




Transformer 是一种深度学习模型结构,由 Vaswani 等人在 2017 年提出,主要用于自然语言处理(NLP)任务。Transformer 模型的核心思想是 “注意力机制”(Attention Mechanism),尤其是 自注意力机制(Self-Attention),它可以有效建模序列中各个位置之间的依赖关系,而不依赖于传统的循环(RNN)或卷积(CNN)结构。
一、核心特点:
-
完全基于注意力机制:
-
与 RNN 不同,Transformer 没有循环结构。
-
每个位置的输出都可以直接关注输入序列中的任意位置。
-
-
并行计算能力强:
-
因为没有循环依赖,Transformer 可以一次性处理整个序列,更适合使用 GPU 并行加速。
-
-
良好的扩展性:
-
模型可以堆叠多个编码器/解码器层,提高表达能力。
-
免费分享一套人工智能入门学习资料给大家,如果你想自学,这套资料非常全面!
关注公众号【AI技术星球】发暗号【321C】即可获取!
【人工智能自学路线图(图内推荐资源可点击内附链接直达学习)】
【AI入门必读书籍-花书、西瓜书、动手学深度学习等等...】
【机器学习经典算法视频教程+课件源码、机器学习实战项目】
【深度学习与神经网络入门教程】
【计算机视觉+NLP经典项目实战源码】
【大模型入门自学资料包】
【学术论文写作攻略工具】
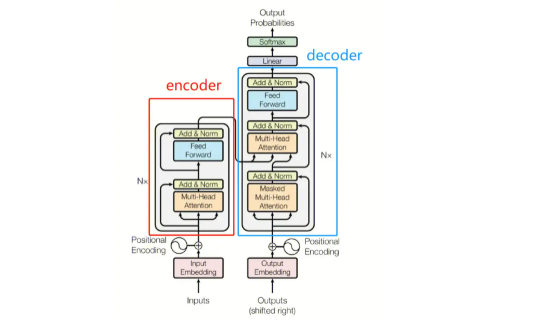
二、Transformer 的结构:
Transformer 分为两个主要部分:
1. Encoder(编码器)
-
由多个相同的子层堆叠而成(通常为 6 层)
-
每个子层包括:
-
多头自注意力机制(Multi-Head Self-Attention)
-
前馈神经网络(Feed-Forward Network)
-
残差连接和 LayerNorm
-
2. Decoder(解码器)
-
结构与 Encoder 类似,但多了一个跨注意力机制,用来关注编码器的输出。
-
每个子层包括:
-
Masked Multi-Head Attention(防止看到未来信息)
-
Encoder-Decoder Attention
-
前馈网络
-
三、关键组件详解:
✅ 自注意力机制(Self-Attention)
它计算序列中每个词与其他词的相关性,主要步骤:
-
将输入转化为 Query、Key、Value 三个向量。
-
用 Query 与 Key 计算注意力分数(相似度)。
-
将这些分数用于加权 Value 向量,得到输出。
✅ 多头注意力(Multi-Head Attention)
并行使用多个不同的注意力头,每个头学习不同的关注方式,最后拼接结果。
✅ 位置编码(Positional Encoding)
因为没有递归结构,Transformer 需要显式地添加位置信息(用正弦余弦函数编码)来理解词语的顺序。
四、应用领域:
Transformer 在多个任务中取得了突破性进展,例如:
-
机器翻译(如:Google Translate)
-
文本生成(如:ChatGPT、GPT 系列)
-
语音识别、图像处理、代码生成等
五、代表性模型:
-
BERT(双向编码器)
-
GPT(基于 Transformer Decoder)
-
T5、XLNet、RoBERTa、Vision Transformer(ViT) 等
Transformers是一种强大的深度学习架构,并成为主流的大模型基础架构并彻底改变了自然语言处理(NLP)领域。它们已被用于实现各种任务的最先进结果,包括语言翻译、文本分类和文本生成。Transformers的关键优势之一是它们的灵活性,因为通过改变其架构,它们可以适应广泛的任务和问题。然而,并非每个Transformer模型都是相同的;存在各种不同的架构,选择正确的模型对于获得最佳结果至关重要。

















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









