







 本文详细介绍了字典树 Trie,它是存储字符串集合的树形数据结构,可快速查找字符串。文中阐述了插入、查询操作,给出数组和指针实现模板,还列举了多种习题,如前缀统计、最大异或和等,展示了 Trie 在不同场景的应用。
本文详细介绍了字典树 Trie,它是存储字符串集合的树形数据结构,可快速查找字符串。文中阐述了插入、查询操作,给出数组和指针实现模板,还列举了多种习题,如前缀统计、最大异或和等,展示了 Trie 在不同场景的应用。
文章目录
字典树 Trie
简介
Trie是一种存储字符串集合的树形数据结构,我们可以将一个字符串集合保存到Trie里, 并快速地进行字符串查找。
在Trie树里, 除了根节点,每个节点可以存储一个字符,从根节点到树上某一节点的路径代表一个字符串。
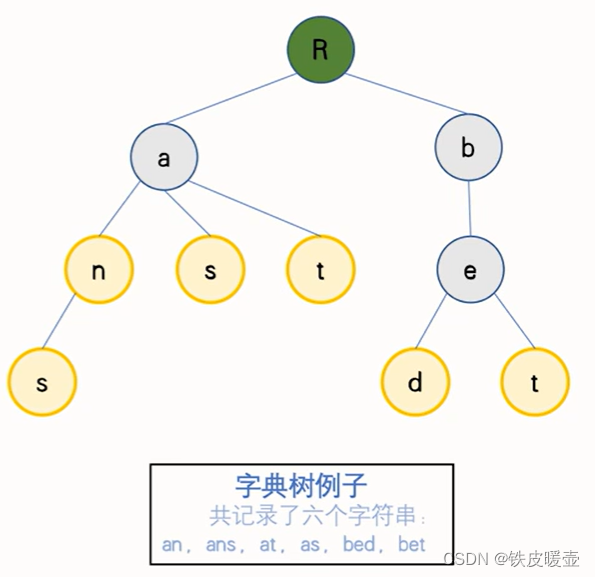
在向字典树中添加字符串时,如果一个字符串在某个节点结束,我们可以给这个节点打上一个标记(结尾或出现次数)。这样在后续访问时就可以知道到此节点为止是一个完成的字符串。
当然, 也可以在路径上的任何地方打标记, 进行信息统计。
沿路径记录信息
- 是否为单词结尾
- 是否为前缀
- 是否是某个数的位
注意son[N][M]数组第一维的大小
- 第一维是Trie树结点的个数
应该是数字或字符串的数量 n
×
\times
× 数字的最大位数或字符串的长度
第二维表示字符集的大小
-
01字典树
将一个数字的二进制高位到低位的值, 相邻位之间建立层次关系
每个结点最多有2个儿子, 取值为0/1
-
字符串字典树
注意Tire时一颗树, 当然可以做树可以做的东西: DFS等
插入操作
从根节点开始加入一条表示当前字符串的路径,在过程中如果没有对应的字符节点就新建一个。
因为字符串是一个特殊的顺序表, 其前驱和后继字符决定了字符串的形态
所以我们将原本的前驱后继, 转换为树中的父子关系
所以, 我们顺序的遍历字符串将每个字符作为当前结点p的儿子结点
void insert(string s) {
int p = 0;
// 对于当前字符s[i], p对应的字符就是s[i-1]对应的字符
for(int i = 0; i < s.size(); i++) {
int x = s[i] - 'a';
// 如果p没有x这个儿子, 则创建结点
if(!son[p][x]) son[p][x] = ++tot;
// 迭代到儿子
p = son[p][x];
}
isEnd[p] = true;
}
查询操作
bool find(string s) {
int p = 0;
for(int i = 0; i < s.size(); i++) {
int x = s[i] - 'a';
// 沿着当前字符串s, 在trie中无路可走
// 则说明s在这个字符串中没有完整出现过
if (!son[p][x]) return false;
p = son[p][x];
}
// 此时将s中所有字符都走完后
// 判断最后一个字符在trie中是否被标记为结尾
return isEnd[p];
}
模板
数组实现
const int N = 5e5+5;
const int M = 26; // 字符集大小
int son[N][M], tot;
int isEnd[N];
void insert(string s) {
int p = 0;
for(int i = 0; i < s.size(); i++) {
int x = s[i] - 'a';
if(!son[p][x]) son[p][x] = ++tot;
// 记录信息
// ...
