







 该博客介绍了UP-DETR,一种用于对象检测Transformer的无监督预训练方法。受到Transformer在NLP领域的成功启发,UP-DETR通过随机查询补丁检测任务对DETR进行预训练,解决多任务学习和多查询定位问题。预训练过程中,通过固定CNN骨干并添加补丁特征重建分支来平衡定位和分类任务,同时采用对象查询shuffle和注意力掩码实现多查询定位。这种方法使DETR能够无监督地定位输入的patch,无需额外的NMS后处理。
该博客介绍了UP-DETR,一种用于对象检测Transformer的无监督预训练方法。受到Transformer在NLP领域的成功启发,UP-DETR通过随机查询补丁检测任务对DETR进行预训练,解决多任务学习和多查询定位问题。预训练过程中,通过固定CNN骨干并添加补丁特征重建分支来平衡定位和分类任务,同时采用对象查询shuffle和注意力掩码实现多查询定位。这种方法使DETR能够无监督地定位输入的patch,无需额外的NMS后处理。
/1 UP-DETR: Unsupervised Pre-training for Object Detection with Transformers(无监督预训练检测器)
paper:https://arxiv.org/pdf/2011.09094.pdf
使用Faster R-CNN,通过一种Transformer编码器-解码器架构,使得Object Detection with Transformers(DETR)达到了更好的竞争性能。受Pre-training Transformer在自然语言处理中取得巨大成功的启发,我们提出了一种基于随机查询补丁检测(random query patch detection )的无监督预训练Transformer(UP-DETR)针对对象检测任务。具体来说,我们从给定的图像中随机裁剪小块,然后将它们作为查询提供给解码器。对该模型进行预训练,从原始图像中检测这些查询补丁。在训练前,我们解决了两个关键问题:多任务学习(是否可用于多个结果的着色)和多查询定位。(1)为了权衡pretext任务中的分类和定位偏好,我们冻结(freeze)了CNN骨干,提出了一个与补丁检测联合优化的补丁特征重建分支。(2)为了实现多查询定位,我们从单一查询补丁中引入了UP-DETR,并将其扩展为具有对象查询shuffle和注意掩码的多查询补丁。
无监督预训练模型无论是在nlp还是在cv上都取得了突破性的进展。而对于无监督预训练而言,最重要的就是设计一个合理的pretext,典型的像masked language model,instance discrimination(概念)。他们都通过一定的方式,从样本中无监督的构造了一个"label",从而对模型进行预训练,提高下游任务的表现。回到我们的UP-DETR,对于DETR而言,既然CNN可以是无监督预训练的,那么transformer能不能也无监督预训练一下呢。这就是motivation。
但是对于现有的pretext任务,似乎都不太适合于DETR里transformer的预训练。比如,我们类似masked language model,构造一个patch的mask到图片里。可cv都是连续像素构成语义,没法像nlp天然有个离散的token的概念,到最后还可能训成一个mask检测器。直接把MoCo那一套对比学习搬过也不太可行。我们认为主要的原因是DETR中的transformer主要是用来做空间信息上的定位而MoCo那一套主要是用来提高CNN的instance discrimination。
更重要的是,无监督预训练检测器,这听起来就很违背自觉,因为是不是object某种意义上明明就是人为定义的。所以,我们换了一个思路,提出了一个叫random query patch detection的pretext,具体而言就是从原图中,我们随机的框若干个patch下来,把这些patch输入到decoder,原图输入到encoder,然后整个任务就变成了给定patch找他们在原图中的位置。最后,对于一个无监督训好的DETR,只要输入patch,它天然就能做到如下图的无监督定位patch的功能(不需要额外的nms后处理),当然这个patch还能支持数据增强和尺度变换。从这个预训练任务的角度来说,一个patch是不是object本身没有任何先验。

但具体实现上,我们其实遇到了两个主要的问题,在paper里,我们把它们总结为:multi-task learning和multi-query localization。
(1)对于multi-task learning,主要是由于目标检测其实本身就带有定位和分类两个任务,这两个任务对特征其实有着不同的偏好。这其实在之前许许多多工作中都有大佬提到了,因此许多目标检测的工作通常会设计了两条不同的分支(带有额外卷积结构)分别对应于分类和回归。而detr其实完全共享了同一组特征,在实验中,我们发现如果只做patch的定位,不管分类的话,UP-DETR迁移到voc上效果会不好。这意味着定位和分类,特征偏好上确实是有冲突的。所以,为了在预训练中权衡这两个任务的偏好,我们固定了预训练好的CNN权重,新增了一个叫patch feature reconstruction的分支。motivation就是希望经过transformer的特征能保持和经过CNN后的特征一致的分类判别性。
(2)对于multi-query localization,主要是说对于DETR,decoder其实有100个object query,这100个object query其实是100个网络隐式学到的空间位置偏好的embedding。我们实际上是随机搞了M个query patch,因为patch可能会在任意位置,直觉上得一个patch加到多个object query上,所以我们讨论了一下如何在预训练过程中,把这M个query patch分配到100个embedding上去。我们从最简单的single-query开始介绍,把它拓展到了支持multi-query的预训练。对于multi-query,我们认为有两个要满足的条件,第一个是 query之间框的预测是独立的,所以我们提出了一个放在decoder上的attention mask,保证query之间彼此不可见。第二个是100个object query应当尽可能避免人为先验的分组,因为下游任务中,它其实并没有显式的分组。所以,我们提出了object query shuffle的方法去达到这种分配的随机性。
解决了这俩问题,UP-DETR的预训练过程如下图所示,除此之外,下游目标检测的微调是和训DETR一模一样的:
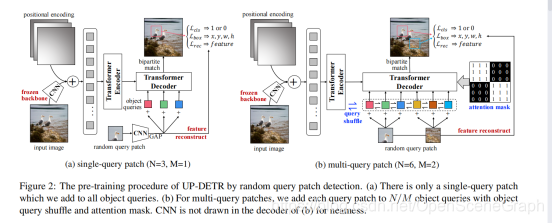
采用随机查询补丁检测的UP-DETR预处理过程。(a)只有一个单一查询补丁,我们添加到所有对象查询。(b)对于多查询补丁,我们将每个查询补丁添加到N/M个具有对象查询shuffle和注意掩码的对象查询中。为了整洁,CNN没有在(b)的解码器中绘制。

















 84
84

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









