seed(2)
# 加载数据
train = pd.read_csv("./train.csv")
Y_train = train["label"]
X_train = train.drop(labels=["label"], axis=1)
X_train = X_train.values.reshape(-1, 1, 28, 28) / 255.0
# 将标签转换为one-hot编码
encoder = OneHotEncoder(sparse_output=False)
Y_train = encoder.fit_transform(Y_train.values.reshape(-1, 1))
# 划分训练集和验证集
X_train, X_val, Y_train, Y_val = train_test_split(X_train, Y_train, test_size=0.1, random_state=2)
# 创建TensorDataset和DataLoader
train_dataset = TensorDataset(torch.tensor(X_train, dtype=torch.float32), torch.tensor(Y_train, dtype=torch.float32))
val_dataset = TensorDataset(torch.tensor(X_val, dtype=torch.float32), torch.tensor(Y_val, dtype=torch.float32))
train_loader = DataLoader(train_dataset, batch_size=86, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=86, shuffle=False)
# 定义模型
class CNN1(nn.Module):
def __init__(self):
super(CNN1, self).__init__()
self.cnn1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=5, padding='same'),
nn.ReLU(),
nn.Conv2d(32, 32, kernel_size=5, padding='same'),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Dropout(0.25),
nn.Conv2d(32, 64, kernel_size=3, padding='same'),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding='same'),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Dropout(0.25),
nn.Flatten(),
nn.Linear(64*7*7, 256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, 10)
)
def forward(self, x):
out = self.cnn1(x)
return out
# 实例化模型并移动到GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = CNN1().to(device)
# 定义优化器和损失函数
optimizer = optim.RMSprop(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 训练模型
epochs = 5
for epoch in range(epochs):
model.train()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, torch.argmax(target, dim=1))
loss.backward()
optimizer.step()
# 验证模型
model.eval()
val_loss = 0
correct = 0
with torch.no_grad():
for data, target in val_loader:
data, target = data.to(device), target.to(device)
output = model(data)
val_loss += criterion(output, torch.argmax(target, dim=1)).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(torch.argmax(target, dim=1).view_as(pred)).sum().item()
val_loss /= len(val_loader)
print(f'Epoch {epoch+1}/{epochs}, Val Loss: {val_loss:.4f}, Val Acc: {correct/len(val_dataset):.4f}')
# 预测测试集结果
model.eval()
test_dataset = MNIST(root='./data', train=False, download=True, transform=transforms.ToTensor())
test_loader = DataLoader(test_dataset, batch_size=86, shuffle=False)
all_predictions = []
all_labels = [] # 用于存储真实标签
with torch.no_grad():
for data, labels in test_loader:
data = data.to(device).float() # 确保测试数据也是float类型
labels = labels.to(device) # 将标签也移动到设备上
output = model(data)
all_predictions.extend(output.argmax(dim=1).cpu().numpy()) # 获取预测结果的类别
all_labels.extend(labels.cpu().numpy()) # 获取真实标签
# 计算准确率
accuracy = accuracy_score(all_labels, all_predictions)
print(f'Test accuracy: {accuracy:.4f}')
# 确保all_predictions的长度与测试集样本数量相匹配
assert len(all_predictions) == len(test_dataset), "预测结果的数量与测试集样本数量不匹配"
# 计算混淆矩阵
conf_matrix = confusion_matrix(all_labels, all_predictions)
# 绘制混淆矩阵
plt.figure(figsize=(10, 8))
plt.imshow(conf_matrix, interpolation='nearest', cmap=plt.cm.Blues)
plt.title(' CNN Confusion Matrix')
#plt.colorbar()
tick_marks = np.arange(10)
plt.xticks(tick_marks, tick_marks)
plt.yticks(tick_marks, tick_marks)
# 将混淆矩阵的每个元素转换为百分比
conf_matrix_percent = conf_matrix.astype('float') / conf_matrix.sum(axis=1)[:, np.newaxis]
thresh = conf_matrix.max() / 2.
