



以高质量数据为基石:OpenCSG 助力 MiniCPM4 实现端侧大模型的性能与效率双突破

顶尖的开源AI研究团队 OpenBMB 在其最新的技术报告中发布了备受瞩目的端侧大模型 MiniCPM4。该模型旨在以极高的计算效率在手机、个人电脑等终端设备上运行。为了在仅使用业界主流模型约22%训练数据量的情况下达到甚至超越其性能,这其中最大的瓶颈在于高质量、大规模、多样化的开源中文训练数据的极度稀缺。MiniCPM 团队实施了一套名为 UltraClean 的高效数据过滤与生成策略。
在此过程中,OpenCSG 提供的中文语料库成为了构建其高质量中文训练数据集(UltraFineWeb-zh)的关键组成部分,该语料库包含 Fineweb-edu-chinese、Cosmopedia-chinese 和 Smoltalk-chinese 等一系列高质量、目标明确的数据集,为 MiniCPM4 卓越的中文能力和整体效率奠定了坚实的数据基础。
面临的挑战
大语言模型正从追求“更大”转向追求“更优”和“更高效”,如何构建一套从数据验证到数据精炼的闭环系统,产出能够同时赋能模型高认知能力与高推理效率的终极训练集?MiniCPM 团队的核心挑战是:
-
突破资源瓶颈:
如何在不依赖海量(如36T tokens)训练数据的情况下,训练出一个性能卓越的8B级别模型? -
提升数据密度:
互联网语料库虽浩如烟海,但充斥着大量噪音和低价值信息。团队需要一种方法,从大规模数据中高效地“淘金”,构建一个知识密度高、逻辑性强的训练集。 -
保证中文能力:
作为一款同时支持中英双语的模型,如何确保其在中文核心能力评测(如 C-Eval, CMMLU)上达到顶尖水平至关重要。
解决方案
MiniCPM 团队的破局之道,是其精心设计的 UltraClean 数据工程系统。该系统不仅是一套过滤流程,更是一套包含高效验证、分类器迭代、数据合成在内的完整方法论。面对挑战,MiniCPM 团队认识到“数据质量远比数据数量更重要”。他们创新的 UltraClean 数据管线,其成功离不开高质量的数据源。
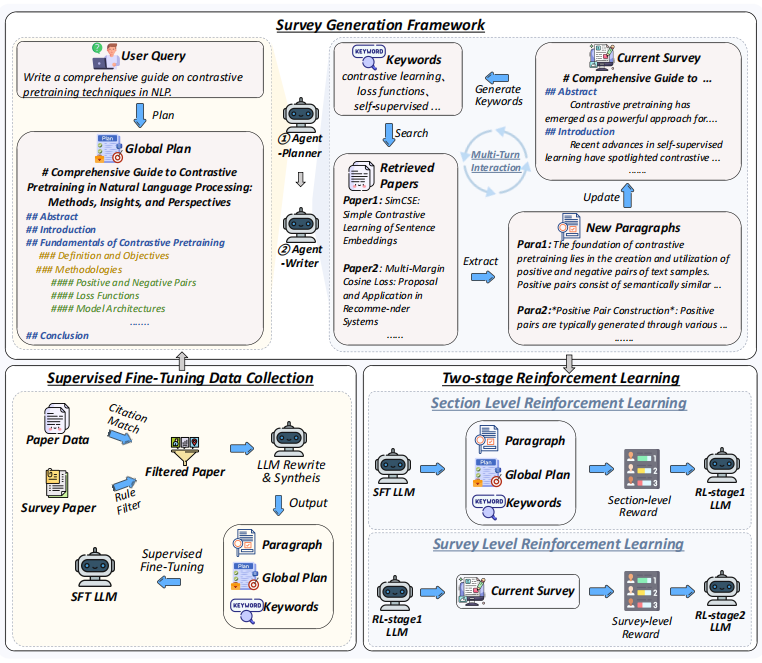
MiniCPM4-Survey 的结构框架
MiniCPM 团队的成功源于其在模型架构、训练数据、训练算法、推理系统四大维度上的系统性创新。其中,以 UltraClean 为核心的数据工程,是贯穿始终的基石。
1. 创新数据工程:UltraClean 与高效验证闭环
为了从源头上保证数据质量,MiniCPM团队没有盲目地“投喂”数据,而是构建了一套科学、高效的数据验证与筛选闭环系统。
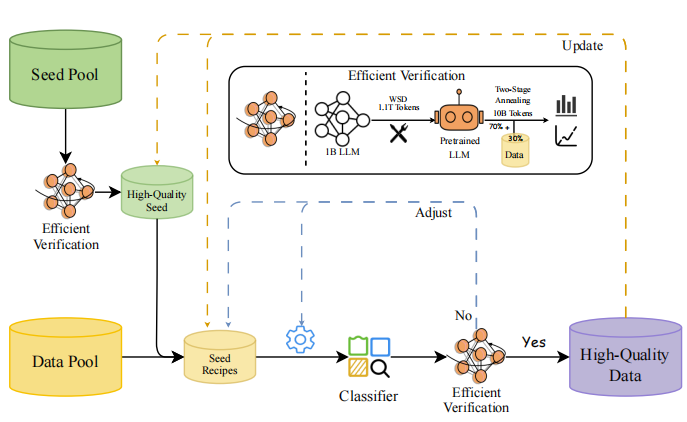
高质量数据集驱动的种子池
高效验证策略:
实现细节
团队摒弃了传统昂贵的“从零训练”验证法,创新地提出了一种**“两阶段退火微调”**策略。该策略利用一个已预训练好的1B参数基座模型,仅在训练的最后阶段(退火期)融入候选数据集进行微调。通过观察模型在 ScalingBench(一个专门设计的、与下游任务性能高度相关的评估集)上的损失变化,来快速判断数据质量。
