






PostgreSQL 通过 pgvector 等扩展提供了高级功能,使语义搜索达到了前所未有的水平和质量。与主要依赖于简单字符串比较的传统文本搜索不同,PostgreSQL 中的语义搜索超越了关键字,通过理解上下文和含义来增强相关性。
通过 pgvector 和 pgai 等扩展,可以将关系数据库的强大功能与现代 AI 模型的尖端功能相结合。
PostgreSQL 中的语义搜索的好处
语义搜索的好处很多:
- 提高搜索准确性和用户体验
- 处理歧义
- 生成内容推荐
- 创建个性化内容
pgvector:为文本数据创建表
在我们简短介绍之后,是时候看看技术方面,看看如何真正做到这一点。为了演示的目的,我们使用了此处提供的优秀数据集。它包含 360 万条亚马逊评论,采用易于使用的 CSV 格式。
我们要做的第一件事是将扩展加载到我们的数据库中,并创建一个表,用于存储我们想要查询的数据:
cybertec=# CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION
cybertec=# CREATE TABLE t_document
(
id serial PRIMARY KEY,
polarity float,
title text,
body text,
embedding vector(384)
);
CREATE TABLE
这里有两件重要的事情需要注意。第一点是扩展已经加载到数据库中。请注意,我们在这里必须使用的名称是“vector”,而不是人们可能期望的“pgvector”。第二点值得注意的是,这里使用了一种名为“vector”的新数据类型。但是,扩展具有更多数据类型:
- 矢量:最多 2,000 维
- halfvec:最多 4,000 个维度
- sparsevec:最多 1,000 个非零元素
但是,对于我们的用例,我们需要一个具有 384 个条目的固定向量,这正是我们的模型将返回的。
导入和嵌入数据
理解“嵌入”的概念至关重要。这是什么意思?其实很简单:我们取一个字符串并将其转换为一个向量(=数字列表)。使用扩展时,理解这一点至关重要。在 PostgreSQL 中仅使用 pgvector 不会将文本转换为向量,因此我们必须想出一些代码来为我们完成此操作。
Python 是一种简单的方法来实现这一点。以下代码片段显示了如何实现这一点:
#!/usr/bin/python3
import os
import csv
from pgvector.psycopg import register_vector
import psycopg
from sentence_transformers import SentenceTransformer
# -----------------------------------------
# EDIT HERE
file = '/path/amazon_reviews/train.csv'
model_name = "multi-qa-MiniLM-L6-cos-v1"
# Set up database connection parameters
db_params = {
'host': 'localhost',
'database': 'cybertec',
'user': 'your_user',
'password': 'your_password',
'port': '5432'
}
# -----------------------------------------
def main():
# create model for embedding
model = SentenceTransformer(model_name)
# Create the connection
conn = psycopg.connect(
host=db_params['host'],
dbname=db_params['database'],
user=db_params['user'],
password=db_params['password'],
port=db_params['port']
)
register_vector(conn)
cur = conn.cursor()
lines = 0
with open(file, 'r', encoding='utf-8') as csvfile:
csv_reader = csv.reader(csvfile, delimiter=',')
for row in csv_reader:
lines += 1
emb = model.encode(row[1] + " " + row[2])
cur.execute("INSERT INTO t_document (polarity, title, body, embedding) VALUES (%s, %s, %s, %s) ", (row[0], row[1], row[2], emb))
if lines % 1000 == 0:
print("rows imported: %s" % (lines))
conn.commit()
conn.commit()
if __name__ == "__main__":
main()
这段代码到底在做什么?让我们一步一步地看。首先,我们必须导入几个库,例如 psycopg(正在使用的 Python 库),以便与 PostgreSQL 通信。
然后我们必须运行:
from pgvector.psycopg import register_vector
现在,这一行很重要,因为我们必须为 psycopg 添加一些功能。否则就无法很好地处理向量。完成此操作后,我们需要一个模型来转换输入。为此,HuggingFace是最佳选择。它包含可与我们刚刚导入的 SentenceTransformer 类一起使用的模型。
接下来,我们可以向驱动程序注册其他数据类型,打开游标,然后就可以开始了。我们可以简单地打开 CSV 文件并循环遍历它。每行都包含一条评论,格式方便使用。真正的魔法发生在这里:
emb = model.encode(row[1] + " " + row[2])
在这一行中,我们将标题和正文输入到 HuggingFace 模型中,并获取一个数字向量,然后将其简单地插入到表中。每隔几千行,我们就会发出一次 COMMIT。基本上,这不是必需的,但很高兴看到导入过程中发生的一些事情,以便在嵌入仍在进行时运行一些基本测试。请注意,这里的大部分时间不是由实际数据库消耗的,而是由正在使用的模型消耗的,因此并行执行一些工作肯定是有帮助的。
以下代码片段展示了如何运行代码:
$ time ./handle_comments.py
rows imported: 1000
rows imported: 2000
...
rows imported: 3599000
rows imported: 3600000
real 325m35.287s
user 311m50.151s
sys 2m11.664s
请注意,执行时间相当长 - 因此并行运行这些程序以利用机器上的所有 CPU 是有意义的。在这种情况下,所有内容都在单个核心上运行。
pgvector:向量和相似度是什么意思?
