




基于策略的强化学习
1. 策略函数近似(Policy Function Approximation)
策略函数 π(a∣s)
- 策略函数是一个概率密度函数,它根据当前状态 s 输出在该状态下采取每个可能动作 a 的概率。
- 在有限的状态和动作空间中,可以直接学习这个函数。但在连续动作空间或状态空间非常大时,直接学习变得不切实际。
策略网络 π(a∣s;θ)
- 使用神经网络来近似策略函数,其中 θ 是网络的可训练参数。
- 网络输入是状态 s,输出是所有可能动作的概率分布。
- 使用Softmax激活函数确保输出的概率和为1。
2. 状态价值函数近似(State-Value Function Approximation)
动作价值函数 Q(s,a)
- 定义为从状态 s 开始并采取动作 a 的预期折扣回报。
- 动作价值函数依赖于策略函数和状态转移概率。
状态价值函数 V(s)
- 定义为在状态 s 下,按照策略 π 采取动作的预期折扣回报。
- 可以通过对动作价值函数 Q(s,a) 进行期望计算得到。
3. 基于策略的强化学习(Policy-Based Reinforcement Learning)
策略梯度(Policy Gradient)
- 目标是学习参数 θ,以最大化期望回报 J(θ)=E[V(S;θ)]。
- 使用策略梯度上升法来更新参数 θ。
策略梯度的计算
-
策略梯度是状态价值函数 V(s;θ) 关于 θ 的导数。
-
通过链式法则和期望,可以推导出策略梯度的表达式:
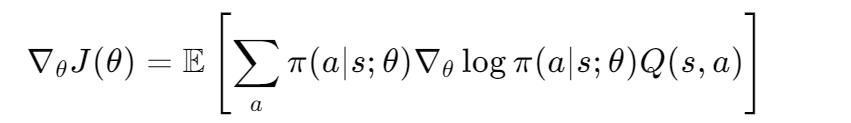
-
这个表达式表明,策略梯度可以通过对每个动作的概率的对数梯度与该动作的价值的乘积的期望来计算。
4. 离散和连续动作空间中的策略梯度计算
离散动作空间
- 使用策略梯度的第一种形式,直接对每个动作的概率进行求和。
连续动作空间
- 使用策略梯度的第二种形式,通过期望来计算梯度。
- 通过从策略分布中采样动作,并计算这些动作的梯度,可以得到策略梯度的无偏估计。
5. 使用策略梯度更新策略网络
算法步骤
- 观察状态 s。
- 根据策略网络 π(a∣s;θ) 随机采样动作 a。
- 计算 Q(s,a) 的估计值(可以通过某种方法得到)。
- 对策略网络进行微分,得到
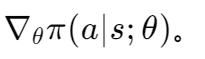
- 计算(随机)策略梯度:
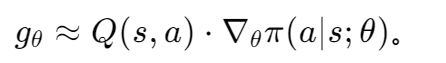
- 更新策略网络:θnew=θ+β⋅gθ。
具体方法
- REINFORCE:通过玩完整个游戏来生成轨迹,并使用折扣回报来近似 Q(s,a)。
- Actor-Critic方法:使用一个神经网络来近似 Q(s,a),这将在文件4中详细讨论。
6. 总结
- 基于策略的学习:如果已知一个好的策略函数 π,智能体可以根据该策略随机采样动作 a∼π(s)。
- 策略网络:通过策略梯度算法学习策略网络,以最大化期望回报。
- 策略梯度算法:学习参数 θ,以最大化 E[V(S;θ)]。

















 4568
4568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









