




字节跳动最新开源的UNO模型,代表了AI图像生成领域的一项重大突破。UNO不仅继承了FLUX模型的强大功能,还通过创新的技术架构,解决了当前定制化图像生成中的多个难题。这个全新的生成模型将图像生成与多主体合成完美融合,具备强大的个性化生成能力,适用于多种创意场景。
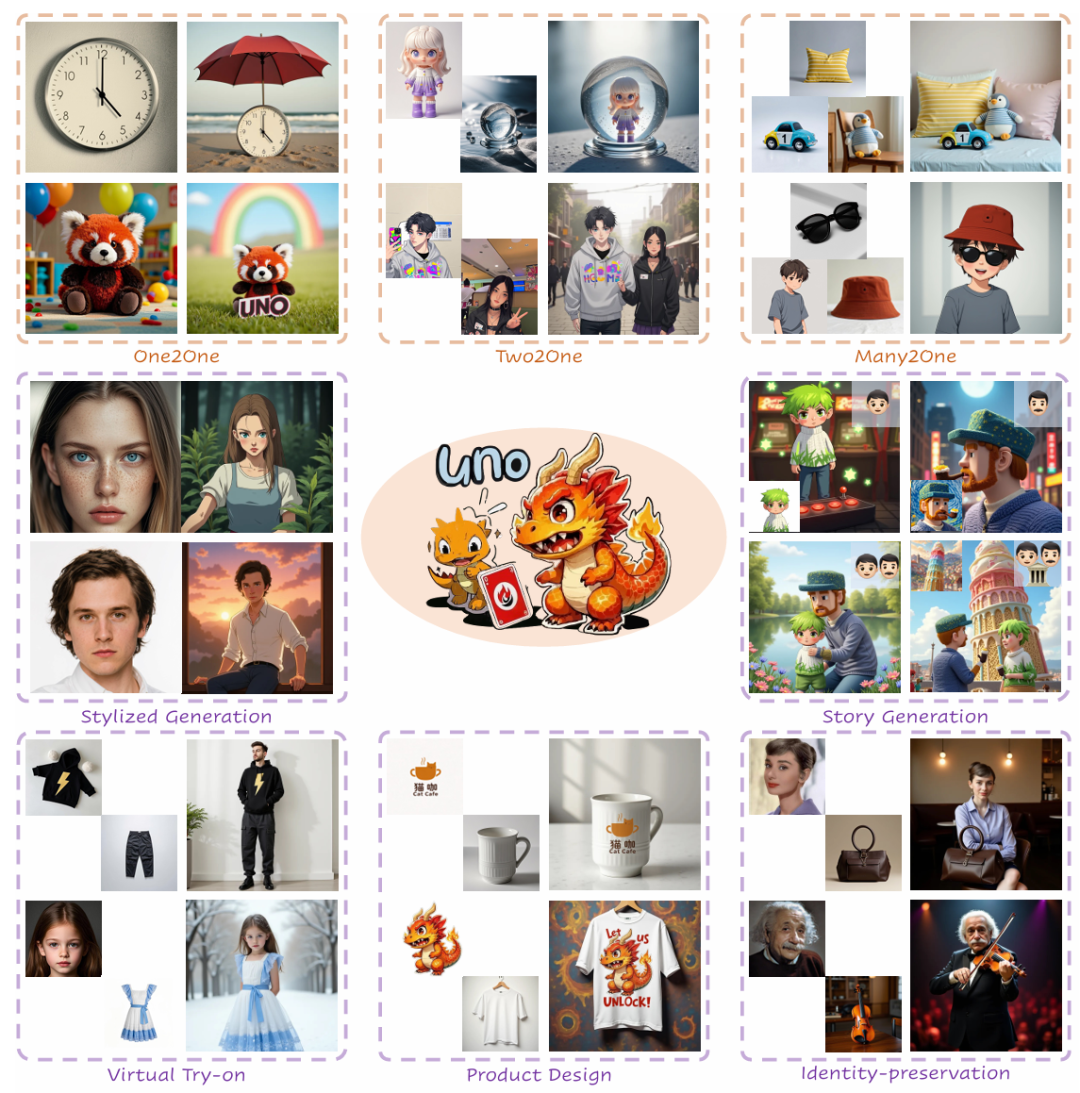
UNO模型的技术亮点
UNO模型的技术亮点可以从多个方面体现出其创新性与突破性。作为字节跳动开源的最新AI图像生成模型,UNO不仅仅在传统的图像生成任务上实现了突破,更在多主体生成、数据生成框架和模型架构的创新方面做出了重大贡献。
-
模型-数据协同进化范式UNO创新地提出了“模型-数据协同进化”的新范式。传统的AI图像生成模型通常存在数据瓶颈,尤其是在多主体生成时,很难找到高质量的多视角、主体一致性强的数据。