




评估 AI 生成内容的质量对于衡量模型能力和指导模型优化至关重要。然而,现有的大多数质量评估数据集和模型仅提供单一的质量分数,这种结果过于粗粒度,难以为生成式模型改进提供有针对性的指导。
在当前的 AI 图像生成应用中,“真实感(Realism)”和“合理性(Plausibility)”是两项关键维度。随着统一生成—理解模型的出现,沿这两个维度进行细粒度评测对于提升生成效果尤为重要。
近日,上海人工智能实验室联合团队发布了最新研究成果 Q-REAL,针对这一领域展开了探索。
核心贡献:
-
提出 Q-Real:首个基于真实感与合理性两个维度构建的、用于 AI 生成图像细粒度质量评估的数据集,并采用自动化标注流程构建。
-
提出 Q-Real Bench:由 ObjectQA 与 ImageQA 组成的全面评测基准,系统考察 MLLMs 在细粒度质量判断中的真实感与合理性能力。
-
提出任务定制微调框架:并在多种多模态大语言模型(MLLM)上验证其有效性,进一步证明了数据集的高价值与评测体系的全面性。

论文链接:
https://arxiv.org/pdf/2511.16908
该工作目前已在司南 Daily Benchmark 专区上线
https://hub.opencompass.org.cn/daily-benchmark-detail/2511%2016908
-
AI 评测论文“追更神器”
-
每日更新最新 AI 评测方向论文
-
每篇论文都支持 AI 智能解读
查看更多最新 AI 评测论文,欢迎访问:
https://hub.opencompass.org.cn/daily-benchmark-list
Q-Real 数据集
构建高质量的数据集对于支持模型在真实感与合理性两个维度上进行细粒度评估至关重要。然而,基于主观描述进行大规模标注往往成本高、耗时长。为此,研究团队设计了一套结合自动化标注与人工校验的混合式标注策略,如下图所示。
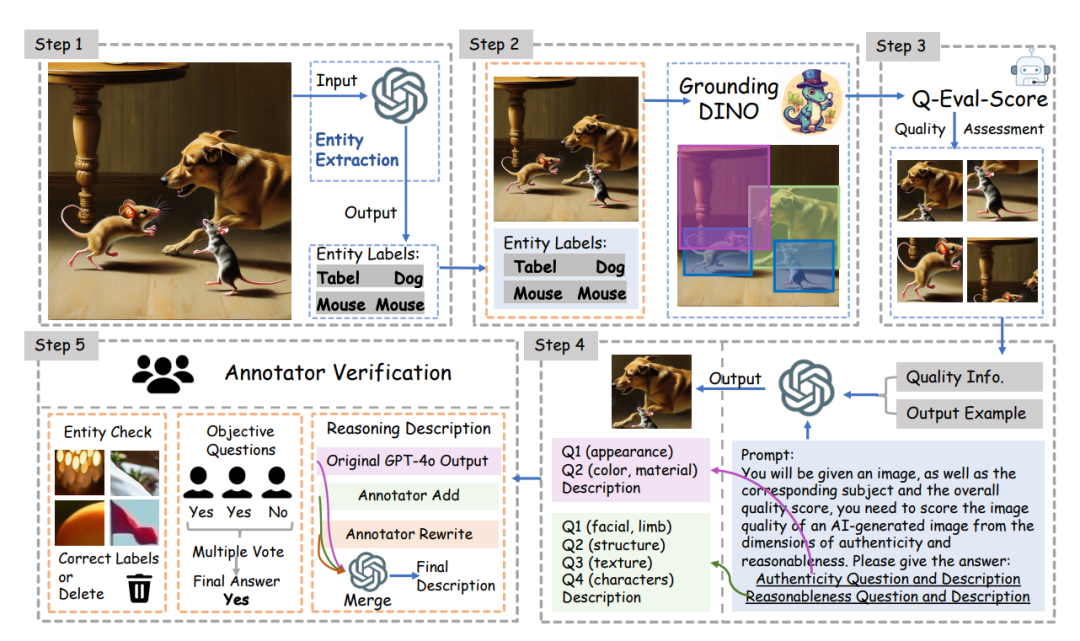
