



当大部分多模态模型还在“看图说话”或“文生图”的单任务中打转,一个能够预测世界“下一帧”会如何演变的模型,已经悄然到来。
北京智源人工智能研究院重磅发布新一代多模态基础模型——“悟界·Emu3.5”。这不仅仅是一个更强的图像生成器,更是一个被定义为 “多模态世界大模型” 的存在。
它的革命性在于:通过在海量视频数据上端到端学习“下一状态预测”,Emu3.5首次让AI获得了对物理世界动态规律的原生理解。这意味着,它不仅能生成图片,更能创作图文交织的连贯故事、提供带视觉演示的教程,甚至模拟虚拟环境,为具身智能打开一扇新的大门。
而更令人振奋的是,它一举攻克了自回归模型生成速度慢的业界难题,通过创新的DiDA技术,将图像推理速度提升了约20倍,在速度与质量上实现了对顶级模型的赶超。
这意味着,通往更通用人工智能的道路上,一个全新的“世界模型”范式,已经显现。
核心亮点
1.原生多模态与“下一状态预测”的统一架构
Emu3.5摒弃了当前主流“大语言模型(LLM)+多模态适配器”的拼凑模式,坚持了其前代模型的原生多模态(Native Multimodality) 路线。
模型基于一个参数量为340亿的稠密Transformer,将文本、图像、视频等所有模态的数据统一表征为离散的Token。其唯一训练目标,就是预测下一个Token,无论这个Token是代表文字还是图像。
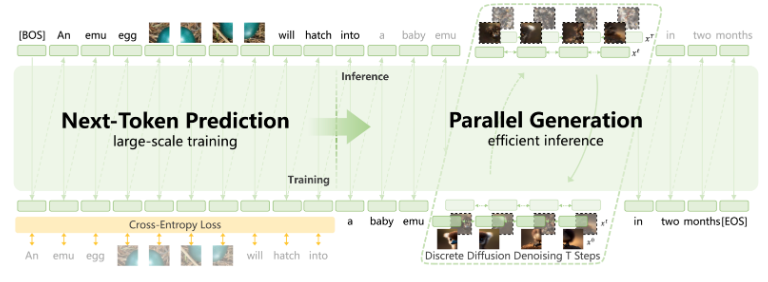
下一状态预测(Next-State Prediction): 这是Emu3.5与普通生成模型的本质区别。它不仅仅是预测“下一个词”或“下一张图”,而是在更抽象的层面上预测序列的“下一状态”。这种从“下一个Token预测”到“下一状态预测”的升华,使得模型能够自然地学习到现实世界中的动态、因果和时序规律,为其“世界模型”的能力奠定基础。