p = son[p][x];
}
isEnd[p] = true;
}
bool find(string s) {
int p = 0;
for(int i = 0; i < s.size(); i++) {
int x = s[i] - 'a';
if (!son[p][x]) return false;
// 统计信息
// ...
p = son[p][x];
}
return isEnd[p];
}
指针实现
const int N = 5e5+5;
const int M = 26;
struct Node {
Node* son[M];
int isEnd;
// info...
} pool[N], *cur = pool, *root;
Node* newnode() {
return cur++;
}
int nodeSize() {
return cur - pool;
}
void insert(string s) {
Node* p = root;
for (auto ch : s) {
int x = ch - 'a';
if (!p->son[x]) p->son[x] = newnode();
p = p->son[x];
}
p->isEnd = true;
}
int find(string s) {
Node* p = root;
for (char ch : s) {
int x = ch - 'a';
if (!p->son[x]) return false;
p = p->son[x];
}
return p->isEnd;
}
void build() {
root = newnode();
}
习题
字典树例题
模板题
insert一个字符串时,标记结尾位置
find一个字符串时
- 如果能到结尾,就返回结尾位置的标记
- 如果到不了本身字符串结尾(最后一个字符), 说明要查询的字符串不存在
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 5e5+5;
const int M = 26; // 字符集大小
int son[N][M], tot;
int isEnd[N];
void insert(string s) {
int p = 0;
for(int i = 0; i < s.size(); i++) {
int x = s[i] - 'a';
if(!son[p][x]) son[p][x] = ++tot;
p = son[p][x];
}
isEnd[p] = true;
}
bool find(string s) {
int p = 0;
for(int i = 0; i < s.size(); i++) {
int x = s[i] - 'a';
if (!son[p][x]) return false;
p = son[p][x];
}
return isEnd[p];
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr); cout.tie(nullptr);
int n, m;
cin >> n;
while (n--) {
string s; cin >> s;
insert(s);
}
cin >> m;
while (m--) {
string s; cin >> s;
cout << find(s) << endl;
}
return 0;
}
前缀次数统计
给你 n 个字符串 s 1 , s_1, s1,和 m 组询问,每次询问一个字符串是 s 1 , s 2 , . . . , s n s_1, s_2, ..., s_n s1,s2,...,sn 中几个字符串的前缀。
某个字符串的前缀是指从这个字符串的第一个位置开始到某个位置结束的,前若干个字符组成的子串。
在insert一个字符串时, 对路径上的每个结点p, 都标记以p结尾的前缀出现次数+1
查询时, 返回结尾字符位置的前缀数量
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const static int N = 5e5+5;
const static int M = 26; // 字符集大小
int son[N][M], tot;
int isPre[N]; // 表示以结点i结尾的前缀在trie中出现次数
void insert(string s) {
int p = 0;
for(int i = 0; i < s.size(); i++) {
int x = s[i] - 'a';
if(!son[p][x]) son[p][x] = ++tot;
// 一个字符串能走到这个结点说明
// 这个以这个结点位结尾的前缀在原字典中出现过
isPre[p]++;
p = son[p][x];
}
isPre[p]++;
}
int find(string s) {
int p = 0;
for(int i = 0; i < s.size(); i++) {
int x = s[i] - 'a';
if (!son[p][x]) return false;
p = son[p][x];
}
return isPre[p];
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr); cout.tie(nullptr);
int n, m;
cin >> n;
while (n--) {
string s; cin >> s;
insert(s);
}
cin >> m;
while (m--) {
string s; cin >> s;
cout << find(s) << endl;
}
return 0;
}
前缀统计
给定N个字符串 S 1 , S 2 . . . S N S_1,S_2...S_N S1,S2...SN,接下来进行M次询问,每次询问给定一个字符串T,求 S 1 ~ S N S_1~S_N S1~SN中有多少个字符串是T的前缀。输入字符串的总长度不超过 1 0 6 10^6 106,仅包含小写字母。
