







 本文介绍了Python中进行进制转换的内置函数,包括int()、hex()和bin(),并通过实例演示了如何将十进制转换为二进制和十六进制,特别提到了bin()函数自动省略前导零的问题及其解决方案。
本文介绍了Python中进行进制转换的内置函数,包括int()、hex()和bin(),并通过实例演示了如何将十进制转换为二进制和十六进制,特别提到了bin()函数自动省略前导零的问题及其解决方案。
Python中的进制转换(仅使用python内置函数实现)
大家有没有用python拆过帧结构?如果有,看到这里,你心里一定默念了一句fuck。python对位的处理,确实不如C/C++好用,不过没关系,也一样简单,今天给大家梳理一下,python中进制转换,只使用python内置函数实现(我相信一定有不少同学上来就想手动实现,别着急,不要造轮子)。
1.首先要知道python中的几个内置函数
(1)int()
- 参数:字符串或数字,默认十进制。
返回值:返回整型数据。
可以将二进制 八进制 十六进制转换为十进制。int第二个参数表示第一个参数是哪个进制。
>>> int("1010", 2)
10
>>> int("0b1010", 2)
10
>>> int("20", 8)
16
>>> int("f", 16)
15
>>> int("0xf", 16)
15
(2)hex()
- 参数:10进制整数
返回值:返回16进制数,以字符串形式表示。
可以将十进制转换为十六进制。
>>> hex(0)
'0x0'
>>> hex(15)
'0xf'
>>> hex(255)
'0xff'
(3)bin()
- 参数:int 或者 long int 数字
返回值:字符串。
将十进制转换为二进制。
>>> bin(0)
'0b0'
>>> bin(7)
'0b111'
>>> bin(15)
'0b1111'
>>> [bin(i) for i in range(0,15)]
['0b0', '0b1', '0b10', '0b11', '0b100', '0b101', '0b110', '0b111', '0b1000', '0b1001', '0b1010', '0b1011', '0b1100', '0b1101', '0b1110']
bin函数有个问题是它会自动省略前面为0的位,不是固定的8位,这个有点坑,不过有办法转化,下面说👇。
认识了以上三个函数就够了,下面来一下实战!
2.现在我以一个实例来演示一下,以帮助理解
我要读取一个ts视频文件,解析ts的封装结构,需要按位读取。
首先,读取视频文件,然后打印一下读取数据的类型和内容,和用sublime打开的数据对比一下。
filename = "ts_streams_test/test01_clear.ts"
file = open(filename, "rb")
content = file.read(188)
print("content:", type(content), content)
content: <class 'bytes'> b'G@\x009\xa6\x00\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\x00\x00\xb0\r\x00\x00\xc1\x00\x00\x00\x01\xe0\x10-P\x98\x1b'
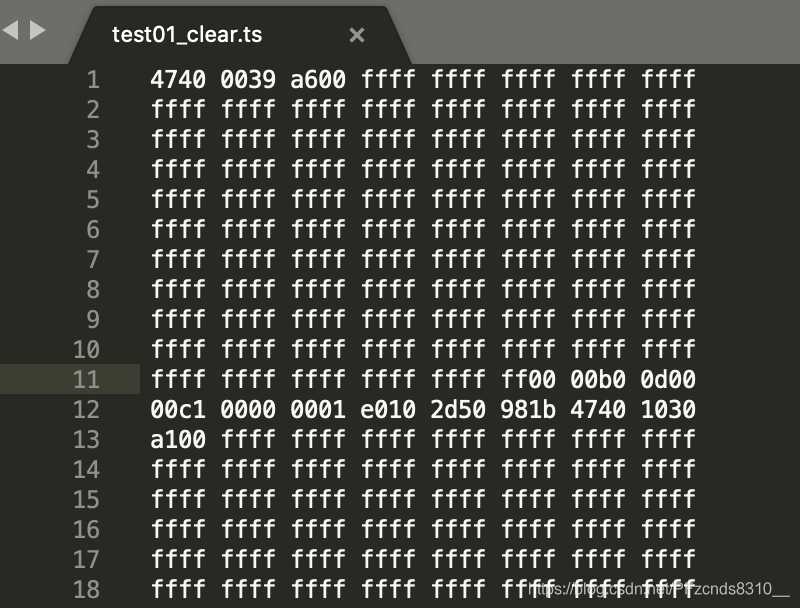
你会发现,打印的结果和sublime打开的并不一样,这是因为read读出来的是字节类型(见打印结果),而sublime是以十六进制形式打开的。在python中,字节类型的数据可以通过hex()转换成对应的十六进制。
print("content hex:", type(content.hex()), content.hex())
content hex: <class 'str'> 47400039a600ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff0000b00d0000c100000001e0102d50981b
打印结果和sublime读的完全一致。
read()读取出来的是字节类型,其实就是十进制。通过索引打印一下读出来的数据看一下就知道了。
print([[type(content[i]), content[i]] for i in range(0, len(content))])
[[<class 'int'>, 71], [<class 'int'>, 64], [<class 'int'>, 0], [<class 'int'>, 57], [<class 'int'>, 166], [<class 'int'>, 0], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255], [<class 'int'>, 255],  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 409
409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