带来的能力跃迁: 正是这种原生统一的架构,让Emu3.5能够生成交错的多模态序列(如文字-图片-文字-图片……),从而原生支持“视觉叙事”、“视觉指导”等需要长程连贯性的复杂任务。
2.基于10万亿Token视频数据的“世界知识”内化
数据规模与质量:
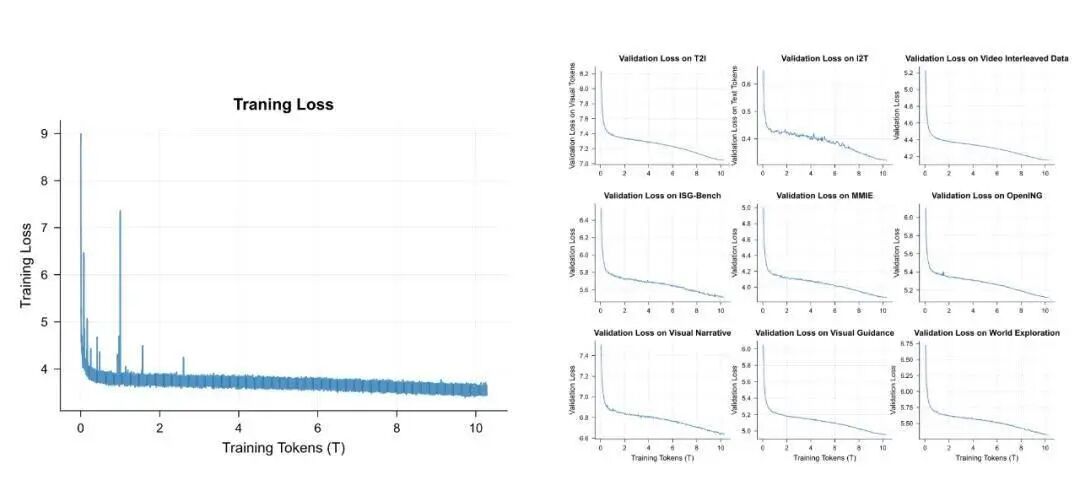
模型在总量超过10万亿个多模态Token(主要来自互联网视频,总时长约790年)的数据集上进行端到端预训练。这些视频数据包含了连续的视觉帧和同步的语音文本,提供了关于世界动态变化的天然教材。
两阶段预训练:
大规模基础学习: 在10万亿Token的广阔数据上学习通用模式和规律。
高质量能力增强: 进一步在3万亿更高质、高分辨率、强标注的数据上进行训练,激发模型更精细的能力。
带来的能力跃迁: 从静态的图文对中,模型只能学到“是什么”;而从海量视频序列中,Emu3.5内化了“如何变化”的知识,从而涌现出对物理规律、时空一致性和简单因果的理解,使其在“世界探索”和“具身操作”任务中表现出色。
3.DiDA——颠覆自回归模型的推理加速技术
自回归模型逐Token生成的特性导致其图像生成速度缓慢,这是其长期以来被诟病的主要缺点。Emu3.5通过创新的离散扩散自适应(Discrete Diffusion Adaptation, DiDA) 技术,彻底改变了这一局面。
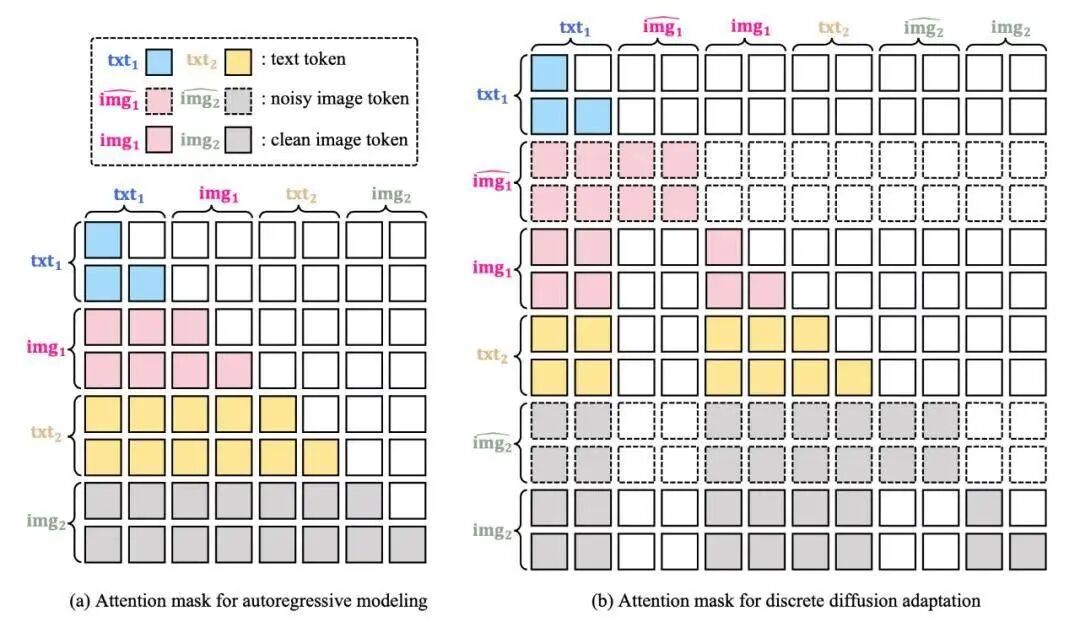
核心思想:
DiDA巧妙地将扩散模型的并行去噪思想引入到离散Token空间。它将生成过程从单向顺序预测,转变为双向并行预测。
巨大优势: 这项技术在不牺牲生成质量的前提下,将单张图像的推理速度提升了约20倍。这使得Emu3.5在生成速度上达到了与顶级扩散模型相媲美的水平,弥合了自回归模型与扩散模型之间最大的性能鸿沟。
模型评测
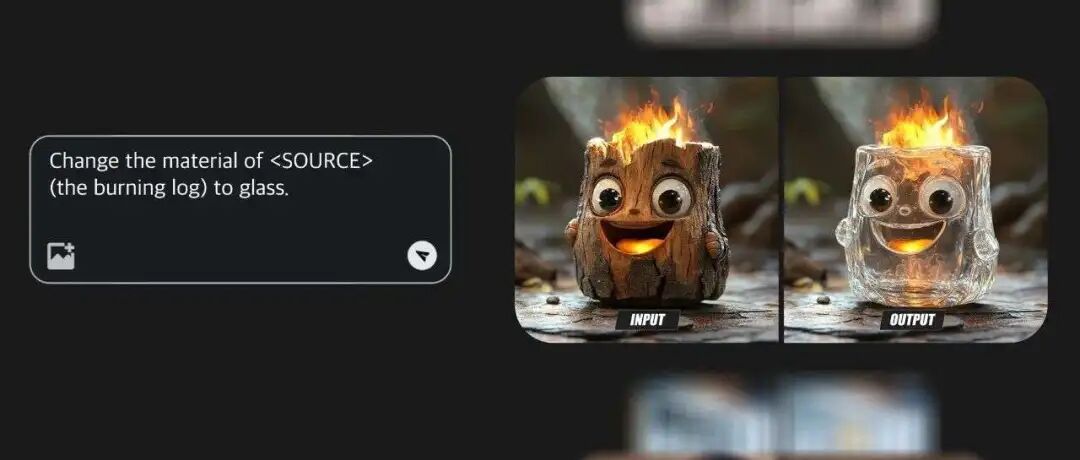
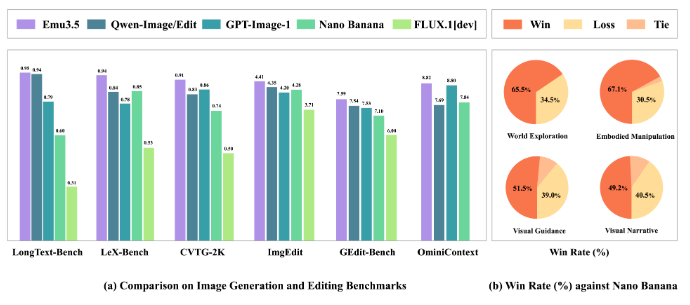
在通用图像编辑与生成任务中,Emu3-3.5展现出令人印象深刻的精确控制与多模态指令遵循能力。它不仅能够完成开放世界的创意编辑,更能实现复杂的时空一致性操作,体现出其对视觉内容深层逻辑的理解。


尤其值得一提的是其在文字渲染方面的表现——生成的图像中文字准确清晰、自然融入画面,在多项测试中,其效果甚至超越了谷歌Gemini-2.5-Flash-Image(Nano Banana)等国际领先模型,显示出强大的技术竞争力。
社区地址
OpenCSG社区:https://opencsg.com/models/BAAI/Emu3.5
hf社区:https://huggingface.co/BAAI/Emu3.5
关于 OpenCSG
OpenCSG 是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论,由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。


















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









