




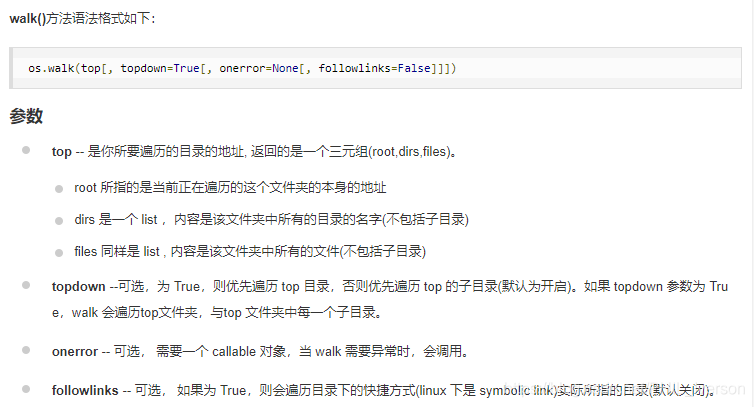
一、os.walk()
os.walk()打印遍历子目录和文件
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
for root, dirs, files in os.walk(".", topdown=False):
for name in files:
print(os.path.join(root, name))
for name in dirs:
print(os.path.join(root, name))
获取文件夹下面的文件并添加进列表
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
filelist=[]
for root, dirs, files in os.walk('path'):
for name in files:
filelist.append(name)
二、os.walk+glob.glob
glob模块的主要方法就是glob,该方法返回所有匹配文件路径列表(list);该方法需要一个参数来指定匹配的路径字符串,其返回的文件名只包括当前目录的文件名,不包括子文件夹里的文件。(所以结合os.walk)
#遍历指定文件夹包括其子文件夹,寻找某种后缀的文件,并返回找到的文件路径列表
#suffix 为指定文件类型
def traverse_dir_suffix(dirPath, suffix):
suffixList = [ ]
for (root, dirs, files)in os.walk(dirPath):
findList = glob.glob(root+'/*.'+suffix)
for f in findList:
suffixList.append(f)
return suffixList

















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