技术优势
此方法将验证周期从1200 GPU小时缩短至110 GPU小时,效率提升超过10倍,实现了对数据质量的快速、低成本迭代验证。
OpenCSG的角色
在此环节,OpenCSG 的 Fineweb-edu-chinese 作为高质量数据源的代表,通过了这套严格的验证流程,被证实能显著提升模型性能。这不仅验证了 OpenCSG 数据的价值,也使其成为后续筛选更大规模语料的分类器的“黄金种子”。
UltraClean 数据精炼管线:
实现细节
基于验证过的高质量种子数据(包含 OpenCSG 数据),团队训练了一个轻量级的 fastText 文本质量分类器。与依赖大模型的分类器相比,fastText 能在非GPU服务器上高效处理万亿级 token。更关键的是,团队设计了迭代式训练机制:用当前分类器筛选出的正负样本,反哺下一代分类器的训练,形成自增强循环,持续提升分类器的精度和鲁棒性。
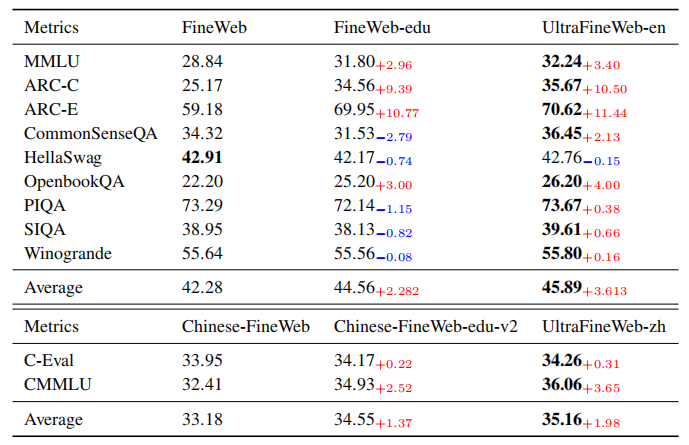
使用 UltraFineWeb(由 UltraClean 流程产出)后,模型在 MMLU、ARC 等基准上相比原始 FineWeb 的显著性能提升
Fineweb-edu-chinese:
技术细节
-
系统化的数据源聚合:
Fineweb-edu-chinese 并非单一来源,而是系统性地整合了包括 Wudao、CCI2、Skypile 等多个主流中文开放语料,确保了源数据的多样性和覆盖面。 -
基于先进模型的自动化打分:
技术核心
OpenCSG 创新性地使用了一个基于 Qwen2-7b-instruct 微调的打分模型,对每一份文本的“教育价值”(educational value)进行0-5分的量化评估。
严谨的打分标准:
其评估 Prompt 极为详尽,从内容的教育价值、连贯性、深度、结构化程度等多个维度进行考量,确保了打分体系的科学性和一致性。
结果导向的过滤:
只有得分高于3分的高价值样本才被保留。OpenCSG 的实验表明,原始语料中仅有约17.5%(16.0%+1.5%)的样本能达到此标准,这体现了其筛选的严格性。

Ranking prompt
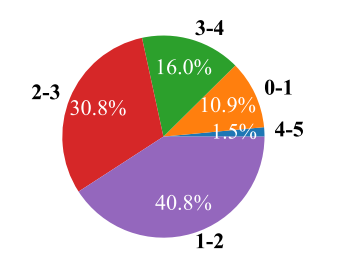
未过滤的源数据进行的评分分布
- 高效的去重技术:
采用Min-Hash算法,以0.7的重叠阈值进行去重,在保证数据多样性的同时,极大地提升了计算效率。
解决的挑战:
为 MiniCPM 的 8T token 预训练提供了干净、知识密集、大规模的基础语料。这使得模型在训练初期就能高效地吸收高质量知识,避免了在“垃圾数据”上浪费宝贵的计算资源,完美契合了 MiniCPM 对训练效率和模型能力密度的极致追求。
通过 UltraClean 流程,MiniCPM 团队最终从包括 OpenCSG 在内的源数据中,提炼出了更高质量的 UltraFineWeb-zh 中文数据集。
2. 革命性模型架构:可训练稀疏注意力 InfLLM v2