为提升数据集的质量与多样性,从而增强 MLLM 在细粒度质量评估任务上的能力,研究团队采用了多种先进的文生图生成模型,同时,设计的提示词涵盖丰富的实体类别(如人物、动物、物体)、视觉属性(颜色、纹理、材质),以及多样的物理交互与上下文关系。
基于上述模型和提示词,共生成 3,088 张 AI 生成图像,获得 17,879 个实体。每个实体都包含客观与主观两类质量标注:
-
真实感:2 道选择题 + 推理描述
-
合理性:4 道选择题 + 推理描述
每道客观题和主观描述均由三名标注员参与校验,以确保标注质量。最终,数据集共包含 429,096 条高质量标注,覆盖真实感与合理性两个核心维度。
Q-Real Bench
为了评估模型在 Q-Real 上的表现,研究团队构建了基准测试集 Q-Real Bench,从 Q-Real 数据集中选取了 400 张不同类型与质量的图像。基于此基准,从 ObjectQA 与 ImageQA 两个方向评估模型能力,如下图所示。
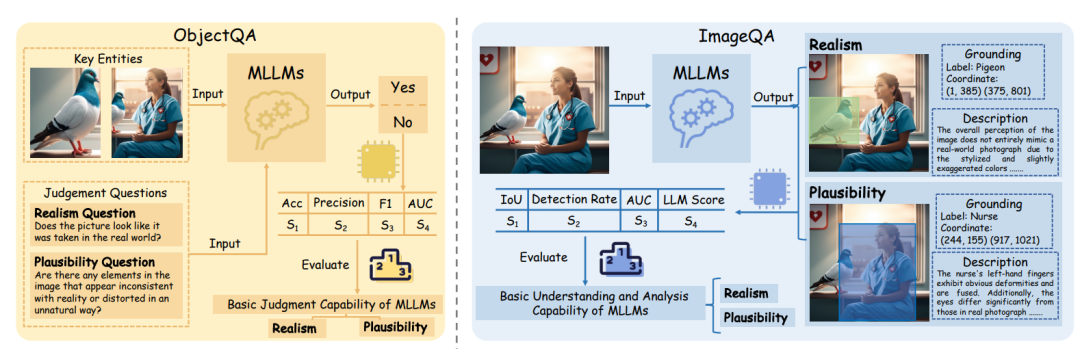
Q-Real Bench 概览
ObjectQA 旨在评估模型对 AI 生成图像中关键实体的真实感与合理性的基本判断能力。
ImageQA 要求模型对整张图像进行细粒度分析,包括:定位存在问题的关键实体;给出其真实感与合理性方面的推理描述。
面向任务的精调方法:用于细粒度质量评估
由于当前 MLLM 在评估 AI 生成图像的真实感与合理性方面仍存在能力不足,如果直接采用单一模型同时进行细粒度判断、定位与描述,往往难以取得理想效果。因此,研究团队针对 Q-Real Bench 中两个互补的任务——ObjectQA 与 ImageQA——采用了面向任务的精调策略,并构建了相应的训练数据集,如下图所示。
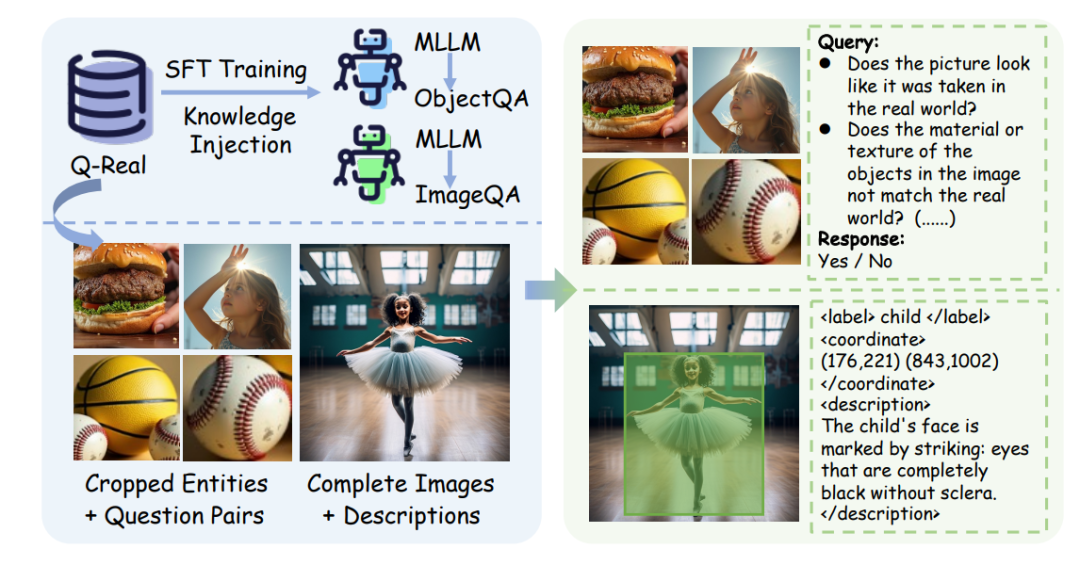
用于 ObjectQA 与 ImageQA 任务的不同精调数据集的数据格式
ObjectQA 精调
对于 ObjectQA 任务,使用从数据集中提取的每个关键实体,以及其对应的 6 个关于真实感与合理性的问答对,对 MLLM 进行精调。
ImageQA 精调
对于 ImageQA 任务,构建的训练数据包含完整的 AI 生成图像、实体坐标,以及对应的详细推理描述。