而UNO通过设计一种系统化的合成数据框架,能够自动生成高质量、一致性的单主体和多主体配对数据。这种数据生成框架依赖于扩散变换器(Diffusion Transformers)的上下文生成能力,克服了传统方法在数据扩展上的困难。通过模型与数据的协同进化,UNO可以在不同的生成任务中不断优化数据质量,并最终提升模型生成的表现。
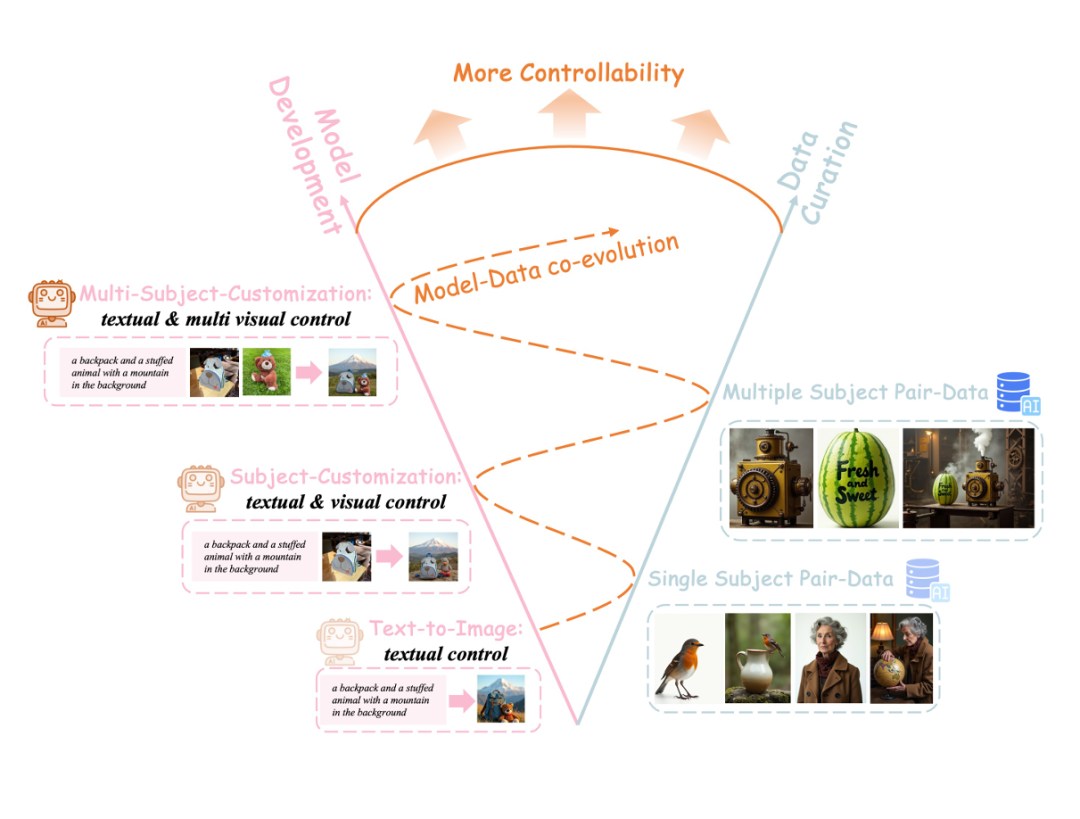
-
渐进式数据生成框架UNO采用渐进式数据生成框架,从单主体生成逐步过渡到多主体生成。这一框架有效地解决了多图像条件下生成的复杂性。对于单主体生成,UNO通过精细化的数据生成管道确保了图像的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 21
21

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