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6+5;
const int M = 26;
typedef long long ll;
int son[N][M], tot;
int isEnd[N];
void insert(string s) {
int p = 0;
for(int i = 0; i < s.size(); i++) {
int x = s[i] - 'a';
if(!son[p][x]) son[p][x] = ++tot;
p = son[p][x];
}
// 只标记字符串结尾
isEnd[p]++;
}
int find(string s) {
int p = 0;
int ans = 0;
// 统计路径上的isEnd结点数量
// 以那些结点位结尾的前缀就是s的前缀
for(int i = 0; i < s.size(); i++) {
int x = s[i] - 'a';
if (!son[p][x]) break;
p = son[p][x];
ans += isEnd[p];
}
return ans;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr); cout.tie(nullptr);
int n, m;
cin >> n >> m;
while (n--) {
string s; cin >> s;
insert(s);
}
while (m--) {
string s; cin >> s;
cout << find(s) << endl;
}
return 0;
}
RemembertheWord
给出一个由S个不同单词组成的字典和一个长字符串。把这个字符串分解成若干个单词的连接(单词可以重复使用),有多少种方法?比如,有4个单词a, b,cd,ab,则abcd有两种分解方法:a+b+cd和ab+cd。
Trie+DP
对于字符串分解问题, 我们可以考虑以i开始的后缀能够分解的种类
定义f[i]表示, 以i开始的(包括i)后缀可以分解的方案数
边界状态f[n + 1] = 1, 表示以n + 1开始的后缀的分割方案数, 因为不存在该后缀, 所以方案为1
f
[
i
]
=
∑
j
=
i
n
f
[
j
+
1
]
f[i] = \sum\limits_{j = i }^{n} f[j + 1] \\
f[i]=j=i∑nf[j+1]
当s[i]...s[j]是以i开始的前缀时, 可以进行上面的转移
即从j和j+1之间将以i开始的前缀分割开
由于时因为每个位置的分割造成产生不同的方案, 所以总的方案时累加起来的
如果暴力枚举每个位置i(大字符串长300 000), 再暴力枚举每个小字符串(4000个)进行转移, 再加上还要判断每个小字符串是不是以i开始的后缀的前缀, 时间复杂度太大
考虑将S个小字符串构建为字典树
因为构造Trie的字符串长度都不超过100, 所以深度最大不超过100
所以我们从后向前枚举大字符串的位置i, 然后从该位置开始再Trie中查找字符串结尾, 如果查找到字符串结尾, 则一定是以i开始的后缀的前缀, 则可以根据Trie中的该前缀的长度更新f[i]
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int mod = 20071027;
const int N = 3e5+5;
const int M = 26; // 字符集大小
int n, son[401000][M], tot;
int f[N];
int isEnd[N];
void insert(string s) {
int p = 0;
for (auto ch : s) {
int x = ch - 'a';
if(!son[p][x]) son[p][x] = ++tot;
p = son[p][x];
}
isEnd[p] = true;
}
// 最多会执行100次
void find(string& s, int j) {
int p = 0;
for (int i = j; i <= s.size(); i++) {
int x = s[i] - 'a';
if (!son[p][x]) return;
p = son[p][x];
// 因为是从j开始遍历trie的
// 所以s[j]...s[i]在trie中出现过
// 就是表明s[j]..s[i] 是 s[j]..s[n]的前缀
// 因为s[i + 1]..s[n]这个后缀的f值已经算出
// 因为 s[j]..s[i]是前缀, 所以方案是1,
// 实际上 f[j] += 1 * f[i + 1]
if (isEnd[p]) {
f[j] += f[i + 1];
f[j] %= mod;
}
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr); cout.tie(nullptr);
string s;
int kase = 0;
while (cin >> s) {
cin >> n;
tot = 0;
memset(son, 0, sizeof(son));
memset(isEnd, false, sizeof(isEnd));
memset(f, 0, sizeof(f));
for (int i = 1; i <= n; i++) {
string t;
cin >> t;
insert(t);
}
int m = s.size();
s = " " + s;
f[m + 1] = 1;
for (int i = m; i >= 1; i--) {
find(s, i);
}
cout << "Case " << ++kase << ": "<< f[1] << endl;
}
return 0;
}
01-Trie
TheXORLargestPair
在给定的N个整数 A 1 , A 2 . . . , A N A_1, A_2...,A_N A1,A2...,AN中选出两个进行xor运算,得到的结果最大是多少?
