




 本文详细介绍了在Windows 10系统下安装和使用Kettle进行ETL操作的步骤,包括从下载到配置CDH集群的全过程。在安装过程中可能会遇到的错误,如数据库连接、中文乱码、Hadoop配置等问题,文中都提供了相应的解决方案。
本文详细介绍了在Windows 10系统下安装和使用Kettle进行ETL操作的步骤,包括从下载到配置CDH集群的全过程。在安装过程中可能会遇到的错误,如数据库连接、中文乱码、Hadoop配置等问题,文中都提供了相应的解决方案。
kettle的安装与使用(windows下)亲测
关于报错请下滑到末尾,有我遇到的错误,及其解决方案
环境
- windows 10系统
- cdh集群 (版本号是5.10)
步骤
- 下载安装kettle
- 如何下载
百度搜索kettle会出现kettle的官网,在官网上面下载就好了!
地址:kettle 8.2下载地址
下载可能会有点慢,在这个过程当中,我的任务还失败了一次,然后我选择了使用迅雷进行下载。
操作:复制下载链接然后打开迅雷新建任务,然后粘贴并且下载,就,速度很快(但是下载得到的文件没有后缀名,照样用好压给解压了)
如下图所示:

没错,不要怀疑自己,这个就是kettle 8.2
解压之后的样子:

打开之后的样子
这样,kettle就在windows下安装完毕了,好的,下班!(才没有)
- 如何下载
使用kettle
因为我们是在windows下的环境当中,所以我们在这个文件夹里面找到spoon.bat文件,找到之后打开它:
然后。。。(屏幕上会出现一个黑窗口,一闪而过的那种,然后啥都没有)我就疯了,这玩意儿打开好像是有点慢,但是问题不大,我有耐心,最后还是打开了。
打开之后的样子
接下来我们测试一个小例子,我们将mysql数据库中的一个表的内容加载到hdfs上
首先:
- 点击新建->转换(出现的效果如下)

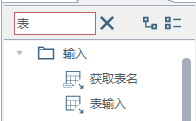
- 点击输入,找到表输入,可以在那个搜索框内直接搜索表输入。
3. 然后点击表输入按钮,进行表的配置,配置数据库的一些相关信息
点击之后会出现这样的一个图标(在右侧的主界面上)

4. 双击之后,出现如下的配置配置栏选项
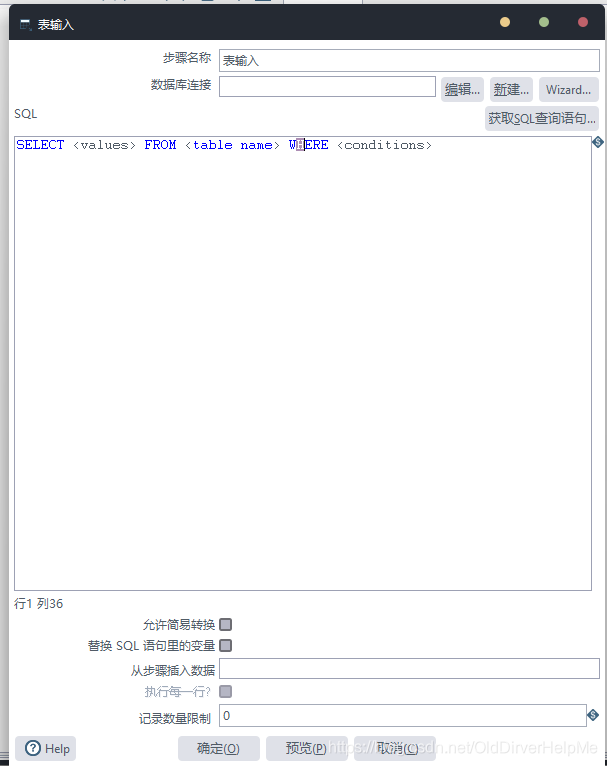
| 选项 | 解释 |
|---|---|
| 步骤名称 | 写给自己看的名称,想叫什么叫什么 |
| 数据库连接 | 就是新建一个数据库的连接配置 |
| SQL | 就是结构化查询语言(Struct Query Language)自己看着办啦 > _ < |
| 对于SQL语句下面的参数填写 | 嗯,这些我都没用到,所以我不好胡说八道,但是通过名称很好理解 |
- 新建数据库的配置:
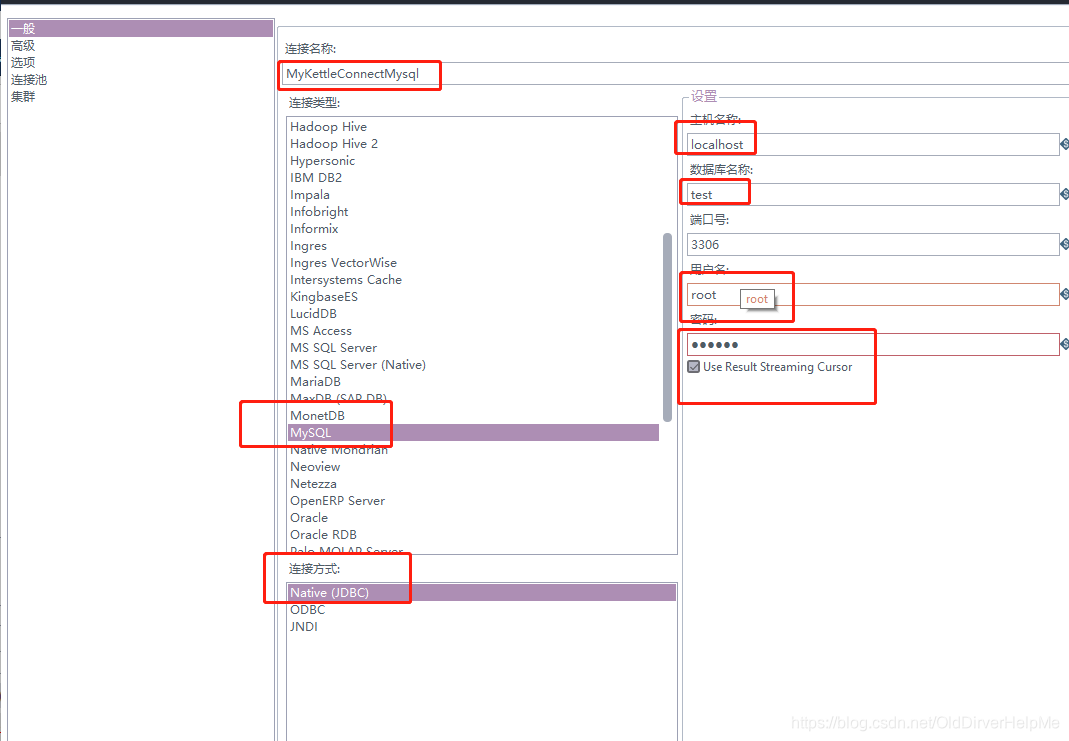
上图就是一个简单的数据库的配置,要自己填写的我都用红色的框子圈起来了,这样的话,对照自己的情况,自己修改一下。
修改完了之后,返回上一步继续配置。
