



渗透测试笔记系列文章目录
信息收集篇
漏洞扫描篇
漏洞利用篇
权限维持篇
内网渗透篇
前言
漏洞扫描可以理解为进一步的信息收集,以验证漏洞为目标的信息收集
上一步已经完成对目标的基本信息收集(比如IP、域名、开放服务等),至少要确定漏洞扫描的范围
本篇将分为以下几个部分:
防御机制绕过和隐蔽技巧
已知漏洞匹配
复杂的业务逻辑漏洞
自动漏洞扫描工具
防御机制绕过和隐蔽技巧
CDN绕过
隐藏真实服务器IP
CDN的核心功能是通过分布式节点缓存内容,用户的请求会被导向离其最近的节点,而非源站服务器。这使得通过常规手段(如nslookup、ping)获取的IP通常是CDN节点的地址,而非后端真实服务器IP。
获取真实IP可以在网络空间搜索引擎上这么操作:
title=“target site” && body!=“cdn keyword”
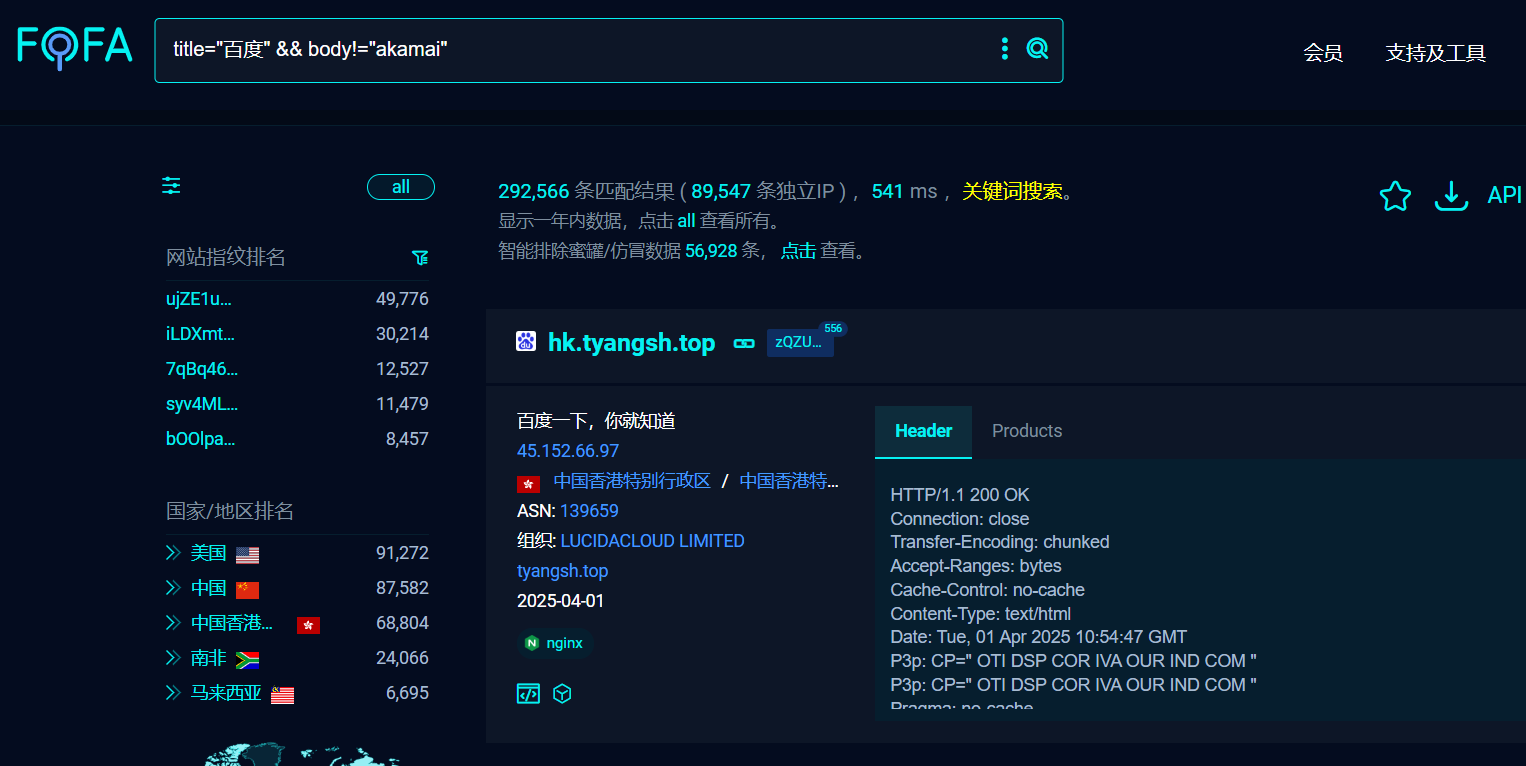
过滤CDN特征:
通过FOFA的过滤器排除常见CDN关键词(如 cloudflare, akamai),缩小结果范围。
或者绕过CDN直接探测,某些CDN节点可能允许直接访问源站。
尝试通过IP直接访问(如http://<CDN_IP>),观察是否返回源站内容。
curl http://<CDN_IP>
使用Host头伪造目标域名(如curl -H “Host: example.com” <CDN_IP>)。
curl -H "Host: example.com" http://<CDN_IP>
CDN可能修改响应内容,但原始请求可能包含线索。
分析HTTP响应头中的Server、X-Powered-By等字段。
使用中间人代理(如Burp Suite)捕获流量,寻找异常跳转或重定向。
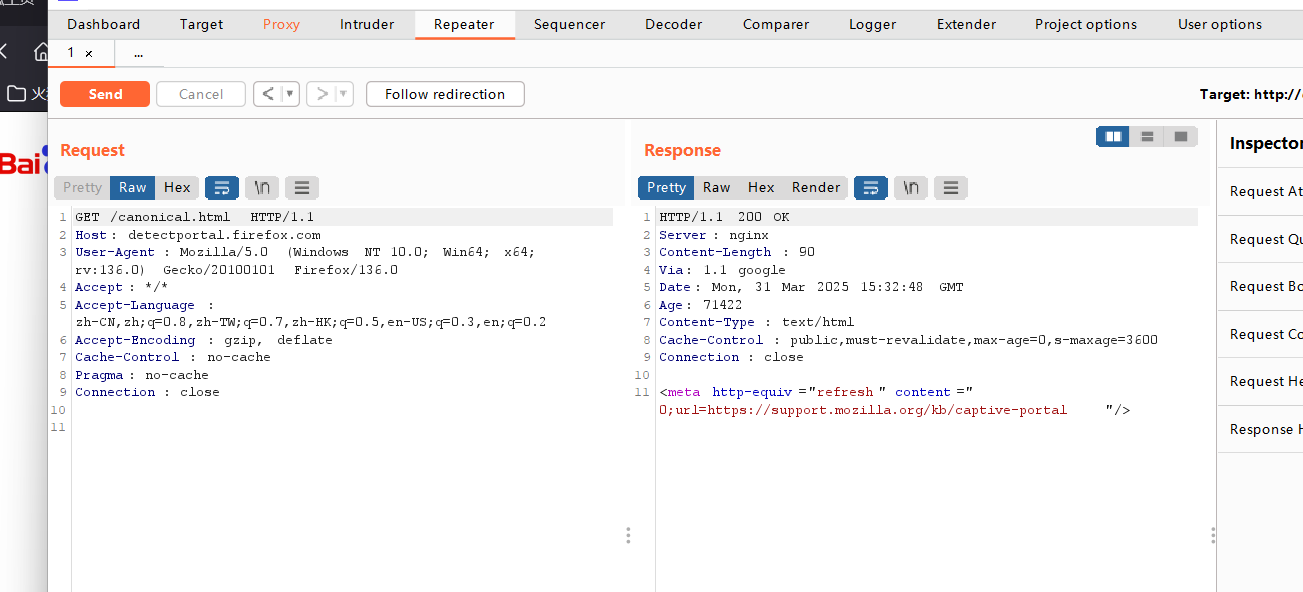
WAF绕过
WAF(web应用防火墙)WAF的一般检测机制如下
对照已知攻击特征库,检测SQL注入、XSS、目录遍历等攻击模式
请求频率异常检测(如单IP每秒发起>20次请求)
用户代理(User-Agent)与浏览器指纹不匹配
检查HTTP请求头完整性(缺失Host/Referer字段)
验证Cookie一致性(篡改Cookie触发防护)
WAF的响应如下