N ≤ 1 0 5 , 0 ≤ A i ≤ 2 31 N\le10^5, 0\le A_i\le2^{31} N≤105,0≤Ai≤231。
异或知识: 两个bit相同异或为0, 相反异或为1
首先, 肯定不能暴力枚举两个数进行异或
我们可以把N个数的bit信息整合起来: 看看哪个位有什么选择
-
01字典树
将数字的二进制表示, 建立Trie树, 高位指向低位
树的深度由值域确定, 如果为
int整数, 则深度为30 -
贪心思想
要使得两个数字异或起来尽量大, 应该让它们对应位的尽量不同
先对N个数建01-Trie
遍历每个数a[i], 让它在Trie中进行Xor匹配: 即当前a[i]的位尽量与遍历的结点的值相异
- 如果相异, 则
a[i]的这一位可以保留, 则答案应该加上该位的位权, - 相同则贡献为0
- 直到在Trie中无路可走。
用a[i]的匹配的最大异或值更新答案
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 1e5+5;
int n, a[N];
// 每个数字都最多会创建30个结点(一条链)
int son[N * 30][2], tot;
void insert(int num) {
int p = 0;
for (int i = 30; i >= 0; i--) {
// 取出num的第i位
int bit = num >> i & 1;
if (!son[p][bit]) son[p][bit] = ++tot;
p = son[p][bit];
}
}
int findMaxXor(int num) {
int ans = 0;
int p = 0;
for (int i = 30; i >= 0; i--) {
// 取出num的第i位
int bit = num >> i & 1;
int xorBit = bit ^ 1;
if (son[p][xorBit]) {
p = son[p][xorBit];
ans += (1 << i);
} else {
if (son[p][bit]) p = son[p][bit];
else break;
}
}
return ans;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr); cout.tie(nullptr);
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> a[i];
insert(a[i]);
}
int ans = 0;
for (int i = 1; i <= n; i++) {
ans = max(ans, findMaxXor(a[i]));
}
cout << ans << endl;
return 0;
}
[CF760] D. Vasiliy’s Multiset
- 添加一个数就对路径上每个结点记录+1
- 因为是可重集合, 可能应该结点会被记录多次
- 删除一个数就对路径商每个结点记录-1
- 寻找与参数最大异或和上题一样
- 如果下一个结点是某个数的位的话,才能走过去
- 首先要把0加入到集合中
#include<iostream>
#include<algorithm>
#include<vector>
#include<cstring>
using namespace std;
#define _for(i,a,b) for(int i=(a);i<(b);i++)
#define _rep(i,a,b) for(int i=(a);i<=(b);i++)
typedef unsigned long long ULL;
typedef pair<int, int> PLL;
typedef long long ll;
const int P = 1e9+7;
const int N = 6e6+5;
const int INF = 0x3f3f3f3f;
int readint() {
int x;scanf("%d",&x);return x;
}
int trie[N][2], tot;
int isNum[N];
void add(int num) {
int p = 0;
for (int i = 31; i >= 0; i--) {
int bit = num >> i & 1;
if (!trie[p][bit]) trie[p][bit] = ++tot;
isNum[p]++;
p = trie[p][bit];
}
isNum[p]++;
}
void minuss(int num) {
int p = 0;
for (int i = 31; i >= 0; i--) {
int bit = num >> i & 1;
isNum[p]--;
p = trie[p][bit];
}
isNum[p]--;
}
int findMaxOr(int num) {
int ans = 0, p = 0;
for (int i = 31; i >= 0; i--) {
int bit = num >> i & 1;
int better = bit ^ 1;
int p1 = trie[p][better], p2 = trie[p][bit];
if (trie[p][better] && isNum[p1]) {
ans += (1 << i);
p = trie[p][better];
} else if (trie[p][bit] && isNum[p2]) {
p = trie[p][bit];
}
}
return ans;
}
int main() {
int q = readint();
add(0);
for (;q--;) {
char s[2];
int num;
scanf("%s%d", s, &num);
if (!strcmp(s, "+")) {
