




 本文详细剖析了ConcurrentHashMap的实现原理,包括并发增加元素、数据迁移、链表转红黑树等关键优化策略,以及1.7版与1.8版底层设计的对比。深入探讨了sizeCtl、resizeStamp等核心机制,揭示了ConcurrentHashMap在高并发场景下的高效表现。
本文详细剖析了ConcurrentHashMap的实现原理,包括并发增加元素、数据迁移、链表转红黑树等关键优化策略,以及1.7版与1.8版底层设计的对比。深入探讨了sizeCtl、resizeStamp等核心机制,揭示了ConcurrentHashMap在高并发场景下的高效表现。
一、内容要点
1.通过数组的方式实现并发增加元素的个数(不用加锁,减少性能消耗)
2.并发扩容,可通过多个线程实现数据迁移
3.采用高低位链的方式解决多次hash计算的问题,提升了效率
4.sizeCtl的设计,3种表示状态
5.resizeStamp的设计,高低位的设计实现唯一性以及多个线程的协助扩容
二、底层设计结构
1.7版
ConcurrentHashMap由一个个Segment组成,其内部也即是一个Segment数组,通过继承ReentrantLock进行加锁,通过锁住单个Segment保证Segment内操作的线程安全,进而实现全局的安全性。
1.8版改进
1.将原来的Segment分段设计改为Node数组来保存数据,并且采用 Node 数组元素作为锁来实现每一行数据进行加锁来进一步减少并发冲突的概率。
2.将数组+链表结构改为数组+链表+红黑树。链表复杂度为O(n),红黑树复杂度为O(log n),查询性能上优化了。
当链表长度为8时,会通过扩容或者将链表转换为红黑树(如果长度没有64位,则优先扩容)。
三、代码分析
1.putValue()
计算hash值,如果数组为空则初始化,默认长度为16。然后再计算下次扩容临界值(超过该值则扩容),为当前容量的0.75倍。
通过(n - 1) & hash 方式取得某个位置的值是否为null,若为null则CAS方式将新值封装成Node插入;若CAS失败则存在竞争进入下次循环。
initTable()初始化数组
sizeCtl,这个标志是在 Node 数组初始化或者扩容的时候的一个控制位标识,负数代表正在进行初始化或者扩容操作。
- -1,代表正在初始化。
- -N,代表有 N-1 个线程正在进行扩容操作,这里不是简单的理解成 n 个线程,sizeCtl 就是-N。
- 0,标识 Node 数组还没有被初始化,正数代表初始化或者下一次扩容的大小。
sizeCtl = sc = n - (n >>> 2); // 计算下次扩容的临界值大小,实际就是当前容量的0.75倍
= n * 0.75
2..addCount()
在putVal方法执行完成以后,会通过addCount来增加ConcurrentHashMap中的元素个数,并且还会可能触发扩容操作。这里有两个非常经典的设计:
1)如何保证 addCount 的数据安全性以及性能。
2)高并发下的扩容。
3.CounterCell
使用CounterCell数组,每一个数组元素对应一个节点,记录每个节点存放元素的个数,最后通过遍历CounterCell数组元素,将每个元素对应数值相加得到size大小,总值等于数组中每个cell分值之和(分而治之思想)。
baseCount,记录个数的属性。
fullAddCount ()分析
fullAddCount 主要是用来初始化 CounterCell,来记录元素个数,里面包含扩容,初始化等操作。
cellBusy属性,标识是否初始化,0说明未开始初始化;初始化长度为 2 的数组,然后随机得到指定的一个数组下标,将需要新增的值加入到对应下标位置处。
4.transfer 扩容阶段
判断是否需要扩容,也就是当更新后的键值对总数 baseCount >= 阈值 sizeCtl 时,进行rehash,这里面会有两个逻辑。
1)如果当前正在处于扩容阶段,则当前线程会加入并且协助扩容
2)如果当前没有在扩容,则直接触发扩容操作
resizeStamp
resizeStamp 用来生成一个和扩容有关的扩容戳。
static final int resizeStamp(int n) {
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
Integer.numberOfLeadingZeros 这个方法是返回无符号整数 n 最高位非 0 位前面的 0 的个数。
比如 10 的二进制是 0000 0000 0000 0000 0000 0000 0000 1010,那么这个方法返回的值就是 28。
下面推演扩容的代码逻辑:
1.假设数组长度n=16,16的二进制
0000 0000 0000 0000 1000 0000 0001 1100
2.U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)
rs 左移 16 位,相当于原本的二进制低位变成了高位
1000 0000 0001 1100 0000 0000 0000 0000
3.然后再 +2 变为
1000 0000 0001 1100 0000 00000000 0010
表示有一个线程在扩容
高 16 位代表扩容的标记、低 16 位代表并行扩容的线程数
1)保证每次扩容的扩容戳是唯一的
2)支持并发扩容
可以理解为在16(数组长度)这个扩容周期内,有n个线程参与扩容。
transfer作用
1)扩大数组长度
2)数据迁移
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
将 n>>>3 相当于 n/8,然后除以 CPU 核心数。如果得到的结果小于 16,那么就使用 16。
这里的目的是让每个 CPU 处理的桶一样多,避免出现转移任务不均匀的现象,如果桶较少的话,默认一个 CPU(一个线程)处理 16 个桶,也就是长度为 16 的时候,扩容的时候只会有一个线程来扩容。
5.数据迁移
(bound,i)通过边界和i去跟踪该区域处理,逆序从后往前迁移,若i位置为null,则设置fwd标志,表示该节点迁移完毕。当某个节点在做迁移时会用锁锁住保证迁移正常进行,当迁移完毕设置fwd标志,下一个进来的线程会跳过该节点。
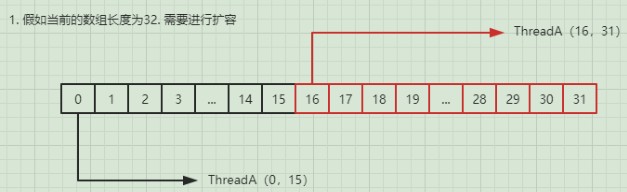
(16, 31)表示bound边界为16,逆序操作i从31下标开始往前执行,(0, 15)同理。
迁移过程遇到某个节点链表满8的情况,采用高低位方式迁移到新的节点队列中。
高低位扩容原理
通过(n-1) & hash 运算对链表分类,分成ln(low node)低位链和hn(high node)高位链。低位链保持不变,高位链增加一个数组长度作为迁移后的位置。
n,当前数组长度。
1)通过高低位分类后,不需要在每次扩容的时候重新计算hash,提升了效率
2)数据迁移后还能通过同样的操作(n-1) & hash 取得值
链表转换红黑树
判断链表的长度是否已经达到临界值 8. 如果达到了临界值,这个时候会根据当前数组的长度来决定是扩容还是将链表转化为红黑树。也就是说如果当前数组的长度小于 64,就会先扩容。否则,会把当前链表转化为红黑树。

















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