点击测试的时候,可能汇报一个这样的错误:
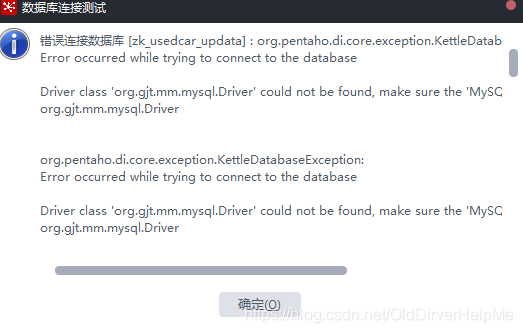
这是因为少了一个mysql-connector-java-5.1.41-bin.jar这样的jar包
下载完毕之后,解压这个文件放到data-integration\lib下面重启kettle然后再试,就不会出现相关的问题了 - 配置完毕之后,可以单击预览
这里会出现一个中文乱码的问题,我们留到后面再讲。
集群配置详细操作:
- 首先 看看这个地方里面是否显示了自己的cdh的版本
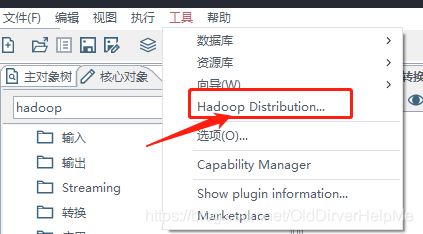
kettle 8.2中默认自带的是CDH5.14,然后我自己的CDH版本是5.10(上文中有提到过,可以在官网里面查看对组件的支持)
对于这个问题的解决方案 ,就是去官网中下载shim包:
下载地址:shim包下载地址
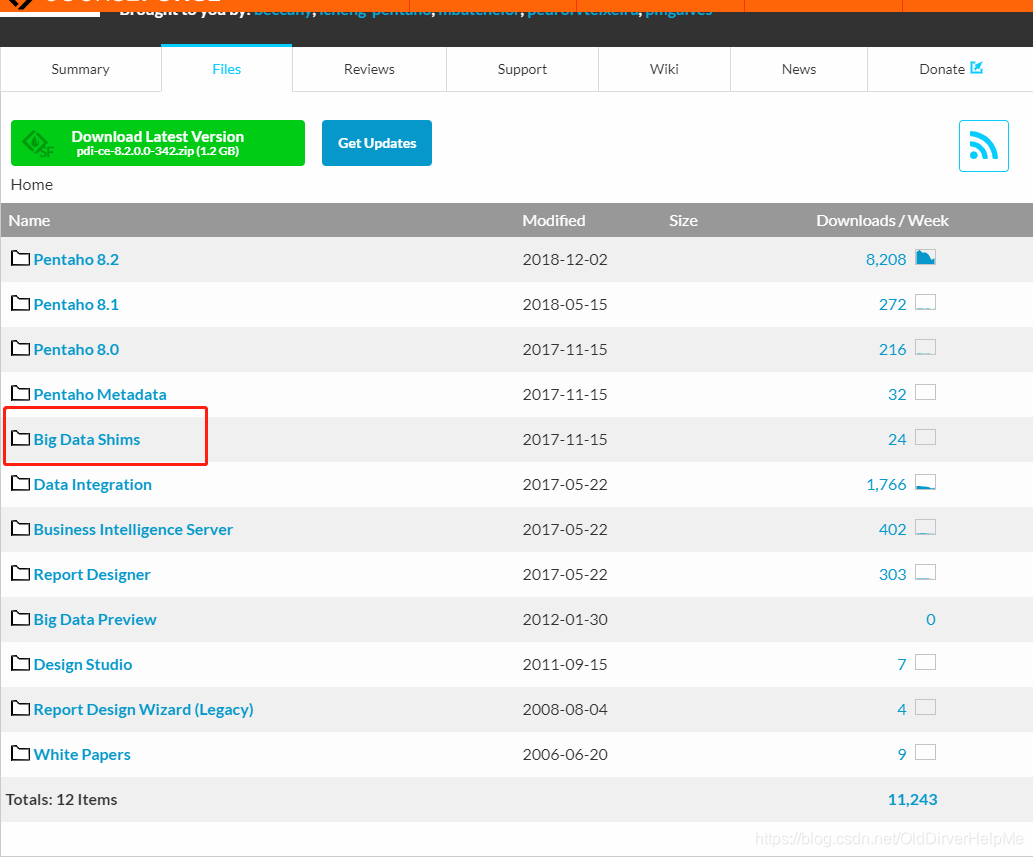
在红色的框子里面,点进去会出现各个版本号,然后一个一个找一下对应自己CDH的包
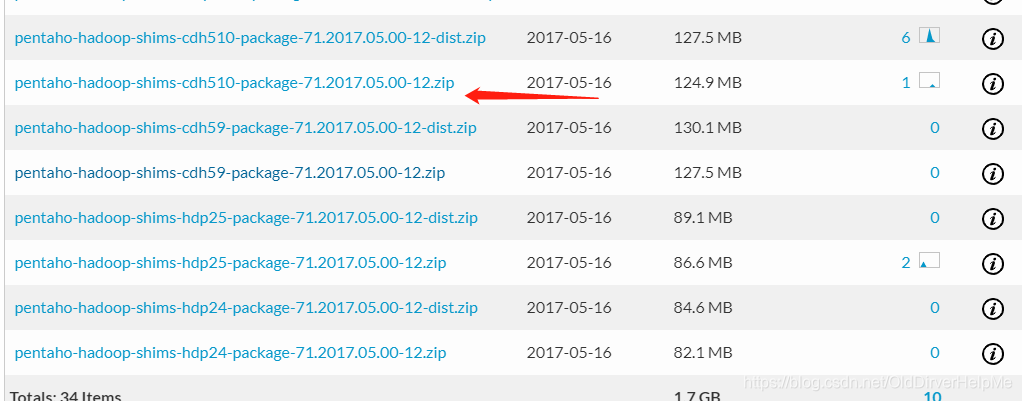
这个就是对应我这个CDH的版本shim包,在7.1下面,将它下载了之后并且解压,然后将这个文件夹复制到