add(num);
} else if (!strcmp(s, "-")) {
minuss(num);
} else {
printf("%d\n", findMaxOr(num));
}
}
return 0;
}
最大异或和2
给你 n 个整数 a 1 , a 2 , . . . , a n a_1, a_2, ..., a_n a1,a2,...,an,请你从中选出一段连续的数字 a i , . . . , a j ( 1 ≤ i ≤ j ≤ n ) a_i, ...,a_j(1\le i \le j \le n) ai,...,aj(1≤i≤j≤n) ,使得这些数字异或起来值最大,请输出最大值。
对数组求前缀异或和
前缀异或和与前缀和类似
我们可以快速求得一个区间的异或和
a[l] xor ... xor a[r] = s[r] xor s[l - 1]
因为异或了一段重复的数, 所以重复部分抵消了
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 1e5+5;
int n, a[N], s[N];
int son[N * 30][2], tot;
void insert(int num) {
int p = 0;
for (int i = 30; i >= 0; i--) {
// 取出num的第i位
int bit = num >> i & 1;
if (!son[p][bit]) son[p][bit] = ++tot;
p = son[p][bit];
}
}
int findMaxXor(int num) {
int ans = 0;
int p = 0;
for (int i = 30; i >= 0; i--) {
// 取出num的第i位
int bit = num >> i & 1;
int xorBit = bit ^ 1;
if (son[p][xorBit]) {
p = son[p][xorBit];
ans += (1 << i);
} else {
if (son[p][bit]) p = son[p][bit];
else break;
}
}
return ans;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr); cout.tie(nullptr);
cin >> n;
// 某个数字本身也可能是最大值
// 如果不加入0, 所有前缀就不会被计算到
// 比如长度为i的签注, 对应长度为i的区间的左端点为0
// s[i] ^ 0 = s[i]
// s[1] s[2] s[3] s[4]
// s[1] ^ s[3] = a[2] ^ a[3]
// 0 ^ s[3] = a[1] ^ a[2] ^ a[3]
// a ^ a = 0
// a[l] xor ... xor a[r] = s[r] xor s[l - 1]
insert(0);
for (int i = 1; i <= n; i++) {
cin >> a[i];
s[i] = s[i - 1] ^ a[i];
insert(s[i]);
}
int ans = 0;
// 两个前缀异或后, 可以得到区间的异或和
// a = 1 ^ 2 ^ 3 ^ 4
// b = 1 ^ 2 ^ 3 ^ 4 ^ 5 ^ 6
// a ^ b = 5 ^ 6
for (int i = 1; i <= n; i++) {
ans = max(ans, findMaxXor(s[i]));
}
cout << ans << endl;
return 0;
}
DFS-Trie
字符串排序
给你 n 个两两不同的字符串,请按字典序从小到大的顺序将这些字符串排好,再按顺序输出。
把字符串按字典序排序是指以字符串的第
i个字符作为第i关键字进行的排序,空字符小于字符集内任何字符。
对Trie树进行字典序从小到大的DFS遍历, 遍历到字符串终点后输出字符串
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 5e5+5;
const int M = 26;
int son[N][M], tot;
int isEnd[N];
void insert(string s) {
int p = 0;
for (auto ch : s) {
int x = ch - 'a';
if(!son[p][x]) son[p][x] = ++tot;
p = son[p][x];
}
isEnd[p]++;
}
// ans维护当前路径上经过的字符结点
string ans;
void dfs(int u) {
// 如果某个结点u是字符串结尾
// 则说明在字典中该字符串出现了isEnd次
// 因为是按字典序dfs, 所以当前遍历到的字符串是目前最大的, 可以直接输出
if (isEnd[u]) {
for (int i = 1; i <= isEnd[u]; i++) {
cout << ans << endl;
}
}
// 按字典序dfs
for (int v = 0; v < 26; v++) {
if (son[u][v]) {
ans.push_back(v + 'a');
// son[u][v] 才是u的值为v的儿子编号
dfs(son[u][v]);
// 回溯后, 刚才经过的结点现在不算经过了
ans.pop_back();
}
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr); cout.tie(nullptr);
int n;
cin >> n;
while (n--) {
string s;
cin >> s;
insert(s);
}
dfs(0);
return 0;
}
第k大前缀
