




ALFWorld——打通文本与物理世界的交互学习
在具身智能(Embodied Intelligence)领域,让智能体同时具备抽象推理与物理执行能力是核心挑战。今天分享的这篇ICLR 2021论文《ALFWorld: Aligning Text and Embodied Environments for Interactive Learning》,提出了首个文本与具身环境对齐的交互式框架,为智能体在抽象语言与物理世界间架起桥梁,一起来探索其创新之处吧!
论文标题
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
来源
ICLR 2021 + arXiv:2010.03768: https://arxiv.org/abs/2010.03768
文章核心
研究背景
具身智能的核心挑战在于让智能体无缝融合抽象语言推理与物理环境交互能力。人类可通过语言先验(如“苹果应置于厨房冰箱”的常识)快速规划动作序列,而现有具身智能系统往往依赖静态跨模态数据或纯视觉输入,难以捕捉语义抽象关系。例如,传统方法需为每个物理场景单独训练,缺乏从语言中学习通用策略的能力,且在未见环境中泛化性不足。
TextWorld等文本环境虽能支持语言交互学习,但缺乏物理 grounding;ALFRED等具身模拟器虽能提供视觉-动作反馈,却受限于训练成本高、数据多样性低的问题。如何桥接“语言抽象”与“物理具身”模态,让智能体先通过文本高效学习语义结构,再迁移至真实环境执行,成为当前领域未解决的关键难题。ALFWorld正是针对这一痛点,提出首个交互式双模态框架,为具身智能的泛化能力提升开辟新路径。
研究问题
1. 抽象与具身的割裂:传统方法依赖静态跨模态数据,缺乏动态交互能力,智能体难以从语言先验中学习泛化策略。
2. 训练效率低下:纯视觉具身环境训练成本高(如物理渲染耗时),且数据多样性不足。
3. 跨模态泛化不足:仅基于视觉的智能体难以应对未见场景和物体变体,缺乏语义抽象能力。
主要贡献
1. 首个对齐框架ALFWorld:
- 融合TextWorld文本环境(抽象语言交互)与ALFRED具身体验(视觉-动作执行),支持智能体在文本中学习抽象策略,再迁移至具身环境执行。
- 如图1所示,同一任务可在文本端用“goto cabinet”等高级动作规划,在具身端分解为“MOVE AHEAD”“ROTATE LEFT”等低级物理动作,实现跨模态对齐。
2. 模块化智能体BUTLER:
- BUTLER::BRAIN:在TextWorld中通过模仿学习(DAgger)训练文本策略,生成高级动作(如“heat object with microwave”)。
- BUTLER::VISION:使用Mask R-CNN将视觉输入转为文本观测,桥接视觉与语言模态。
- BUTLER::BODY:通过A*算法规划导航路径,将高级动作映射为具身环境中的低级动作序列。
3. 泛化能力验证:
- 文本预训练使智能体在ALFRED未见场景的零样本迁移成功率比纯具身训练高7×,且训练速度快7倍(TextWorld无需渲染)。
- 消融实验证明,文本交互学习(而非静态语料)是泛化能力提升的关键。

方法论精要
ALFWorld双模态对齐框架:文本与具身的协同引擎
ALFWorld创新性地构建了并行交互的双模态环境,实现抽象语言与物理世界的深度对齐:
1. TextWorld文本环境:基于PDDL(规划领域定义语言)生成文本化场景,智能体通过高级文本动作(如goto {recep} heat {obj} with {recep})交互。文本观测由上下文敏感语法生成(如“On the countertop, you see a cloth 1 and a soapbottle 1”),屏蔽物理细节,聚焦语义关系学习。
2. ALFRED具身环境:基于THOR模拟器的高保真视觉场景,智能体通过低-level物理动作(如MOVE AHEAD PICKUP)执行任务。场景包含120个多样化房间,动态配置物体与容器,支持“seen”(已知物体-容器对)和“unseen”(新房间+未知组合)任务评估。
