




 本文介绍了不同特征金字塔构造方法,包括用图像金字塔构造、单一尺度特征图检测、利用不同层次特征图预测等。重点阐述了作者提出的特征金字塔网络FPN,其结构含从底向上、从顶向下通路和横向连接,能融合不同分辨率和语义强度特征,且几乎不增加额外计算量。
本文介绍了不同特征金字塔构造方法,包括用图像金字塔构造、单一尺度特征图检测、利用不同层次特征图预测等。重点阐述了作者提出的特征金字塔网络FPN,其结构含从底向上、从顶向下通路和横向连接,能融合不同分辨率和语义强度特征,且几乎不增加额外计算量。
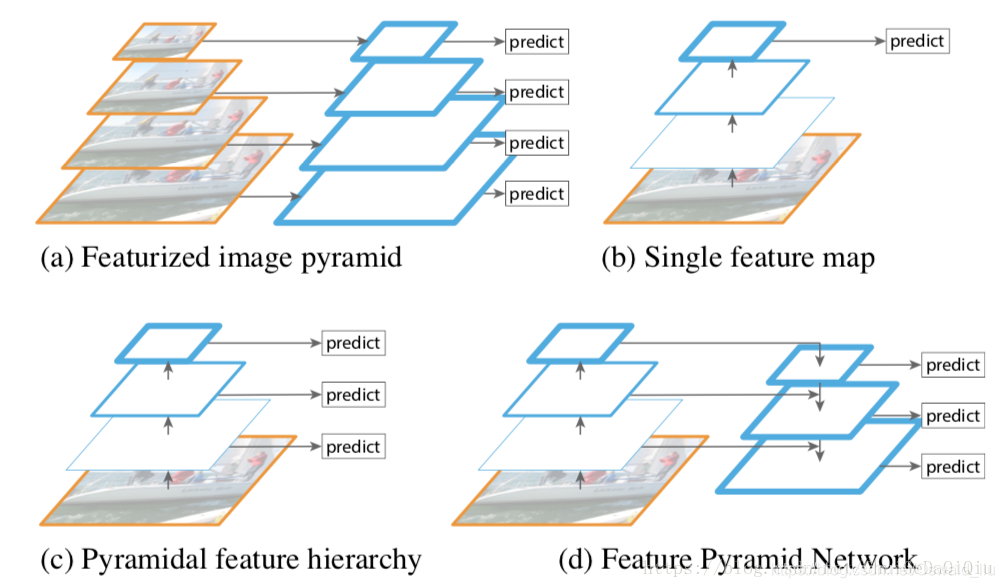
图1(a)表示使用图像金字塔来构造特征金字塔,每一张图像都会独立地计算出它的特征。速度慢,消耗大量显存。
(b)表示利用单一尺度的特征图做目标检测,典型的是SPP-Net、Fast R-CNN和Faster R-CNN等,这些网络将原图通过卷积神经网络生不同层次的特征图,但是检测系统基于最后一层特征图。
©是利用了原图经过卷积神经网络在不同层次生成的特征图进行预测,而不仅限于最后一层。SSD 检测框架采用了类似的思想。这样的方法问题在于直接强行让不同层学习同样的语义信息。而对于卷积神经网络而言,不同深度对应着不同层次的语义特征,浅层网络分辨率高,学的更多是细节特征,深层网络分辨率低,学的更多是语义特征。
(d)是作者在论文中提出的特征金字塔网络即FPN(Feature Pyramid Network)。网络直接在原来的单网络上做修改,每个分辨率的 feature map 引入后一分辨率缩放两倍的 feature map 做 element-wise 相加的操作。通过这样的连接,每一层预测所用的 feature map 都融合了不同分辨率、不同语义强度的特征,融合的不同分辨率的 feature map 分别做对应分辨率大小的物体检测。这样保证了每一层都有合适的分辨率以及强语义特征。同时,由于此方法只是在原网络基础上加上了额外的跨层连接,在实际应用中几乎不增加额外的时间和计算量。