运行脚本需要花费相当长的时间。很多人会问:结果到底是什么样的?好吧,下面是一个例子:
cybertec=# \x
Expanded display is on.
cybertec=# SELECT * FROM t_document LIMIT 1;
-[ RECORD 1 ]-----------------------------------------------------------------
id | 1
polarity | 2
title | Stuning even for the non-gamer
body | This sound track was beautiful! It paints the senery in your mind
so well I would recomend it even to people who hate vid. game
music! I have played the game Chrono Cross but out of all of the
games I have ever played it has the best music! It backs away
from crude keyboarding and takes a fresher step with grate guitars
and soulful orchestras. It would impress anyone who cares to listen!
embedding | [-0.051104408,-0.06477496,0.053947136,-0.090758994,-0.11248113,
0.021052703,0.040592767,0.033487927,0.008018044,0.030972324,
-0.09552986,-0.041627012,-0.032203916,-0.08294443,-0.0076782834,
0.039493423,0.06395606,-0.014506877,0.023361415,-0.022605361,
...
0.0133066205,-0.003375273,-0.003283798,-0.08727879,0.02891936]
请注意,输入数据包含拼写错误。我们稍后会讨论这个问题。我们不能指望所有输入数据都 100% 正确。
重点是:每个文本都表示为一组数字。人工智能的目标是找到彼此接近的向量。但在这种情况下,“接近”是什么意思呢?
首先,计算距离的方法有很多种。以下是一些选项:
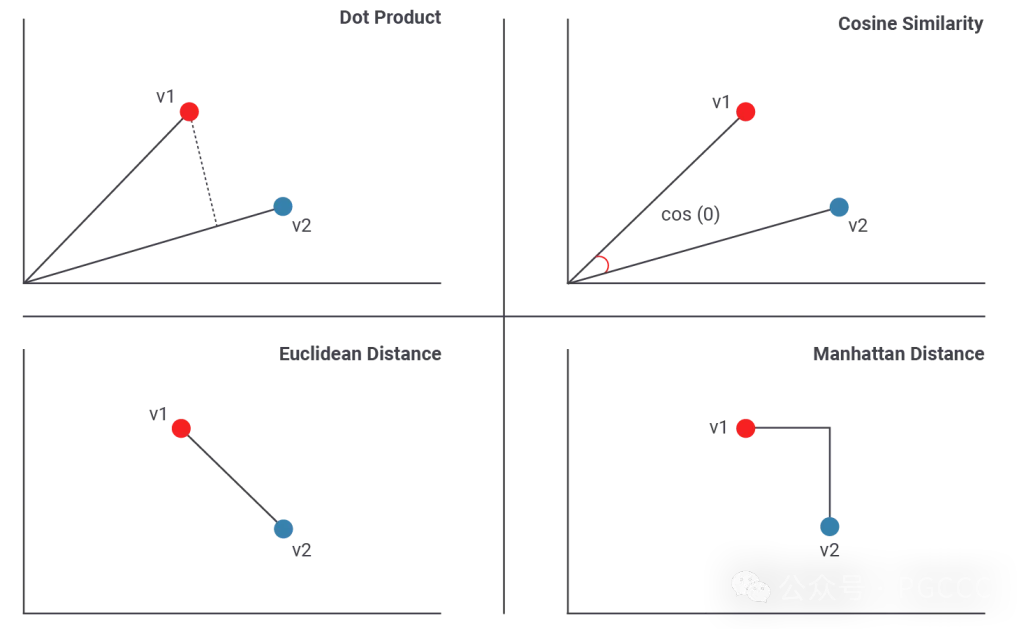
您可能已经见过“点积”和“余弦距离”。上图显示了它们的实际含义。
让我们把注意力集中在“相似性”的概念上。下面是该概念的简单介绍:

显然,这一切都发生在超空间中,但心中有一个简单的想法还是很有用的。
在 PostgreSQL 中运行相似性搜索
导入数据并准备好一切后,就到了关键时刻:我们可以编写一个程序,将现实世界的搜索字符串转换为查询。给定某个搜索字符串,以下代码将返回最佳结果:
#!/usr/bin/python3
import os, sys
import psycopg
from pgvector.psycopg import register_vector
from sentence_transformers import SentenceTransformer
# -----------------------------------------
# EDIT HERE
model_name = "multi-qa-MiniLM-L6-cos-v1"
# Set up database connection parameters
db_params = {
'host': 'localhost',
'database': 'cybertec',
'user': 'your_user',
'password': 'your_password',
'port': '5432'
}
# -----------------------------------------
def main():
if len(sys.argv) < 2:
print("Usage: please provide a query string")
sys.exit(1)
query_string = sys.argv[1]
print("Querying database for: '%s'" % (query_string))
# create model for embedding
model = SentenceTransformer(model_name)
# Create the connection
conn = psycopg.connect(
host=db_params['host'],
dbname=db_params['database'],
user=db_params['user'],
password=db_params['password'],
port=db_params['port']
)
register_vector(conn)
cur = conn.cursor()
# transform query string into vector
emb = model.encode(query_string)
result = conn.execute('SELECT embedding <=> %s AS distance, title, body FROM t_document ORDER BY embedding <=> %s LIMIT 5', (emb, emb)).fetchall()
for row in result:
print("Result item: ")
print(f" Distance: " + str(row[0]))
print(f" Title: : " + str(row[1]))
print(f" Body : " + str(row[2]))
print ("\n")
if __name__ == "__main__":
main()
