




 文章介绍了SATRN模型,该模型利用2D自注意力机制解决大曲率、旋转文本识别问题。通过ShallowCNN、Adaptive2DPositionalEncoding和优化的FFN层,SATRN在Irregular文本数据集上取得SOTA性能。实验表明,其在旋转文本和多行文本识别中表现出色,但速度较慢,仍有优化空间。
文章介绍了SATRN模型,该模型利用2D自注意力机制解决大曲率、旋转文本识别问题。通过ShallowCNN、Adaptive2DPositionalEncoding和优化的FFN层,SATRN在Irregular文本数据集上取得SOTA性能。实验表明,其在旋转文本和多行文本识别中表现出色,但速度较慢,仍有优化空间。
On Recognizing Texts of Arbitary Shapes with 2D Self-Attention(SATRN)
基本信息
- 论文链接
- 发表时间:2020
- 应用场景:自然场景场景文字识别
摘要
| 存在什么问题 | 解决了什么问题 |
|---|---|
| 1. 现有识别模型对于大曲率弯曲或者旋转文本识别效果不佳。 2. crnn - 默认文字是水平排列的。 |
1. 提出SATRN网络结构,利用self-attention机制对场景文字图片下所有字符的2d空间关系进行建模,在面对文字不同的布局方式以及字符间隔较大的情况下有天然的优势。 2. 对于大曲率弯曲、大角度旋转文本以及多行文字也具备足够的识别能力。 3. 在非规则文本(irregular text)数据集上超过先前模型5.7个点,达到SOTA。 |
模型结构
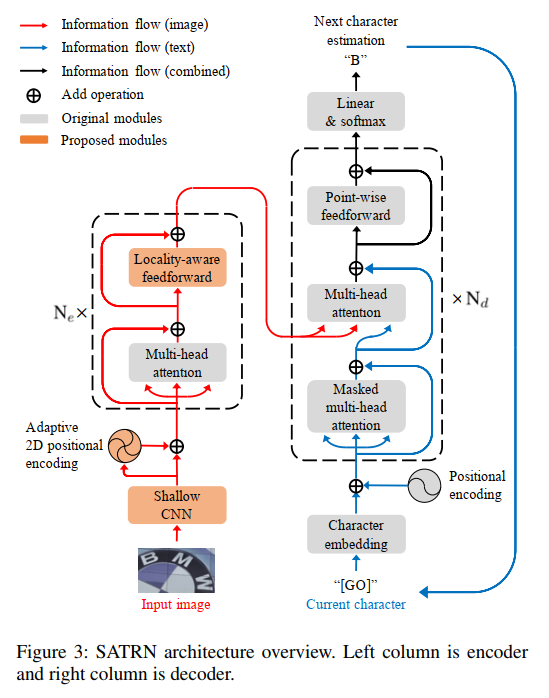
能够明显看出整体结构与标准的transformer几乎一致,整体上遵循CNN -> transformer encoder -> transformer decoder架构。
在encoder上相比于原始的transformer encoder,有已下3点优化:
-
出于计算量的考虑,先用一个CNN(文中叫Shallow CNN)处理输入图像,抽取视觉特征的同时进行降采样操作,降低feature map的大小,为后续transformer encoder建模像素间的关系减轻计算负担。Shallow CNN采用简单的两层conv->bn->relu->pool堆叠即可,实现高和宽的4倍降采样。
-
经过CNN后,就准备将feature map送入transformer encoder中了,但是此时feature map是2D的,并不是一个序列,像素间是存在空间位置关系的,因此一个优秀的position encoding模块是非常有必要的,作者这里提出了adaptive 2D positional encoding(A2DPE)模块。
对于featurep map上的每一个像素点,首先是一个x,y方向的传统正、余弦position encoding(下图只列了一个方向的公式):
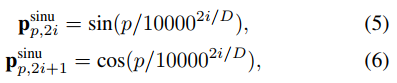
最终的position encoding是两者的加权叠加:
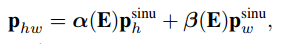
而权重 α ( E ) \alpha(E)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2294
2294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









