



OpenAI放大招:GPT-oss开源,200万小时训练,120B/20B双版本免费商用
今天凌晨,AI行业迎来历史性时刻!
OpenAI突然宣布开源其最新大模型 GPT-oss ,包含1200亿(120B)和200亿(20B)参数两个版本,并采用 Apache 2.0开源协议,允许企业自由商用!
这一发布堪称“AI界的Linux时刻”——它不仅性能媲美GPT-4级别的闭源模型(如o4-mini),更针对AI Agent(智能体)进行了专项优化,支持函数调用、网络搜索、Python代码执行等高级功能,开发者可以轻松构建功能强大的自主Agent。
更令人惊喜的是,GPT-oss-20B仅需16GB显存即可运行,甚至能在高端手机上部署;而旗舰级GPT-oss-120B虽然需要80GB显存,但推理能力直接对标顶级商业模型!OpenAI透露,该模型在H100显卡上训练超200万小时,堪称目前开源界计算成本最高的模型之一。
Sam Altman亲自发文强调:“我们相信,人工智能的控制权应该交给用户。”这一开源举动或将彻底改变AI技术栈的竞争格局,让全球开发者都能基于最先进的开放模型,打造属于自己的AI未来。
架构解析
OpenAI此次开源的GPT-oss系列采用混合专家(MoE)架构,通过动态计算资源分配实现了性能与效率的完美平衡。两大版本模型在结构设计上各具特色:
1. 参数架构:智能计算分配系统
- GPT-oss-120b(1168亿参数)采用36层MoE结构,每token仅激活51亿参数(约4.4%总参数量)
- GPT-oss-20b(209亿参数)配置24层MoE,每token激活36亿参数(17.2%利用率)
这种动态稀疏激活机制使模型能根据任务复杂度自动调节计算强度,在保持顶级性能的同时大幅降低推理成本。
2. 专家系统:模块化智能处理单元
- 120b版本每个MoE模块集成128个专业子网络,20b版本配置32专家系统
- 创新采用线性路由选择器,通过残差激活映射实现专家智能调度
- 每token仅调用Top4专家组合,并采用softmax加权输出,形成自适应计算管道
3. 注意力机制升级:长文本处理新标杆
- 交替使用带状窗口(128token)与全密集模式,兼顾效率与全局理解
- 64个查询头(维度64)配合8组键值头,采用分组查询注意力技术
- 通过YaRN增强的RoPE位置编码,将上下文窗口扩展至131k token,支持超长文本分析
4. 核心组件优化:稳定训练的秘诀
- RMSNorm预归一化:在每个注意力和MoE模块前实施,确保数据分布一致性
- 门控SwiGLU激活函数:增强非线性表达能力,提升复杂特征提取效果
这种架构设计使得GPT-oss系列在保持顶尖性能(接近GPT-4级别)的同时,大幅降低了实际推理时的计算开销。特别是20b版本,通过少量的参数激活率就实现了几倍于参数量的实际效能,为边缘计算设备部署大模型提供了全新可能。
根据GPT-oss的测试数据显示,其推理、工具调用能力非常出色,可媲美OpenAI的前沿模型o4-mini。
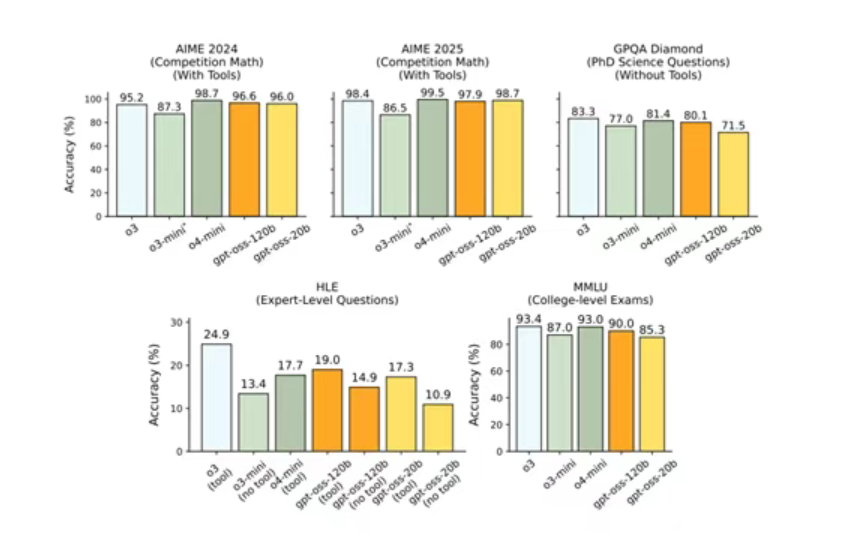
在多项专业基准测试中,GPT-oss-120b展现出接近商业顶级模型的卓越性能:其在美国数学邀请赛(AIME)中取得96.6%的准确率,与o4-mini的98.7%仅相差2.1个百分点;在Codeforces编程竞赛中获得2622的Elo评分,逼近o4-mini的2719分表现;同时在多语言任务中,法语(84.6%)、德语(83.0%)和西班牙语(85.9%)的高准确率更印证了其强大的跨语言适应能力。
模型本地部署
- 您可以通过Transformers库使用gpt-oss-120b和gpt-oss-20b模型。在使用前,需要先安装必须的python环境
pip install -U transformers kernels torch
- 完成环境配置后,您可以通过运行以下代码片段来启动模型:
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-20b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "Explain quantum mechanics clearly and concisely."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
- 或者,您也可以通过Transformers Serve启动一个兼容OpenAI接口的Web服务来运行模型:
transformers serve
transformers chat localhost:8000 --model-name-or-path openai/gpt-oss-20b
社区地址
OpenCSG社区:
https://opencsg.com/models/openai/gpt-oss-20b
hf社区:
https://huggingface.co/openai/gpt-oss-20b
关于 OpenCSG
OpenCSG 是全球领先的 开源大模型社区平台,致力于打造开放、协同、可持续的 AI 开发者生态。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的 模型资产管理能力,支持多角色协同和高效复用。
平台已汇聚 10 万+ 高质量 AI 模型,覆盖自然语言处理(NLP)、计算机视觉(CV)、语音识别与合成、多模态等核心方向,广泛服务于科研机构、企业与开发者群体,配套提供 算力支持与数据基础设施。
作为全球第二大开源 AI 社区,OpenCSG 正在以“开源生态 + 企业级落地”为双轮驱动,重新定义 AI 模型社区的价值体系。我们正积极推动构建 具有中国特色的开源大模型生态闭环,通过开放协作机制,持续赋能科研创新与产业应用,加速中国 AI 在全球生态中的 技术自主与话语权提升。
CSGHub(解决方案、产品)
关于 CSGHub
CSGHub 是由OpenCSG推出的企业级模型与数据资产管理平台,旨在为组织提供 Hugging Face 式的高效协作体验,同时满足本地化部署、数据安全与法规合规。
平台支持与 Hugging Face 工作流无缝兼容,并提供多源同步、私有镜像、全离线运行等特性,帮助企业在安全可控的环境中实现 AI 研发与部署的全生命周期管理。
官网链接: https://opencsg.com/csghub
开源项目地址: https://github.com/OpenCSGs/CSGHub


















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