3. 跨模态对齐机制:两者共享底层状态表示(如物体位置、容器开闭状态),文本动作可映射为具身环境中的动作序列(如clean {obj}对应“走到水槽→打开水龙头→清洗物体”),形成“抽象规划-具身执行”的闭环。
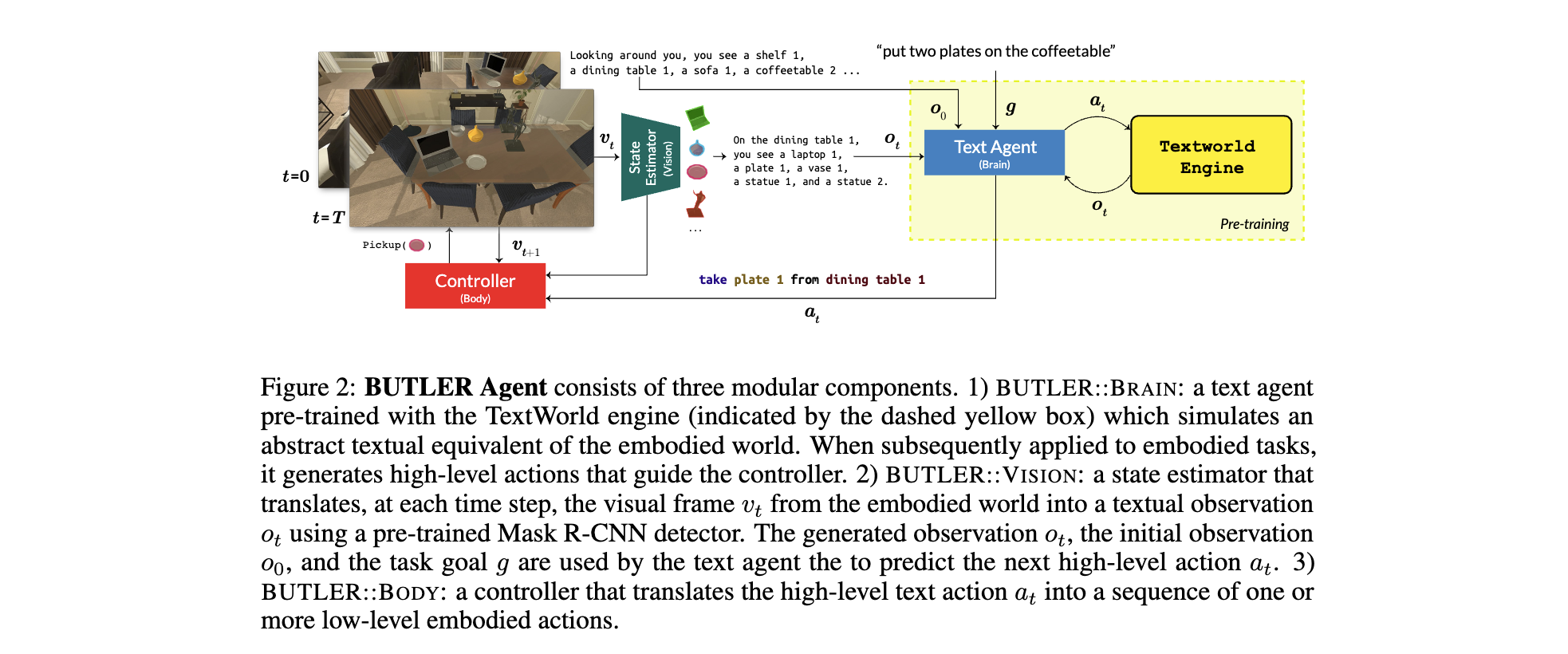
BUTLER智能体:模块化跨模态执行者
BUTLER通过三模块实现从文本策略到具身动作的端到端映射:
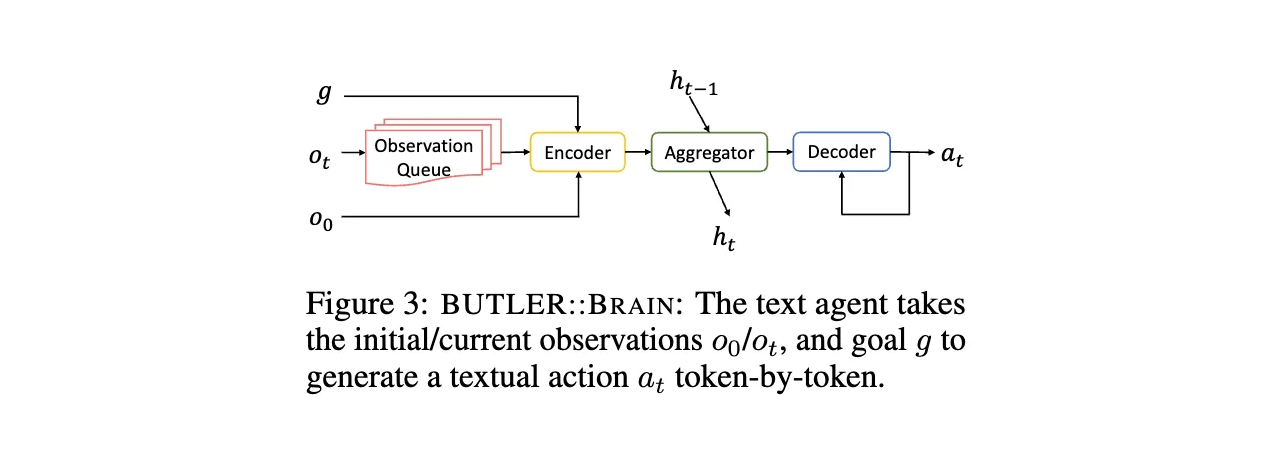
BUTLER::BRAIN:文本策略生成器
- 架构:基于Transformer的Seq2Seq模型,融合循环聚合器(GRU记忆历史状态)和观测队列(缓存最近5步文本观测+初始场景布局),解决部分可观测性问题。
- 训练:在TextWorld中通过DAgger模仿学习(在线收集专家示范轨迹)训练,生成语法正确的高级动作(如“take pan from stove”)。推理时采用**束搜索(Beam Width=10)**处理动作失败,避免重复错误。
- 输出:抽象文本动作,如“put two plates on the coffeetable”,作为具身执行的高层子目标。
BUTLER::VISION:视觉-语言状态估计器
- 功能:将具身环境的视觉输入(像素图像)转为文本观测,桥接模态差异。
- 实现:预训练Mask R-CNN检测物体(73类,支持多实例ID),结合模板生成文本描述(如“On the dining table 1, you see a plate 1 and a vase 1”)。动作执行结果通过模板反馈(如“你将mug 1放在desk 2上”或“无变化”)。
- 优化方向:未来可替换为图像字幕模型(如DenseCap)或场景图解析器,提升描述丰富度。
BUTLER::BODY:具身动作控制器
- 导航模块:基于预建场景网格地图,使用A*算法规划路径,输出
MOVE AHEADROTATE LEFT/RIGHT等动作序列,实现从当前位置到目标容器的导航。 - 操作模块:利用Mask R-CNN的物体掩码定位目标,调用ALFRED API执行