data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations这个路径下面,并且将集群中的hdfs-core.xml,yarn.xml,hdfs-site.xml,mapred-site.xml放入到上述的文件夹里面我的data-integration就是我的kettle的文件名,然后关闭kettle重新启动kettle,
并且修改\data-integration\plugins\pentaho-big-data-plugin\plugin.properties
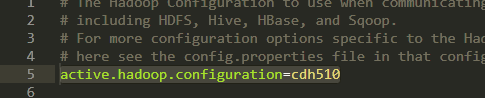
我的CDH是5.10 所以要改成cdh510
重复下面的过程
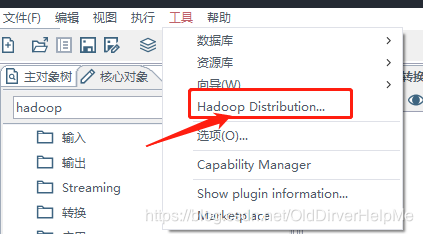
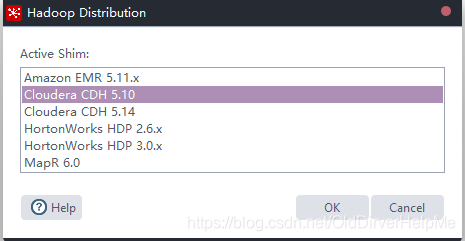
这个操作,会发现里面出现了CDH 5.10,这个就是自己自己的CDH版本,选中它,然后选择OK
这里我们开始进行对输出源的配置,输出的源配置如下:
找到输出的源:搜索hadoop然后就会在big data文件下面显示出一个hadoop file output
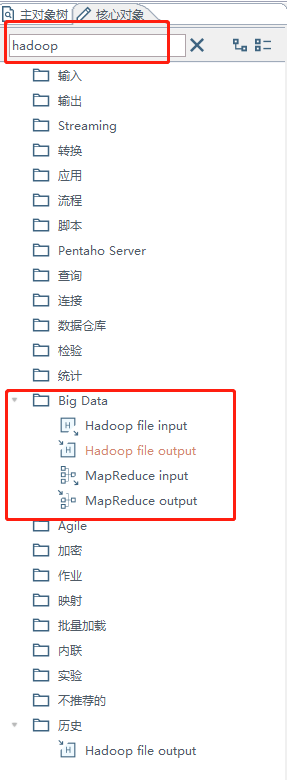
确认过眼神,就是它了
双击选中,然后再主界面的时候编辑配置
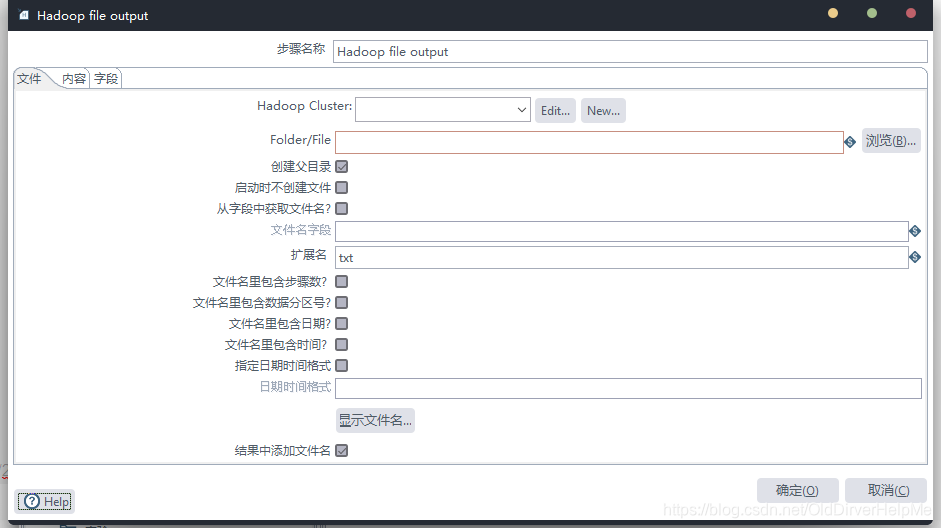
### 注意,这里的集群配置比较头痛
我第一次配置完了之后只有两个绿色的(√√)勾勾,但是我最后还是全部解决掉了!开心!