| 响应级别 | 技术实现 | 对扫描器的影响 |
|---|---|---|
| 日志记录 | 写入WAF日志(含时间戳/IP/请求内容) | 无直接阻断,但可能触发人工审计 |
| 访问控制 | 返回403 Forbidden或404 Not Found | 扫描结果失真(无法探测真实服务状态) |
| 速率限制 | 触发滑动窗口计数器(如1分钟内>100次请求) | 扫描速度被迫降低(需间隔>1秒/请求) |
| 挑战机制 | 返回验证码(Captcha)或JS挑战 | 自动化扫描中断,需人工介入 |
| IP封禁 | 临时/永久加入黑名单(如Cloudflare的Bot管理) | 扫描任务完全终止 |
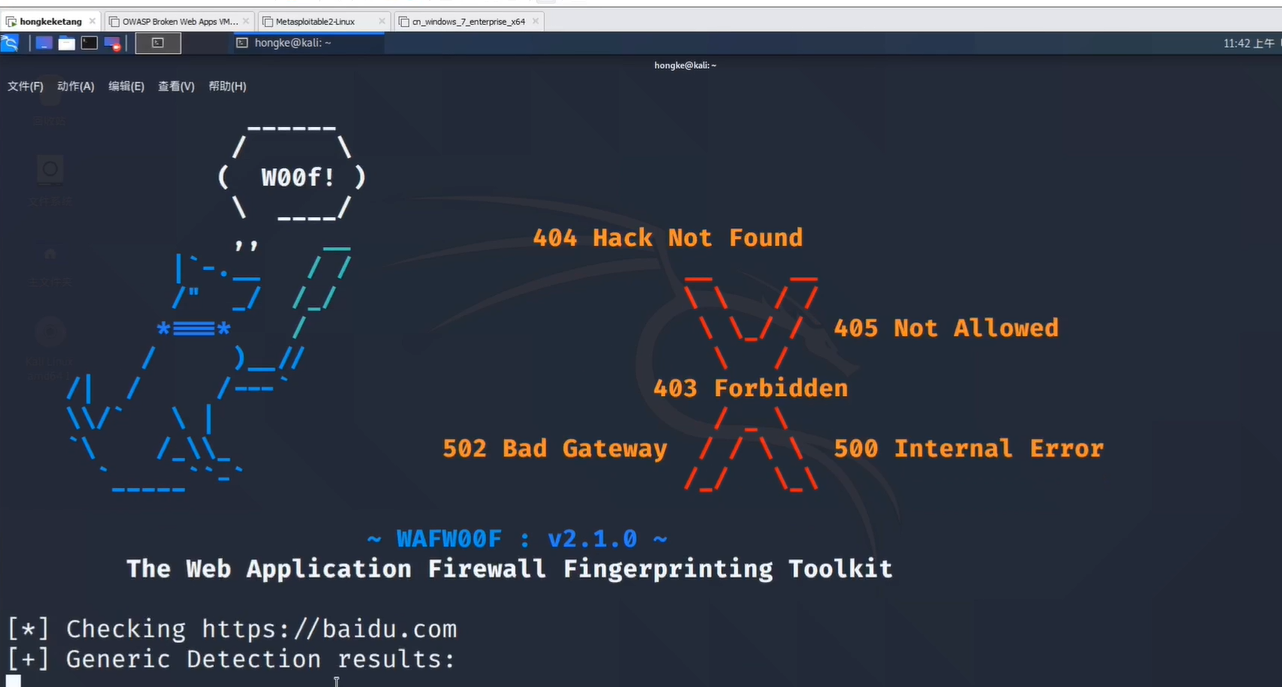
探明目标的WAF我们使用工具wafw00f:
可以识别很多版本的WAF
主流工具绕过 WAF 的关键技术:
- sqlmap
使用 --tamper 参数混淆 payload
启用 --random-agent 随机化请求头
通过 --proxy-chain 跳转多节点 - Nessus
修改扫描策略(禁用高风险指纹检测)
添加 X-Forwarded-For 头模拟合法流量 - Burp Suite
使用 Intruder 时分段发送请求
结合 Repeater 手动验证绕过效果 - Wfuzz
使用 --hc 403 过滤 403 响应
对参数值进行 Base64 编码绕过字符串匹配
代理池
代理池类似一个“中介公司”,管理一群“临时演员”(代理IP)。当需要访问目标网站时,公司随机派一个“演员”(代理)去执行任务,若被发现(IP被封),立即换下一个,确保真实身份(你的IP)始终不暴露。
分散流量,通过轮换多个IP地址发送请求,避免单一IP触发安全警报。匿名化,隐藏真实IP地址,使目标难以追踪扫描来源。绕过限制,应对IP封锁、频率限制或地理访问策略。
- 步骤1:选择或构建代理池
来源类型:
付费服务(如 BrightData、Oxylabs):提供高匿名性、稳定性的代理。
开源工具(如 Scrapy-ProxyPool、ProxyPool):自行搭建代理池。
公共代理(免费但可靠性低,慎用)。
验证代理有效性(python):