PICKUPPUT等操作类动作,支持物理约束(如大物体无法放入小容器)。 - 局限性:依赖预建地图(强先验假设),未来可引入无地图导航模型(如VLN-BERT)提升泛化性。
实验洞察
性能优势
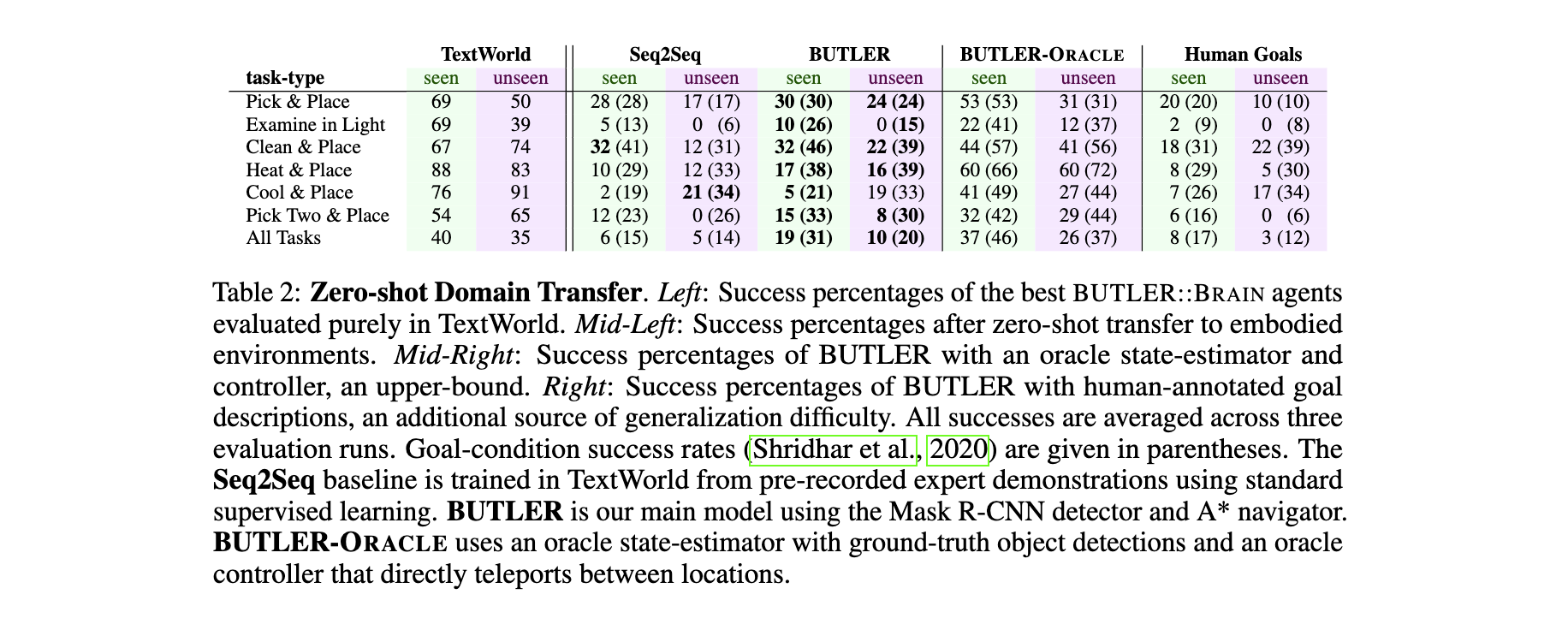
零样本迁移能力:
- 在“unseen”场景中,BUTLER的成功率比Seq2Seq高5-22%(见表2),例如“Pick & Place”任务从17%提升至24%,证明交互学习的重要性。
- BUTLER-ORACLE在“unseen”场景成功率达26-37%,表明文本策略本身具备强泛化性,性能差距主要来自具身环境的检测/导航误差。
人类语言泛化:
- 在含未见动词(如“wash”“grab”)和名词(如“rag”“lotion”)的人类标注目标中,BUTLER仍能完成**3-17%**的任务,显示语义抽象的鲁棒性。
效率突破
- 训练速度:TextWorld训练速度为6.1 episodes/s,比具身环境(0.9 episodes/s)快7倍,且无需GPU渲染,大幅降低计算成本。
- 样本效率:文本预训练使具身环境训练所需样本减少,例如“HYBRID”混合训练(75% TextWorld+25% 具身)在“unseen”场景成功率达23.1%,接近纯具身训练(23.1%),但效率更高。
消融研究
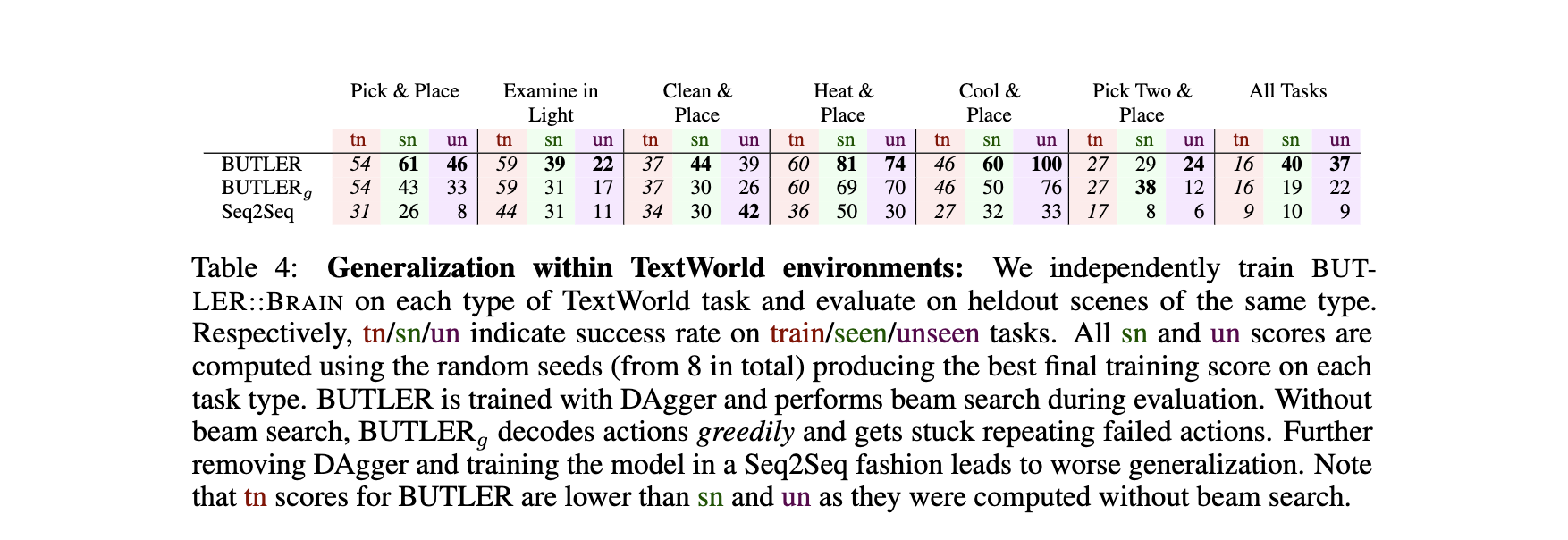
交互学习的必要性:
- 移除DAgger交互训练(仅用静态示范),成功率下降30%,证明试错探索对学习动作序列至关重要。
- 束搜索(Beam Search)使“seen”场景成功率提升21%,避免智能体重复失败动作。
模态优势对比:
- 纯视觉基线(VISION (RESNET18))在“unseen”场景成功率仅4.5-6.0%,远低于BUTLER的10.1%,说明语言抽象能有效应对视觉多样性挑战。


















 2552
2552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









