




 本文介绍了OneFlow中Permute算子的优化技巧,通过对比PyTorch,展示了经过优化的Permute操作在速度和带宽利用率上的显著提升,尤其是在BatchTranspose场景下,性能最高可提升6.3倍。
本文介绍了OneFlow中Permute算子的优化技巧,通过对比PyTorch,展示了经过优化的Permute操作在速度和带宽利用率上的显著提升,尤其是在BatchTranspose场景下,性能最高可提升6.3倍。

撰文 | 郑泽康、柳俊丞、姚迟、郭冉
无论是在统治NLP届的Transformer,还是最近视觉领域的新秀Vision Transformer,我们都能在模型中看到Transpose/Permute算子的身影,特别是在多头注意力机制(Multi-Head Attention)中,需要该算子来改变数据维度排布。
显然,作为一个被高频使用的算子,其CUDA实现会影响到实际网络的训练速度。本文会介绍OneFlow中优化Permute Kernel的技巧,并跟PyTorch的Permute,原生的Copy操作进行实验对比。结果表明,经过深度优化后的Permute操作在OneFlow上的速度和带宽利用率远超PyTorch,带宽利用率能够接近原生Copy操作。
1
朴素的Permute实现
Permute算子的作用是变换张量数据维度的顺序,举个例子:
x = flow.randn(2, 3)
y = x.permute(1, 0)
y.shape
(3, 2)其实现原理也可以很容易理解,即输出Tensor的第i维,对应输入Tensor的dims[i]维,上述例子中 permute 实现对应的伪代码如下:
for row in x.shape[0]:
for col in x.shape[1]:
y[row][col] = x[col][row]但是实际情况与上面的伪代码有出入,张量的Shape是数学上的概念,在物理设备上并不真实存在。
在OneFlow中,张量的数据都是保存在一块连续的内存中,下图分别从上层视角和底层视角描述了形状为(2, 3)的张量的存储方式:
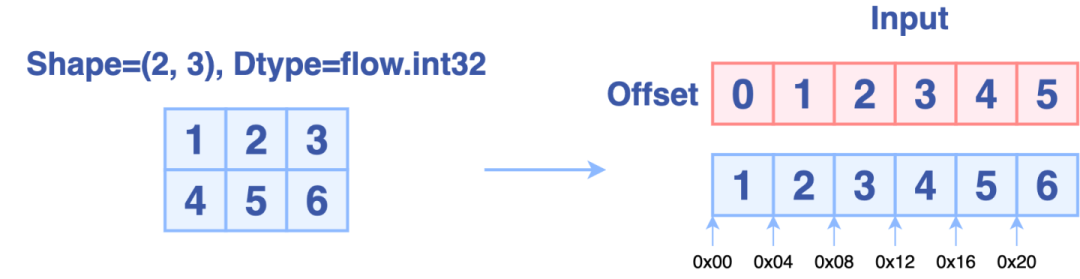
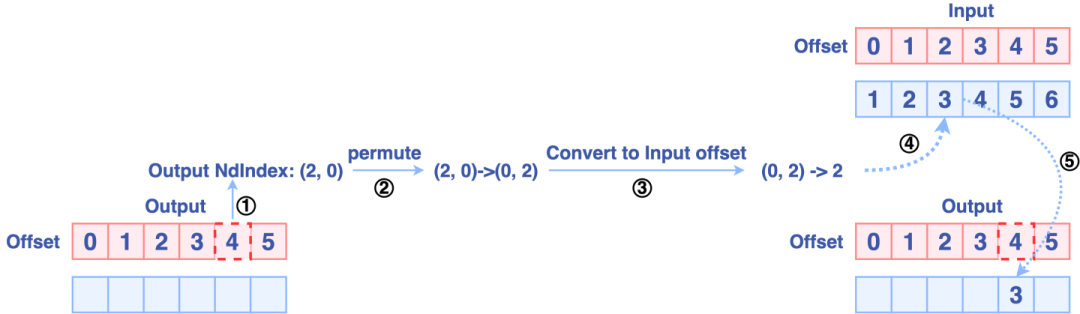
OneFlow的Permute实现原理为:
-
通过当前输出的一维偏移量(offset)计算对应的高维索引
-
然后根据参数dims重新排列输出索引,进而得到输入索引。
-
将输入索引转换成输入偏移量
-
最后进行数据移动,整个过程的示意图如下:
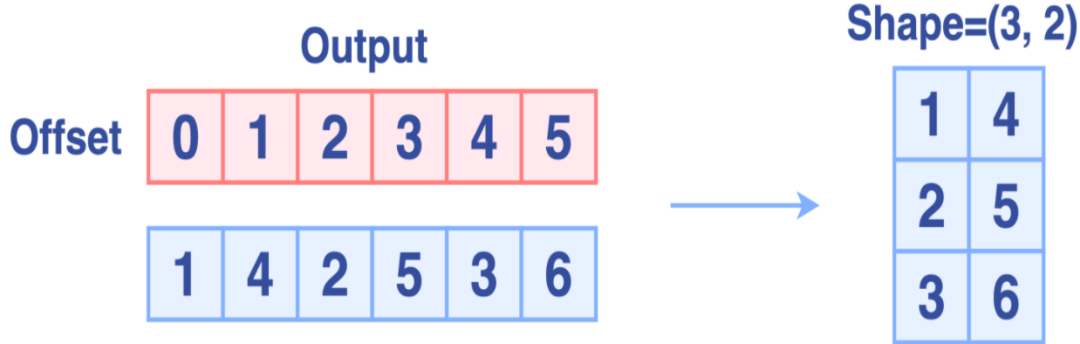
完成Permute后,输出如下图所示:
整个 permute 计算过程需要经过多次一维偏移量offset和高维索引之间的转换,为了避免一次次手工计算,OneFlow提供了一个工具类NdIndexOffsetHelper来方便做上述转换。
2
NdIndexOffsetHelper
NdIndexOffsetHelper的主体方法如下:
-
NdIndexToOffset方法把高维索引转为一维偏移量
-
OffsetToNdIndex方法把一维偏移量转为高维索引
有了这么一个工具类,那我们就可以很轻松的写出一版Naive Permute Kernel了,核函数如下:
template<size_t num_dims, size_t movement_size, typename IndexType>