for i, j in itertools.product(range(conf_matrix.shape[0]), range(conf_matrix.shape[1])):
plt.text(j, i, f"{conf_matrix_percent[i, j]:.2%}",
horizontalalignment="center",
color="white" if conf_matrix[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
# 保存混淆矩阵为图片
plt.savefig("./result/CNN_confusion_matrix.png") # 保存为PNG图片
# 显示混淆矩阵
plt.show()
==注:上面的只是结构示意图不是所构建网络的模型
3.DNN
(1)DNN模型的结构如下:
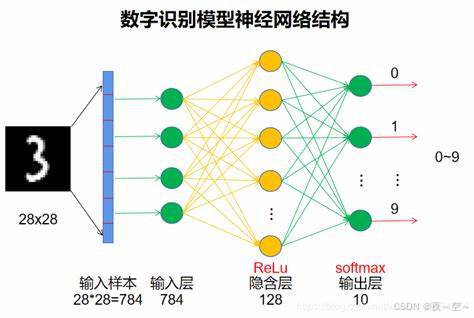
这里是只使用全连接层和激活函数构建的神经网络,按理来说不能这样定义的,但是作为入门学习很有效果。
代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import pandas as pd
import numpy as np
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from torchvision import transforms
from torchvision.datasets import MNIST
import matplotlib.pyplot as plt
import itertools
# 定义DNN模型
class DNN(nn.Module):
def __init__(self):
super(DNN, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
# 设置设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载数据集
train = pd.read_csv("./train.csv")
test = pd.read_csv("./test.csv")
Y_train = train["label"]
X_train = train.drop(labels=["label"], axis=1)
X_train = X_train.values.reshape(-1, 1, 28, 28) / 255.0
test = test.values.reshape(-1, 1, 28, 28) / 255.0
# 将标签转换为one-hot编码
encoder = OneHotEncoder(sparse_output=False)
Y_train = encoder.fit_transform(Y_train.values.reshape(-1, 1))
# 划分训练集和验证集
X_train, X_val, Y_train, Y_val = train_test_split(X_train, Y_train, test_size=0.1, random_state=2)
# 创建TensorDataset和DataLoader
train_dataset = TensorDataset(torch.tensor(X_train, dtype=torch.float32), torch.tensor(Y_train, dtype=torch.float32))
val_dataset = TensorDataset(torch.tensor(X_val, dtype=torch.float32), torch.tensor(Y_val, dtype=torch.float32))
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
# 初始化模型、损失函数和优化器
model = DNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
epochs = 5
for epoch in range(epochs):
model.train()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, torch.argmax(target, dim=1))
loss.backward()
optimizer.step()
# 验证模型
model.eval()
val_loss = 0
correct = 0
with torch.no_grad():
for data, target in val_loader:
data, target = data.to(device), target.to(device)
output = model(data)
val_loss += criterion(output, torch.argmax(target, dim=1)).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(torch.argmax(target, dim=1).view_as(pred)).sum().item()
val_loss /= len(val_loader)
print(f'Epoch {epoch+1}/{epochs}, Val Loss: {val_loss:.4f}, Val Acc: {correct/len(val_dataset):.4f}')
# 预测测试集结果
model.eval()
test_dataset = MNIST(root='./data', train=False, download=True, transform=transforms.ToTensor())
test_loader = DataLoader(test_dataset, batch_size=86, shuffle=False)
all_predictions = []
all_labels = [] # 用于存储真实标签
with torch.no_grad():
for data, labels in test_loader:
data = data.to(device).float() # 确保测试数据也是float类型
labels = labels.to(device) # 将标签也移动到设备上
output = model(data)
all_predictions.extend(output.argmax(dim=1).cpu().numpy()) # 获取预测结果的类别
all_labels.extend(labels.cpu().numpy()) # 获取真实标签
# 计算准确率
accuracy = accuracy_score(all_labels, all_predictions)
print(f'Test accuracy: {accuracy:.4f}')
# 确保all_predictions的长度与测试集样本数量相匹配
assert len(all_predictions) == len(test_dataset), "预测结果的数量与测试集样本数量不匹配"
# 计算混淆矩阵
conf_matrix = confusion_matrix(all_labels, all_predictions)
conf_matrix_percent = conf_matrix.astype('float') / conf_matrix.sum(axis=1)[:, np.newaxis] * 100
# 绘制混淆矩阵的热力图
plt.figure(figsize=(10, 8))
plt.imshow(conf_matrix_percent, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('DNN Confusion Matrix')
#plt.colorbar()
tick_marks = np.arange(10)
plt.xticks(tick_marks, tick_marks)
plt.yticks(tick_marks, tick_marks)
# 在热力图上标注百分比数值
thresh = conf_matrix_percent.max() / 2.
for i, j in itertools.product(range(conf_matrix_percent.shape[0]), range(conf_matrix_percent.shape[1])):
plt.text(j, i, f"{conf_matrix_percent[i, j]:.1f}%",
horizontalalignment="center",
color="white" if conf_matrix_percent[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
# 保存混淆矩阵为图片
plt.savefig("./result/DNN_confusion_matrix.png") # 保存为PNG图片
# 显示混淆矩阵
plt.show()
在上述的代码中我加入了对测试集的预测结果给出混淆矩阵,测试结果可视化。
总结

这个总结之前写过的,直接挪过来了。

















 1098
1098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