为了解决端侧设备处理长文本的性能瓶颈,MiniCPM团队研发了 InfLLM v2,一个专为高效推理设计的可训练稀疏注意力机制。
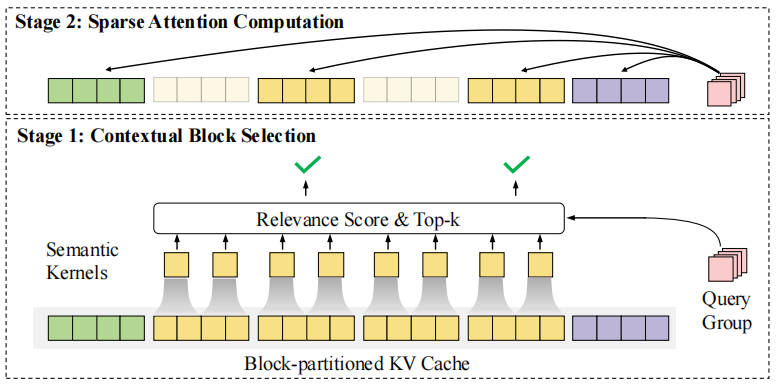
InfLLM v2 的核心架构图
实现细节:
-
动态上下文块选择:
InfLLM v2 将长文本的 Key-Value Cache 划分为多个块。对于每个新生成的 token(Query),模型不再需要与所有历史 token 进行注意力计算,而是通过一个高效的**“语义核心(Semantic Kernels)”**机制,动态地选择出最相关的几个 KV 块进行计算。 -
训练与推理协同:
与许多训练后才应用的稀疏方法不同,InfLLM v2 在预训练阶段就已引入。这意味着模型在学习语言知识的同时,也在学习如何进行“稀疏思考”。
高质量数据的赋能:
InfLLM v2 的效率依赖于模型对文本“核心语义”的精准捕捉。OpenCSG 提供的经过精炼的、结构清晰的教育和技术文本,为模型学习这种能力提供了理想的训练材料。模型在阅读了大量逻辑连贯的文本后,其注意力机制能更准确地判断哪些上下文是关键信息,从而在推理时做出最优的稀疏选择。
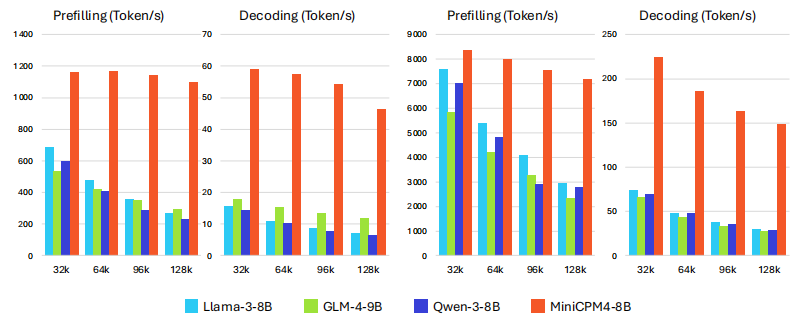
最终的性能展示(在 Jetson 和 RTX 4090 上,随着上下文长度增加,MiniCPM4 的性能优势愈发明显)
3. 推理系统级优化:CPM.cu与FR-Spec
软件和硬件的协同优化是释放模型潜力的最后一公里。MiniCPM团队为此构建了定制化的推理引擎。
实现细节:
-
CPM.cu:
一个轻量级的 CUDA 推理框架,集成了静态内存管理、核函数融合等技术。 -
FR-Spec (Frequency-Ranked Speculative Sampling):
针对推测解码中草稿模型(draft model)的词表计算瓶颈,团队创新地提出 FR-Spec。该方法通过统计发现,语言中大部分 token 由一小部分高频词构成。因此,草稿模型在生成时仅需在一个大幅缩减的高频词表上进行计算,而验证模型(target model)仍保留全词表,从而在不损失精度的前提下,将草稿生成速度提升高达4倍。
数据驱动的优化:
FR-Spec 的有效性,依赖于对训练语料的精确词频统计。OpenCSG 提供的庞大且经过清洗的中文语料库,为构建这个精准的高频词表提供了坚实的数据基础,确保了 FR-Spec 在真实中文场景下的高效运作。
成果与影响力
-
中文性能显著提升:
使用包含 OpenCSG 数据提炼而成的 UltraFineWeb-zh 数据集训练的模型,在中文权威评测 C-Eval 和 CMMLU 上的表现,均优于仅使用其他中文网络数据集训练的模型。平均分提升了 1.98 个百分点,这在竞争激烈的模型评测中是巨大的优势。 -
实现极致的训练效率:
正是基于 UltraFineWeb 这样的高质量数据集,MiniCPM4-8B 最终仅用 8T tokens 的训练量,就达到了与使用 36T tokens 训练的 Qwen3-8B 相当的性能。这充分证明,高质量的数据源(如 OpenCSG)是实现“降本增效”训练策略的核心。 -