FPN
FPN结构包含三大要素:从底向上的通路(bottom-up pathway)、从顶向下的通路(top-down pathway)和横向连接(lateral connection)。下图中放大的区域就是横向连接,这里1*1的卷积核的主要作用是减少卷积核的个数,也就是减少了feature map的个数,并不改变feature map的尺寸大小。
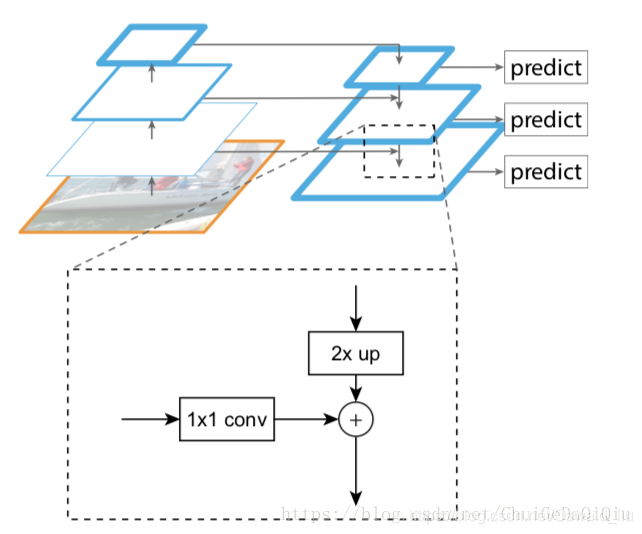
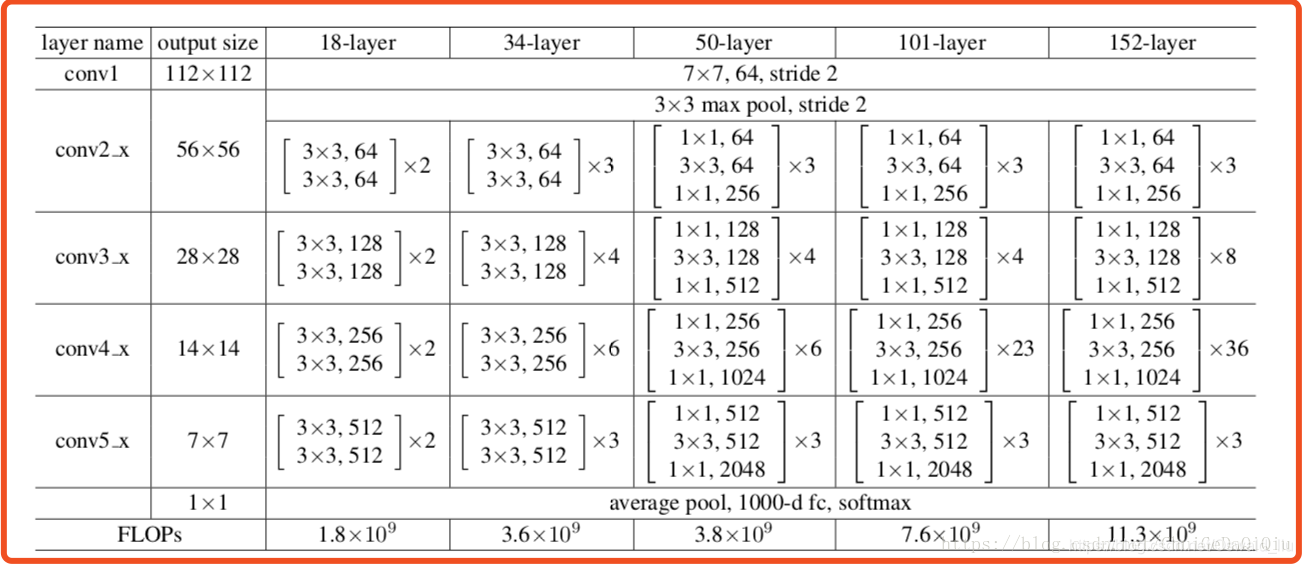
从底向上的路径,也就是前向传播的计算路径。把产生相同大小特征图的几个层称之为一个网络阶段(stage),每个阶段的最后一层特征图作为参考。举一个resnet-50的例子,resnet-50的conv2、conv3、conv4、conv5内含多个"bottleblock"结构,那么把conv2至conv5中最后一个block输出特征图称作{C2,C3,C4,C5},并且它们相对输入图象的步长依次为{4,8,16,32}像素。
特征金字塔高层特征图分辨率相比较低,但语义性更强,对高层特征图进行从顶向下的上采样,并和从底向上的特征图进行合并(lateral connection),从底向上的特征图要能够合并的话需要经过1x1的卷积层以减少通道数,因为这里的合并是元素的相加,所以要保证要合并的特征图尺寸是一致的,无论是大小还是通道数。合并后的特征图还要再经过一个3x3的卷积操作来生成最终的特征图,这么做是为了减少混叠效应(什么东东?)。所以最终的特征图集合称为{P2,P3,P4,P5},对应到{C2,C3,C4,C5},它们对应的尺寸是相同的。
















 6066
6066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