实际上,大约前 40 行代码与之前一样。我们定义模型、连接数据库、获取命令行参数,并在没有参数传递给我们的 Python 程序的情况下发出一条非常酷的错误消息。但真正的魔法发生在哪里?它在这里:
emb = model.encode(query_string)
我们使用与之前相同的模型将搜索字符串转换为向量。最后,我们可以运行通常称为“KNN 搜索”的东西。其思想是按与所需元素的距离进行排序并返回顶部结果。这正是最后的循环所做的。
人们会问的一个问题是:ORDER BY 子句中这个奇怪的“<=>”运算符是什么?我们之前提到过“距离”的概念。pgvector 提供以下可用的运算符:
- 内积:<#>
- 余弦距离:<=>
- L1 距离:<+>
在这种情况下,我们采用余弦距离。
尝试一切
经过这个冗长且希望有用的介绍后,是时候运行代码并看看它能为我们做些什么了。在我的展示中,我想找到所有与字符串“mooney 飞机导航文献”匹配的评论。因此,我们的想法是找到所有可能与 Mooney Aircraft 公司制造的飞机有关并与导航书籍有关的评论。结果如下:
$ ./query_comments.py "mooney airplane navigation literature"
Querying database for: 'mooney airplane navigation literature'
Result item:
Distance: 0.3748793229388776
Title: : Great Book!
Body : I gave this book as a gift to a person who has an interest in
historic aircraft. The recipient of the gift was very, very
appeciative and thought it was an excellent reference.
Result item:
Distance: 0.3833693082144648
Title: : Decent airplane book but nothing more
Body : I would not recommend anyone buying this book. If you are
curious, check it out from the library. The character development
is shallow and the story is generally not well written. The
readers who have enjoyed this must be very young, and therefore
not exposed to the better writers of the past. I put a lot of
blame on the editor of this book, as it is his job to assist the
writer in preparing the manuscript. I will not read this author
again.
Result item:
Distance: 0.38802472913338903
Title: : Super, Great Information
Body : If you are an airplane lover, you should order this book.
Great pictures and facts.
Result item:
Distance: 0.3974898514887534
Title: : Wonderfully done book
Body : This book is wonderful, I love seeing aircraft put to sleep in
the boneyards! Philip D. Chinnery has an awesome book here! I
would recommend it to all aviation enthusiasts to buy, it's
well worth it!
Result item:
Distance: 0.39884170286903886
Title: : Good book
Body : Very good way to adventure on this Plane but the content is a
little bit on the less exciting part but a good book over all
请注意,这些条目中没有一个与 Mooney 飞机有关。这是有道理的,因为导航根本不与品牌相关。我们还可以看到没有找到“文学”这个词 - 但是,系统已经理解“文学”似乎与“书籍”相关,因此
在这种情况下我们得到了大量的书评(这是数据中存在的)。简而言之:结果是相关的,并且远远优于标准 FTS(=全文搜索)给我们的结果。
使用向量索引来加速
目前的问题是,PostgreSQL 必须扫描包含 360 万行的整个表才能找到这些结果。显然,这不是太有效,因此创建索引是有意义的:
cybertec=# SET maintenance_work_mem TO '64 GB';
SET
cybertec=# CREATE INDEX ON t_document
USING ivfflat (embedding vector_cosine_ops);
CREATE INDEX
我的机器足够大,可以快速构建索引,
使用 64 GB 的 Maintenance_work_mem,它负责处理索引创建。一旦索引部署完成,我们应该会看到数据库性能显著提高。请记住,Python 脚本仍然需要一些时间来处理事情(加载库、模型等),但数据库端将非常快。
#PostgreSQl考证#PostgreSQL培训 #postgreSQL考试 #PG培训 #PG考试


















 1315
1315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