卓越的基准测试表现:
OpenCSG 在其研究的实验中,通过在一个2B模型上使用 Fineweb-edu-chinese 进行训练,在 C-Eval 和 CMMLU 等权威中文评测上,相较于使用原始混合数据训练的基线模型,实现了显著的性能提升(如下图所示,准确率在训练后期出现跃升并大幅超越基线)。这一实验结果直接预示并验证了 MiniCPM 在使用该数据后能够取得的成功。
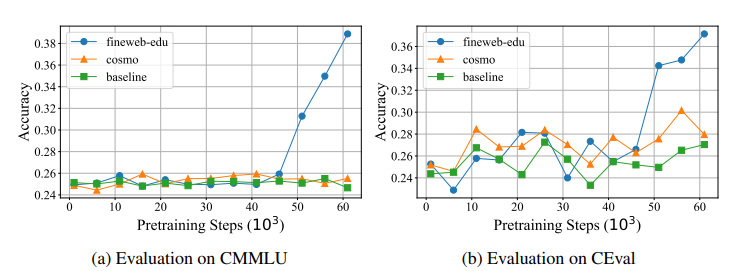
Fineweb-edu 训练的模型在 CMMLU 和 C-Eval 上后期超越 baseline 的曲线
- 强大的综合能力:
MiniCPM4 不仅在知识问答上表现出色,其在数学、代码等推理密集型任务上的强大能力,也离不开 Cosmopedia-chinese 和 Smoltalk-chinese 提供的深度知识和复杂指令数据。同时,由 Smoltalk-chinese 微调后,模型在 Alignbench 这类多维度对齐评测中表现优异。
MiniCPM 与 OpenCSG 的成功合作为中文 AI 开源社区树立了典范。随着 OpenCSG 语料库的不断迭代,以及 MiniCPM 系列模型的持续演进,双方将形成一个良性循环:更高质量的数据将催生更强大的模型,而更强大模型的成功应用,又将验证并推动数据构建方法的进步。这种开放、协作的模式,将持续降低 AI 技术门槛,催生更多像 MiniCPM 一样高效、创新的 AI 应用。
从社区到产业:OpenCSG 打造 AI 模型新基础设施
在这场以稀疏架构与高效数据为核心的技术革命背后,国产开源生态的力量不容忽视。以OpenCSG 社区为代表的开源力量,正在成为国产大模型时代的关键基础设施提供者与技术创新策源地。
OpenCSG(https://opencsg.com)是全球领先的开源大模型社区,致力于打造开放、协同、可持续的 AI 开发者生态。其核心平台 CSGHub 提供模型、数据集、代码与 AI 应用的一站式托管、协作与共享服务,具备强大的模型资产管理能力。
- 已汇聚 10 万+ 高质量 AI 模型,覆盖 NLP、CV、语音、多模态等多个核心方向;
- 服务科研机构、企业用户与开发者,提供算力支持与数据基础设施;
- 在本次 MiniCPM 训练中,OpenCSG 提供的高质量 Chinese FineWeb Edu 系列数据集 加速完成预训练阶段;
- 展示了国产开源平台在 AI 训练范式中的关键地位。
OpenCSG 作为全球第二大开源社区平台,正在以“开源生态 + 企业级落地”的双轮驱动,重新定义 AI 社区的价值。
OpenCSG 正在推动构建具有中国特色的开源大模型生态闭环。这种开放协作的模式,不仅赋能科研与产业创新,也让中国 AI 开发者在全球模型生态中拥有更多自主权与话语权。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