给你 n 个字符串 s 1 , s 2 , . . . , s n s_1, s_2, ...,s_n s1,s2,...,sn,对于第 i 个字符串 𝑠**𝑖��,有 ∣ s i ∣ |s_i| ∣si∣个前缀。现在我们要把所有这 n个字符串的所有前缀按字典序大小排序,请求出字典序第 k 大的前缀。
- 建好Trie树
- 点权就是一个前缀作为串的前缀的ci
- 在Trie树中找到点权和在一定范围内的路径
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 1e6+5;
const int M = 26; // 字符集大小
int n, k, cnt;
int son[N][M], tot;
int isPre[N];
void insert(string s) {
int p = 0;
for (auto ch : s) {
int x = ch - 'a';
if(!son[p][x]) son[p][x] = ++tot;
p = son[p][x];
// p是字符串所有前缀的编号
// 统计前缀次数
isPre[p]++;
}
}
// dfs第k个前缀
// cnt用来统计当前经过的前缀数
// 如果统计当前结点过后, 当前经过的前缀数>=k
// 则说明以当前结点位结尾的前缀就是第k大的前缀
string ans;
void dfs(int u) {
if (cnt >= k) return;
cnt += isPre[u];
if (cnt >= k) {
cout << ans << endl;
return;
}
for (int x = 0; x < 26; x++) {
if (son[u][x]) {
ans.push_back(x + 'a');
dfs(son[u][x]);
ans.pop_back();
}
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr); cout.tie(nullptr);
cin >> n >> k;
for (int i = 1; i <= n; i++) {
string s;
cin >> s;
insert(s);
}
dfs(0);
return 0;
}
LCA
最长公共前缀问题
给你 n 个字符串 s 1 , s 2 , . . . , s n s_1, s_2,...,s_n s1,s2,...,sn 和 m 组询问,每次询问读入两个数 x, y,请求出 s x s_x sx 和 s y s_y sy 的最长公共前缀的长度。
两个字符串 a, b 的最长公共前缀是指:找到最大的整数 k ( k ≥ 0 ) k(k \ge0) k(k≥0),满足 a和 b 的前 k 个位置的字符完全一样,a 和 b 的前 k 个位置的字符组成的子串就是 a, b 的最长公共前缀。
因为询问公共前缀的的字符串都是在集合里面的
所以对字符串集合建Trie树, 并标记每个字符串对应的结点编号
对于每个查询给出的两个字符串a, b,先获取到其在Trie树中的位置
然后求两个结点的LCA, LCA的深度就是它们的最长公共前缀, 因为一个结点的深度表示了以它为结尾经过的字符个数
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 5e5+5;
const int M = 26; // 字符集大小
int son[N][M], tot;
int endPos[N];
int f[N][21], depth[N];
void insert(string s, int i) {
int p = 0;
for (auto ch : s) {
int x = ch - 'a';
if(!son[p][x]) {
son[p][x] = ++tot;
// 初始化父子信息和深度信息
f[tot][0] = p;
depth[tot] = depth[p] + 1;
}
p = son[p][x];
}
endPos[i] = p;
}
void lca(int u, int v) {
// 通过字符串编号获取到在Trie树中的编号
u = endPos[u], v = endPos[v];
if (depth[u] < depth[v]) swap(u, v);
// 拔到同一高度
int d = depth[u] - depth[v];
for (int i = 0; d; d >>= 1, i++) {
if (d & 1) {
u = f[u][i];
}
}
if (u != v) {
for (int i = 20; i >= 0; i--) {
if (f[u][i] != f[v][i]) {
u = f[u][i], v = f[v][i];
}
}
u = f[u][0];
}
cout << depth[u] << endl;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr); cout.tie(nullptr);
int n; cin >> n;
for (int i = 1; i <= n; i++) {
string s;
cin >> s;
insert(s, i);
}
// 结点个数有tot个, 而不是n个
for (int i = 1; i <= tot; i++) {
for (int j = 1; j <= 20; j++) {
f[i][j] = f[f[i][j - 1]][j - 1];
}
}
int m; cin >> m;
while (m--) {
int u, v;
cin >> u >> v;
lca(u, v);
}
return 0;
}

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