__global__ void PermuteKernel(PermuteKernelParams<num_dims, IndexType> params) {
using T = typename std::aligned_storage<movement_size, movement_size>::type;
const T* src = reinterpret_cast<const T*>(params.src);
T* dst = reinterpret_cast<T*>(params.dst);
IndexType src_index[num_dims];
IndexType dst_index[num_dims];
CUDA_1D_KERNEL_LOOP_T(IndexType, i, params.count) {
params.dst_index_helper.OffsetToNdIndex(i, dst_index);
#pragma unroll
for (size_t dim = 0; dim < num_dims; ++dim) {
src_index[params.permutation[dim]] = dst_index[dim];
}
IndexType src_offset = params.src_index_helper.NdIndexToOffset(src_index);
dst[i] = src[src_offset];
}
}-
PermuteKernelParams是一个结构体,里面有初始化好的NdIndexOffsetHelper(src和dst各一个),元素总数count还有变换后的维度顺序permutation
-
首先我们取得当前处理输出元素的高维索引dst_index,然后赋给经过Permute后的输入索引src_index
-
再将输入索引转换成一维偏移量src_offset,取到输入元素并赋给对应的输出
3
常规情况的优化
这种朴素Permute Kernel的计算代价来源于坐标换算,访存开销则来源于数据移动,针对这两个角度我们引入以下优化方案。
1. IndexType静态派发
随着深度学习模型越来越大,参与运算元素的个数可能超过int32_t表示的范围。并且在坐标换算中,不同整数类型的除法运算开销不一样。因此我们给核函数增加了一个模板参数IndexType用于指定索引的数据类型,根据参与Permute的元素个数来决定IndexType是int32_t还是int64_t。
2. 合并冗余维度
在一些特殊情形下,Permute维度是可以进行合并的,其规则如下:
-
大小为1的维度可以直接去除
-
连续排列的维度可以合并成一个维度
针对第二条规则,我们考虑以下Permute情况:
# 0, 1, 2, 3) -> (2, 3, 0, 1)
x = flow.randn(3, 4, 5, 6)
y = x.permute(2, 3, 0, 1)
y.shape
(5, 6, 3, 4)显然这是一个四维的Permute情形,但这里第2,3维,第0,1维是一起Permute的,所以我们可以看成是一种二维的Permute情形:
# (0, 1, 2, 3) -> ((2, 3), (0, 1))
x = x.reshape(x.shape[0]*x.shape[1], x.shape[2]*x.shape[3])
y =& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 927
927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









