




在原生 Postgres 实现中,全文搜索由B 树或GIN(广义倒排索引)结构支持。这些索引针对相对快速的查找进行了优化,但受限于 B 树的写入吞吐量。
当我们构建pg_searchPostgres 搜索和分析扩展时,我们的优先级有所不同。为了成为 Elasticsearch 的有效替代方案,我们需要支持高效的实时扫描。我们选择了一种更适合密集发布列表位图和高数据采集工作负载的数据结构:日志结构化合并 ( LSM ) 树。
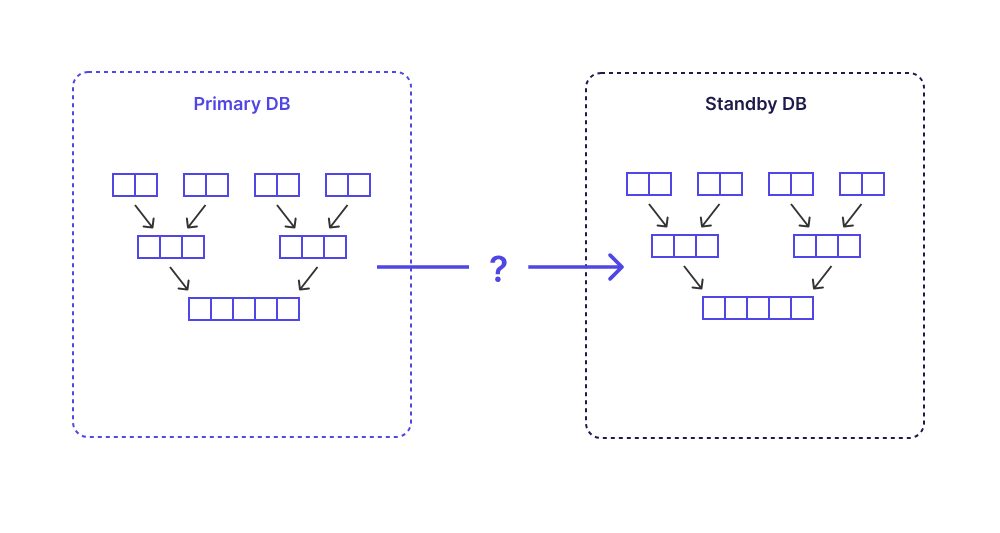
然而,当我们在物理复制(允许 Postgres 将数据从主节点复制到一个或多个只读副本的两种机制之一)下测试 LSM 树时,我们遇到了一些波折。最令人惊讶的是,我们发现 Postgres 基于预写日志 (WAL) 传输机制构建的开箱即用的物理复制支持不足以让LSM 树这样的高级数据结构实现复制安全。在本文中,我们将深入探讨:
- LSM 树的复制安全意味着什么
- Postgres 的 WAL 传输如何保证物理一致性
- 为什么原子日志对于逻辑一致性是必要的
- 我们如何利用鲜为人知但功能强大的 Postgres 设置hot_standby_feedback
什么是 LSM 树?
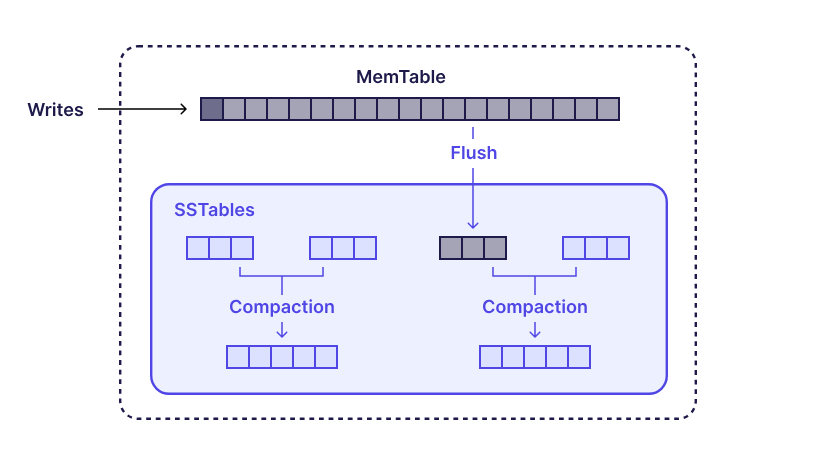
日志结构合并树 (LSM 树) 是一种写优化数据结构,常用于 RocksDB 和 Cassandra 等系统。
LSM 树的核心思想是将随机写入转换为顺序写入。传入的写入首先存储在内存缓冲区(称为 memtable)中,该缓冲区更新速度很快。一旦 memtable 写满,它将被刷新到磁盘,形成一个已排序的、不可变的段文件(通常称为 SSTable)。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3010
3010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