配置界面如下
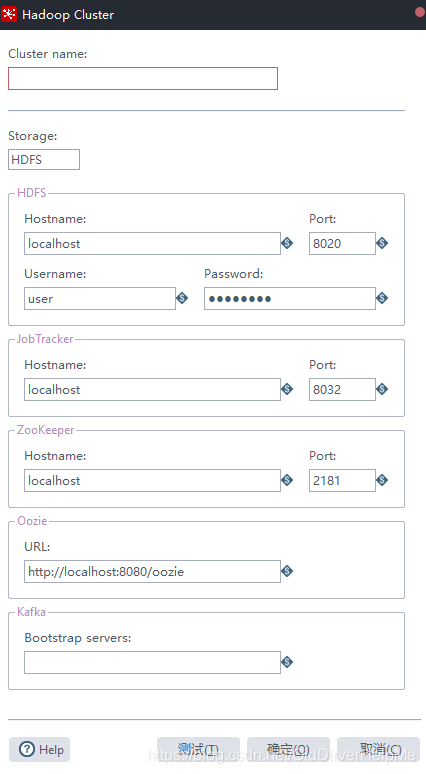
| 属性名 | 解释 |
|---|---|
| cluster name | 自己设置,方便自己记忆 |
| Storage | 存储类型 |
| HDFS hostname | hdfs的地址(如果是集群的话就不要配置端口号) |
| username | 服务器的登录用户名 |
| jobTracker | 这个设置jobTracker(如果是集群的话就不要配置端口号) |
| zookeeper hostname | 这个设置zk的地址(如果是集群的话就不要配置端口号) |
| oozie | 写oozie的地址,我上CDH看了下,我这边的端口号不是8080是11000 |
| 配置kafka的服务器地址 | 端口号9092(最好自己查看一下CDH) |
编辑完毕之后测试一下
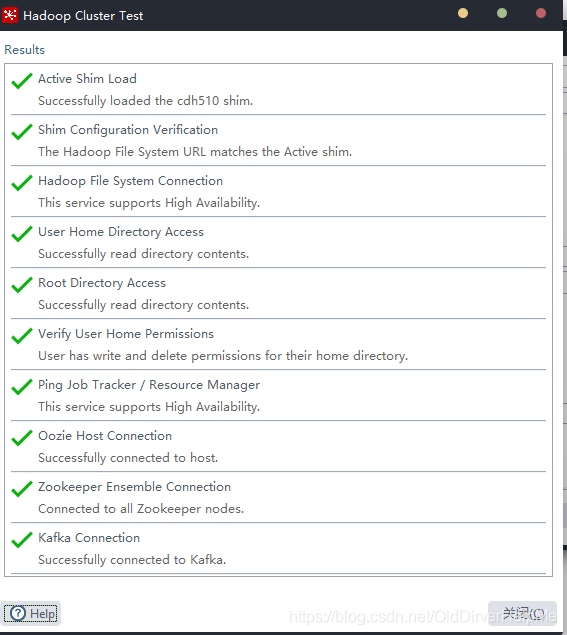
正常的的样子是如上图所示。不正常会出现什么问题呢?文末统一说,遇到问题可以看文末。
接下来就配置完成了,回到下面这个界面
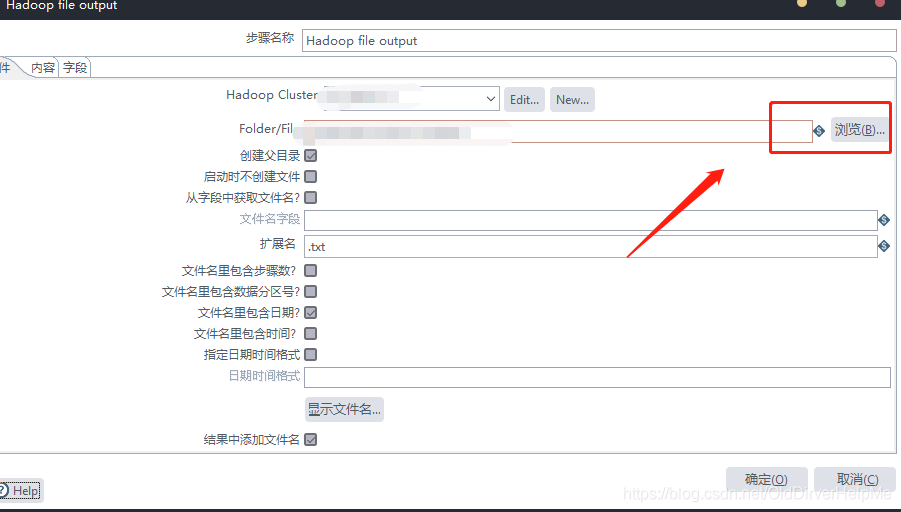
点击浏览,找一个目录,然后存放数据,选择完毕之后,看下还有没有其他选项需要的,选择完毕之后,点击确定,并且
保存这个文件! 文件->保存
然后生成一个.ktr文件留着备用
开始执行任务:
任务的执行
我们新建一个作业,提示:下面的操作用双击:
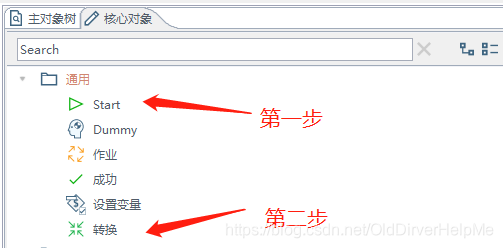
生成如下结果
左边的那个东西可以选择配置,也可以选择不配置,不配置的话跑一次就完事儿了。在转换那里点击配置:
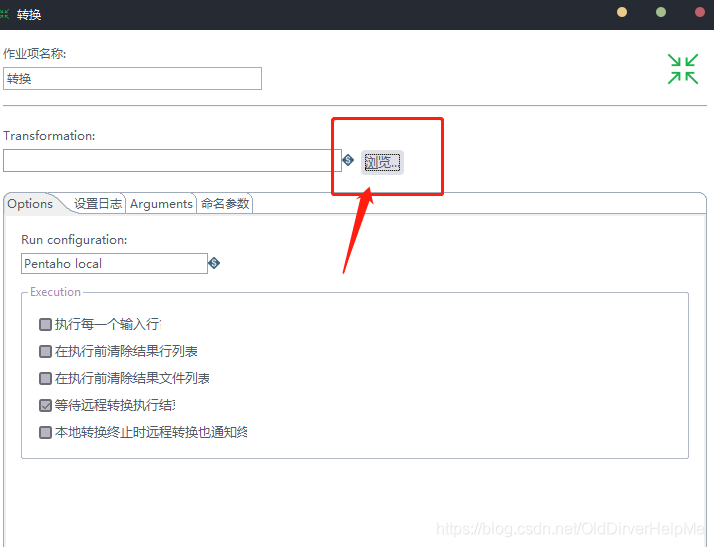
在浏览中找到刚才保存的ktr文件,这样的话,就可以将这个ktr文件执行了,选中了这个ktr文件之后开始执行。等待执行结果就好了,如果执行的过程中有错误的话,可能是在hadoop out file(就是对于输出文件的配置方面有问题)嗯,要去检查一下配置相关
最后就可以在hdfs上面看到加载的文件了。
相关的错误进行解答
1.mysql连接报错:
这是因为少了一个mysql-connector-java-5.1.41-bin.jar这样的jar包,下载地址:
点我下载
2.中文乱码,在spoon.bat的jvm 参数配置后面增加一个“-Dfile.encoding=utf-8”
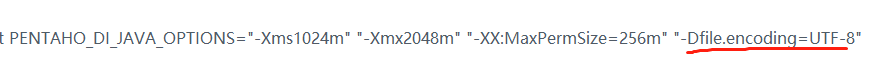
3.配置hadoop的时候会出现User home directory access 报错:
尝试一下在hdfs的根目录下的user文件夹下面创建一个自己windows系统用户的文件夹比如最后在hdfs上有一个/user/administrator这个文件夹
4.verify user home permission 这个地方出现问题
解决方案
data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\cdh510
在这个文件夹中找到config.properties文件,打开之后
末尾添加
authentication.superuser.provider=NO_AUTH
最后重启kettle


















 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