通过构建面向特定任务的数据集并分别对 MLLM 进行精调,显著提升了模型在真实感判断、问题区域定位以及细粒度合理性分析方面的能力。该面向任务的精调框架有效增强了模型在 AI 生成图像质量评估场景中的表现。
实验介绍
研究团队在四个预训练多模态模型上开展实验:Qwen2.5VL-7B、InternVL2.5-8B、llava-v1.6-mistral-7B 和 GPT-4o 。 对于前三个开源 MLLM,在未经过精调和基于 Q-Real 训练集使用任务特定精调框架进行精调后的两种设置下进行评估,对于 GPT-4o,仅在 Q-Real Bench 上直接测试其性能,不进行额外设置。
主要发现
ObjectQA
现有 MLLM 在判断 AI 生成图像的真实感与合理性方面能力有限,Acc 与 F1 均不高,尤其是在判断对象是否真实或是否失真时表现不稳定。
在使用 Q-Real 精调后,准确率与 F1 均有显著提升,两者均超过 0.7,说明模型在真实感与合理性理解上的能力获得有效增强。
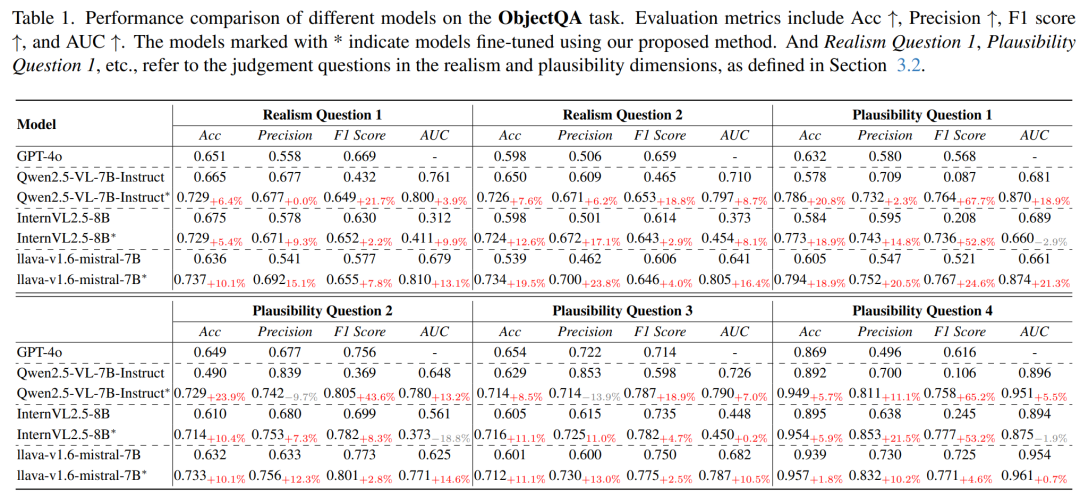
不同模型在 ObjectQA 任务上的性能比较
ImageQA
现有 MLLM 在 ImageQA 上表现更差:
-
在基础定位(grounding)能力上,模型对存在问题的区域定位主要依赖自身固有 grounding 能力,而它们普遍缺乏对 AI 生成内容真实感与合理性的分析能力。
-
模型倾向于输出用户生成内容中常见的低层次视觉瑕疵,而非真正理解 AI 合成图像的真实性问题。
-
在细粒度人体合理性注释上表现更弱,LLM Score 甚至低于 0.2。
精调后,所有模型均有显著提升,尤其在推理描述维度:
-
真实感描述的 LLM Score 超过 0.7
-
合理性描述接近 0.6
-
在更具挑战性的细粒度人类合理性测试集上得分达到 0.5,已具有实际应用价值
Grounding 能力也同步提升,尤其是对 InternVL2.5-8B 这类原本 grounding 能力较弱的模型,IoU 与检测率几乎翻倍。
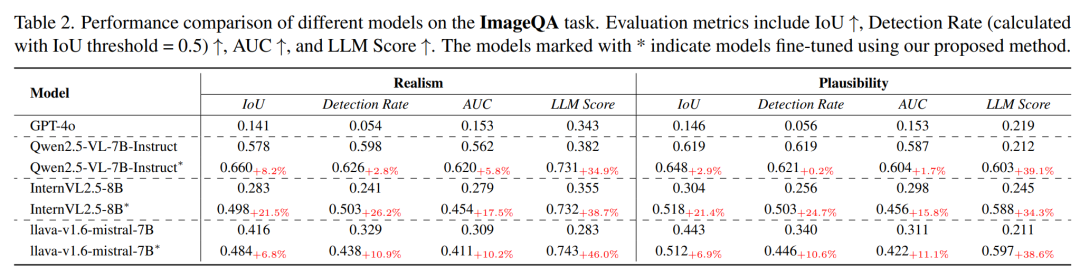
