




强化学习(Reinforcement Learning,简称RL)是人工智能中让机器通过“试错”方式自主学习决策的技术,核心思想是智能体(Agent)在环境中探索行动,依据奖励信号调整策略,以实现长期利益最大化。RL正成为自动驾驶、游戏AI、机器人控制等领域的“智力引擎”。
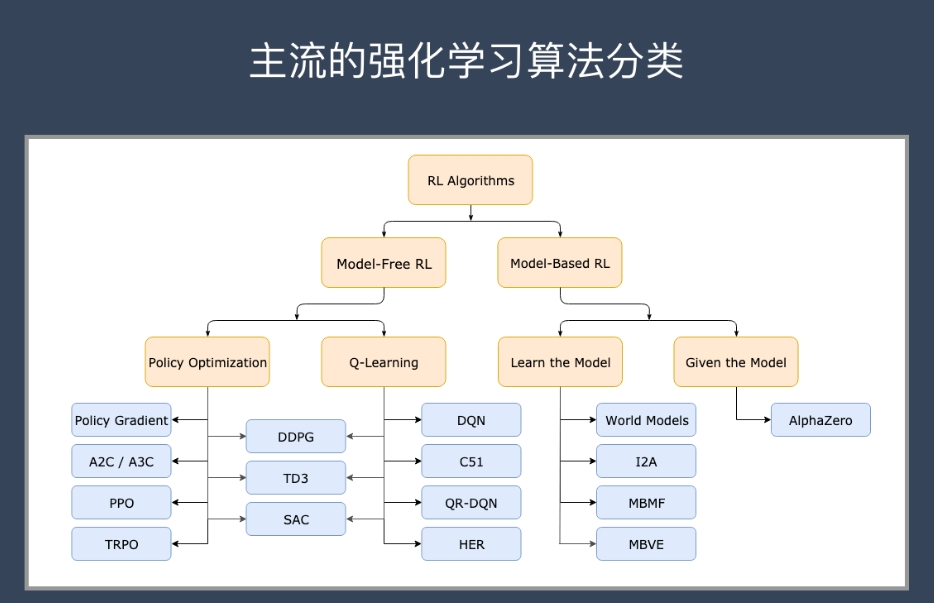
在这个领域,算法丰富多样,从最早的价值迭代到当下深度强化学习,各有适合的应用场景和技术特点。了解这些算法,能帮你更好地掌握强化学习的本质和实践方向。
✅ 强化学习主要算法详解
🔹 经典值函数方法
这些算法核心是学习状态-动作值函数(Q函数),通过评估动作的价值指导策略改进。
-
动态规划(Dynamic Programming)
基于环境模型,使用贝尔曼方程递归求解最优值函数,适合小规模、已知环境。 -
蒙特卡洛方法(Monte Carlo)
不依赖环境模型,通过多次采样整条轨迹的奖励估计状态值,适合无模型情况。 -
时序差分学习(Temporal Difference, TD)
结合动态规划和蒙特卡洛优点,在线更新值函数,代表算法有SARSA和Q-learning。-
SARSA:基于当前策略学习,策略评估和改进同时进行,属于On-policy算法。
-
Q-learning:学习最优策略的值函数,属于Off-policy,对探索策略更灵活。
-
免费分享一套人工智能+大模型入门学习资料给大家,如果想自学,这套资料很全面!
关注公众号【AI技术星球】发暗号【321C】即可获取!
【人工智能自学路线图(图内推荐资源可点击内附链接直达学习)】
【AI入门必读书籍-花书、西瓜书、动手学深度学习等等...】
【机器学习经典算法视频教程+课件源码、机器学习实战项目】
【深度学习与神经网络入门教程】
【计算机视觉+NLP入门教程及经典项目实战源码】
【大模型入门自学资料包】
【学术论文写作攻略工具】
🔹 策略梯度方法
直接优化策略参数,避免值函数逼近带来的复杂性,适合连续动作空间。
-
基本策略梯度(REINFORCE)
利用采样计算梯度,更新策略参数,优点是算法简单,缺点是方差较大,收敛慢。 -
Actor-Critic方法
结合值函数估计(Critic)和策略更新(Actor),降低策略梯度的方差,提高稳定性和效率。
🔹 先进强化学习算法(深度强化学习)
深度学习结合强化学习,突破传统算法在高维状态空间的局限。
-
DQN(Deep Q-Network)
结合卷积神经网络逼近Q值函数,实现端到端学习。著名应用是DeepMind的Atari游戏AI。 -
Double DQN
解决DQN的过估计问题,通过两个网络分开选择动作和计算价值。 -
Dueling DQN
将Q值拆分成状态价值和优势函数,提升学习效率。 -
Policy Gradient改进版本
-
PPO(Proximal Policy Optimization):利用剪切目标函数限制策略更新幅度,平衡探索和稳定性。
-
TRPO(Trust Region Policy Optimization):确保策略更新在可信区域内,提升学习稳定性。
-
-
深度确定性策略梯度(DDPG)
适合连续动作空间,结合Actor-Critic框架,实现确定性策略学习。 -
SAC(Soft Actor-Critic)
引入最大熵原则,提升探索能力和策略鲁棒性。
🔹 多智能体强化学习(Multi-Agent RL)
涉及多个智能体协同或竞争,算法复杂度更高。
-
**集中训练,分散执行(CTDE)**策略
在训练阶段集中信息,执行阶段独立行动。 -
代表算法如MADDPG(多智能体DDPG),用于机器人团队协作、游戏对抗等。
🧠 总结与应用指引
| 算法类别 | 代表算法 | 主要特点 | 适用场景 |
|---|---|---|---|
| 经典值函数方法 | Q-learning、SARSA | 学习值函数,简单有效,适合离散动作空间 | 游戏、离散控制任务 |
| 策略梯度方法 | REINFORCE、Actor-Critic | 直接优化策略,适合连续动作,样本效率较低 | 连续动作控制、机器人 |
| 深度强化学习 | DQN、PPO、DDPG、SAC | 结合深度学习处理高维状态,稳定高效 | 视频游戏、自动驾驶、复杂机器人控制 |
| 多智能体强化学习 | MADDPG、QMIX | 处理多智能体协作竞争,复杂环境 | 多机器人系统、复杂仿真环境 |
🚀 学习建议
-
基础打牢:先理解马尔可夫决策过程(MDP)、值函数和策略的基本概念。
-
掌握经典算法:从Q-learning、SARSA入手,理解探索与利用的平衡。
-
学习策略梯度:深入Actor-Critic框架和梯度优化。
-
结合深度学习:实战DQN和PPO,尝试使用OpenAI Gym环境练习。
-
探索前沿:关注多智能体算法和最大熵强化学习的最新进展。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