# 示例:验证代理是否存活
import requests
def check_proxy(proxy):
try:
resp = requests.get("http://httpbin.org/ip", proxies={"http": proxy, "https": proxy}, timeout=5)
return resp.status_code == 200
except:
return False
- 步骤2:集成代理池到扫描工具
主流工具配置:
Burp Suite:通过插件(如 ProxyList)加载代理列表。
Nmap:使用 --proxies 参数(需配合 proxychains)。
自定义脚本:在Python中使用 requests.Session
动态切换代理:
import random
import requests
proxy_pool = ["http://ip1:port", "http://ip2:port", ...]
proxy = {"http": random.choice(proxy_pool), "https": random.choice(proxy_pool)}
response = requests.get("http://target.com", proxies=proxy)
- 步骤3:动态IP轮换策略
随机轮询:每次请求随机选择代理。
失败重试机制:若某代理失效(如返回 403 或超时),自动切换至下一个代理。
会话保持:对需要登录的页面,优先复用同一代理以维持会话。 - 步骤4:规避流量特征
混淆请求头:
随机化 User-Agent、Accept-Language 等字段。
模拟浏览器行为(如添加 Referer 头)。
限制请求速率:
# 使用工具(如 `proxychains`)限制每秒请求数
proxychains -f proxy_list.txt -q curl -s http://target.com
已知漏洞匹配
CVE(Common Vulnerabilities and Exposures,通用漏洞披露)是一个广泛认可的公开数据库,旨在标准化网络安全漏洞的标识与信息共享。
NVD(国家漏洞库)NVD(nvd.nist.gov)是 CVE 的扩展数据库,提供更结构化的查询功能:
支持通过 CPE(Common Platform Enumeration) 搜索特定软件和版本
自动关联 CVSS 评分、受影响版本列表、修复建议等。
一般情况下用如下信息都可以去漏洞库匹配相应漏洞:
- Web服务器(如Apache、Nginx) 如何获取:
- HTTP响应头检查
使用 curl 命令:
bash
复制
curl -I http://target.com # 查看响应头中的 “Server” 字段
Apache 示例:Server: Apache/2.4.53 (Ubuntu)
Nginx 示例:Server: nginx/1.18.0 - 页面错误信息
访问一个不存在的页面(如 http://target.com/invalid),观察错误页面是否暴露版本:
Apache 错误页可能显示 Apache/2.4.53 (Debian) Server at target.com Port 80
Nginx 错误页可能显示 nginx/1.18.0 - 工具扫描
使用 nmap 脚本:
nmap -sV --script=http-server-header target.com
- 数据库(如MySQL、Oracle) 如何获取:
- MySQL
直接连接数据库:
mysql -u root -p -e “SELECT VERSION();”
通过错误信息:
访问 http://target.com/phpmyadmin 或其他管理界面,登录失败时可能显示版本。 - Oracle
使用 SQL 查询:
SELECT * FROM v$version;
通过TNS监听器:
nmap -sU -p 1521 --script=oracle-tns-version target.com
- 中间件(如Tomcat、Redis)的具体版本 如何获取:
- Tomcat
访问管理页面(如 http://target.com:8080/),页面底部可能显示版本。
通过HTTP头:
curl -I http://target.com:8080/
#查看 “Server: Apache-Coyote/1.1”
检查 /WEB-INF/web.xml 文件中的配置信息。 - Redis
连接Redis服务:
redis-cli -h target_ip -p 6379 INFO server | grep redis_version
通过错误响应:
未授权访问时,执行 INFO 命令会直接返回版本。
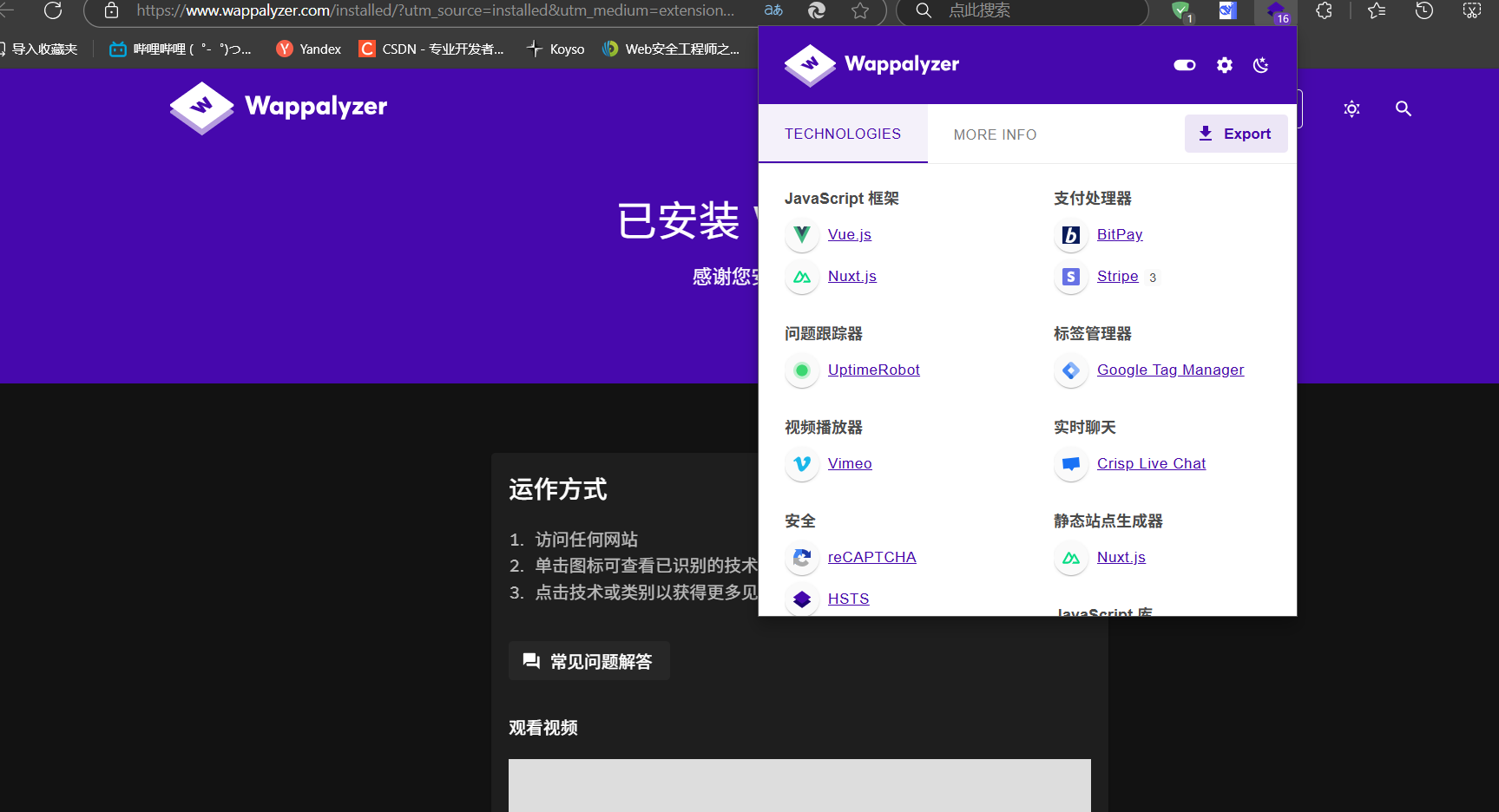
- Web应用框架:如Spring Boot、DedeCMS、WebLogic的版本 如何获取:Wappalyzer插件
浏览器插件 Wappalyzer 可自动识别目标网站的CMS、框架、库及版本。
复杂的业务逻辑漏洞
业务逻辑漏洞的挖掘依赖对业务的深刻理解和创造性思考,需结合自动化工具与人工分析。重点关注参数篡改、权限绕过、流程跳跃等场景,同时注意防御性设计(如签名校验、状态机验证)。
业务逻辑漏洞隐蔽性高,这类漏洞依赖对业务逻辑的深入理解,自动化工具难以检测,通常需人工审计或逆向分析
支付逻辑绕过(如重复提交优惠码、金额篡改)
权限绕过(通过修改URL参数访问他人数据)
资源滥用(如无限刷取优惠券、积分)
业务逻辑漏洞场景依赖性强,通常与具体业务场景相关(如电商、金融、社交平台),因此不同行业的分布差异较大
业务逻辑漏洞挖掘核心步骤
1. 参数篡改测试
目标:尝试修改参数绕过业务规则。
常见场景:
金额篡改:将订单金额从100改为0.01(如POST /pay?amount=0.01)。
数量溢出:将商品数量改为负数(如quantity=-1)或极大值(如quantity=999999)。
时间戳绕过:修改时间参数(如expiry=9999999999)绕过有效期。
工具:Burp Suite Repeater、Postman手动发送修改后的请求。
2. 权限与状态机绕过
越权访问:
修改URL中的用户ID(如/user/123/profile → /user/456/profile)。
伪造权限标识(如admin=1)。
状态机绕过:
例如:在未完成“订单支付”状态时,直接访问“发货”接口。
3. 业务流程绕过
跳过必要步骤:
例如:在电商系统中,跳过“选择商品”直接提交订单。
重复提交:
多次提交同一请求(如重复领取优惠券)。
逻辑条件覆盖:
分析业务规则的条件分支(如if (A && B)),尝试绕过其中一个条件。
4. 资源滥用与竞争条件
资源耗尽:
无限刷取积分、优惠券(如循环调用/api/addPoints)。
竞态条件:
利用接口无状态特性,同时发送多个请求(如双花攻击)。
示例:在支付过程中,快速发送多次支付请求,观察是否重复扣款。
自动漏洞扫描工具
AWVS
Acunetix Web Vulnerability Scanner(AWVS)
可以扫描任何通过Web浏览器访问和遵HTTP/HTTPS规则的Web站点。适用于任何中小型和大型企业的内联网、外延网和面向客户、雇员、厂商和其它人员的Web网站。可以通过检查SQL注入攻击漏洞、XSS跨站脚本攻击漏洞等漏洞来审核Web应用程序的安全性。
AWVS会扫描整个网络,通过跟踪站点上的所有链接和robots.txt来实现扫描,扫描后AWVS就会映射出站点的结构并显示每个文件的细节信息。在上述的发现阶段或者扫描过程之后,AWVS就会自动地对所发现的每一个页面发动一系列的漏洞攻击,这实质上是模拟一个黑客的攻击过程(用自定义的脚本去探测是否有漏洞) 。WVS分析每一个页面中需要输入数据的地方,进而尝试3所有的输入组合。这是一个自动扫描阶段 。在它发现漏洞之后,AWVS就会在“Alerts Node(警告节点)”中报告这些漏洞,每一个警告都包含着漏洞信息和如何修补漏洞的建议。在一次扫描完成之后,它会将结果保存为文件以备日后分析以及与以前的扫描相比较,使用报告工具,就可以创建一个专业的报告来总结这次扫描。
主菜单功能介绍:主菜单共有5个模块,分别为Dashboard、Targets、Vulnerabilities、Scans和Reports。
Dashboard:仪表盘,显示扫描过的网站的漏洞信息
Targets:目标网站,需要被扫描的网站
Vulnerabilities:漏洞,显示所有被扫描出来的网站漏洞
Scans:扫描目标站点,从Target里面选择目标站点进行扫描
Reports:漏洞扫描完成后生成的报告
设置菜单功能介绍:设置菜单共有8个模块,分别为Users、Scan Types、Network Scanner、Issue Trackers、Email Settings、Engines、Excluded Hours、Proxy Settings
Users:用户,添加网站的使用者、新增用户身份验证、用户登录会话和锁定设置