不同模型在 ImageQA 任务上的性能比较
这些结果表明:
当前 MLLM 在评估 AI 生成图像真实感与合理性方面仍存在明显不足,而 Q-Real 数据集与面向任务的精调策略能显著提升其分析能力。
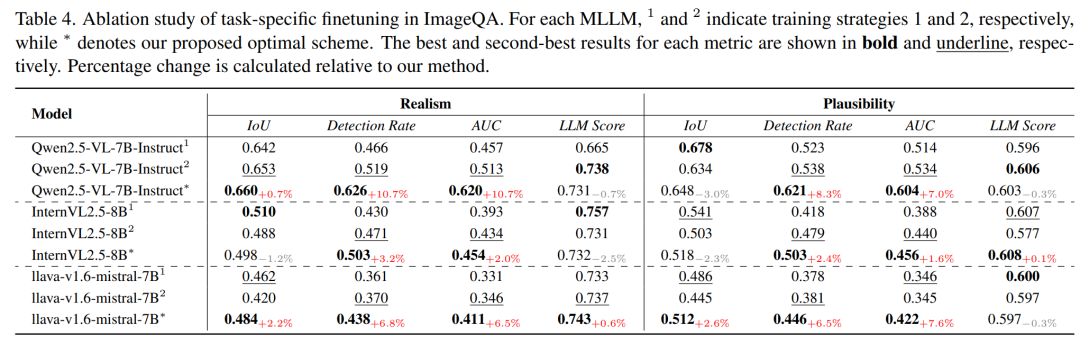
消融实验
研究团队在 ImageQA 任务上进行了消融实验,用以验证所提出的任务特定精调框架的有效性,并将其与两种替代方案进行比较(结果见下表)。
两种替代策略如下:
1. 分解式多步骤方法
将 ImageQA 分解为三个子任务:实体检测;实体筛选;推理描述生成。
分别构建训练集并精调模型,再将模型组合为一个执行流水线式推理的 agent。
2. 先 ObjectQA 再 ImageQA 的二阶段统一模型
先使用 ObjectQA 数据进行精调,使模型获得基本判断能力,再进一步训练其执行 ImageQA。
结果分析
研究团队提出的任务特定精调方法在整体性能上优于上述两种替代方案,尤其在 grounding 能力上表现更为突出,同时在推理描述的准确性上保持了相近水平。
其优势主要来自:
-
该框架避免了多模块误差传播。
-
而方法 1 和方法 2 均将 grounding 和问题实体判断拆成多步骤,导致前一模块的错误会传递到下一模块,影响最终性能。
因此,在对 MLLM 进行复杂任务精调时,合理的任务拆解策略及相应训练数据构建至关重要。
总结
在本工作中,研究团队提出了 Q-Real,首个专注于 AI 生成图像真实感与合理性细粒度质量评估的数据集。同时,构建了 Q-Real Bench,用于系统评测模型在多维度任务中的能力。
在此基础上,研究团队使用 Q-Real 和提出的任务特定训练方法对多个现有 MLLM 进行了精调。
实验结果表明:Q-Real 数据集显著提升了模型对 AI 生成图像的细粒度理解与分析能力,并在 Q-Real Bench 上取得优异表现。

















 2435
2435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