Scan Types:扫描类型,可根据需要勾选完全扫描、高风险漏洞、跨站点脚本漏洞、SQL 注入漏洞、弱密码、仅爬网、恶意软件扫描
Network Scanner:网络扫描仪,配置网络信息包括地址、用户名、密码、端口、协议
Issue Trackers:问题跟踪器,可配置问题跟踪平台如github、gitlab、JIRA等
Email Settings:邮件设置,配置邮件发送信息
Engines:引擎,引擎安装删除禁用设置
Excluded Hours:扫描时间设置,可设置空闲时间扫描
Proxy Settings:代理设置,设置代理服务器信息)
fscan
Fscan 是一款专为内网渗透测试设计的 综合扫描工具,集成了端口扫描、服务探测、漏洞检测等多种功能,旨在帮助安全人员快速发现内网中的资产和漏洞。其简单易用、功能强大,支持一键自动化扫描,是内网渗透测试的必备工具。
基本用法
Fscan 的基本命令格式如下:
./fscan [选项] [参数]
例如,扫描指定 IP 范围的常见端口:
./fscan -h 192.168.1.1/24
常用命令示例
扫描指定 IP 和端口
./fscan -h 192.168.1.1 -p 22,80,3306
扫描 IP 范围并指定输出文件
./fscan -h 192.168.1.1/24 -o result.txt
使用内置字典进行密码爆破
./fscan -h 192.168.1.1 -m ssh
参数说明
| 参数 | 说明 | 示例 |
|---|---|---|
| -h | 指定主机或 IP 范围 | -h 192.168.1.1/24 |
| -p | 指定端口,多个端口用逗号分隔 | -p 80,443,3389 |
| -m | 指定爆破模式 | -m ssh,mysql,mssql |
| -o | 指定输出文件 | -o result.txt |
| -user | 指定爆破用户名 | -user admin |
| -pwd | 指定爆破密码 | -pwd 123456 |
| -t | 指定线程数 | -t 1000 |
| -time | 指定超时时间 | -time 3 |

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









