




 本文介绍了如何使用Scrapy框架从豆瓣电影网站抓取Top250电影数据,包括电影名、评分、导演等信息,并通过DoubanPipeline将数据保存到Excel中。重点展示了XPath选择器的运用和meta字典在请求传递中的作用。
本文介绍了如何使用Scrapy框架从豆瓣电影网站抓取Top250电影数据,包括电影名、评分、导演等信息,并通过DoubanPipeline将数据保存到Excel中。重点展示了XPath选择器的运用和meta字典在请求传递中的作用。
文章目录
Scrapy提取豆瓣电影数据
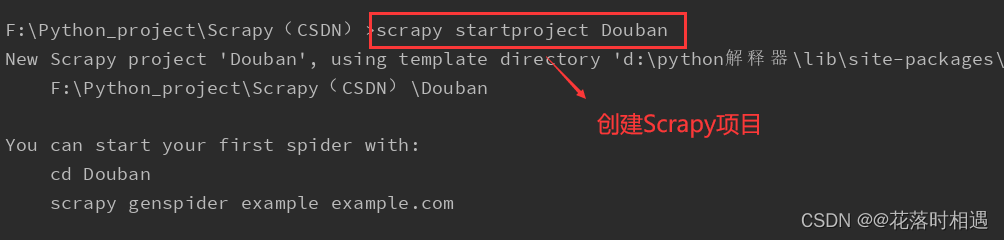
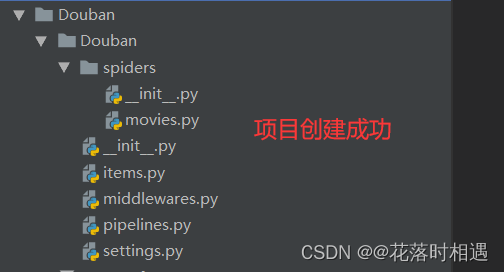
创建项目

movies.py
import scrapy
from ..items import DoubanItem
class MoviesSpider(scrapy.Spider):
name = 'movies'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250?start=0&filter=']
def parse(self, response):
# 实例化item对象
item = DoubanItem()
# 获取每部电影的详细链接
info_links = response.xpath('//div[@class="info"]/div/a/@href').getall()
# 对每个详细链接进行解析
for info_link in info_links:
yield scrapy.Request(info_link, callback=self.parse_info, meta={'item': item})
# 拼接下一页链接,并交给parse进行解析
for i in range(9):
link = f'https://movie.douban.com/top250?start={(i+1)*25}&filter='
yield scrapy.Request(link, callback=self.parse)
def parse_info(self, response):
# 获取item
item = response.meta['item']
# 获取电影名
item['name'] = response.xpath('//div[@id="wrapper"]/div/h1/span/text()').get()
# 获取导演
item['director'] = response.xpath('//div[@id="info"]/span[1]/span/a/text()').getall()
# 获取编剧
item['screenwriter'] = response.xpath('//div[@id="info"]/span[2]/span/a/text()').getall()
# 获取主演
item['to_stars'] = response.xpath('//a[@rel="v:starring"]/text()').getall()
# 类型
item['types'] = response.xpath('//span[@property="v:genre"]/text()').getall()
# 获取上映日期
item['initialReleaseDate'] = response.xpath('//span[@property="v:initialReleaseDate"]/text()').getall()
# 获取片长
item['runtime'] = response.xpath('//span[@property="v:runtime"]/text()').get()
# 获取电影简介
item['summary'] = response.xpath('//span[@property="v:summary"]/text()').get()
# 获取电影评分
item['average'] = response.xpath('//strong[@property="v:average"]/text()').get()
yield item
items.py
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
director = scrapy.Field()
screenwriter = scrapy.Field()
to_stars = scrapy.Field()
types = scrapy.Field()
initialReleaseDate = scrapy.Field()
runtime = scrapy.Field()
summary = scrapy.Field()
average = scrapy.Field()
pipelines.py
import openpyxl
from openpyxl.styles import Font, Side, Alignment, Border
class DoubanPipeline:
def process_item(self, item, spider):
return item
class Douban250Pipeline:
def open_spider(self, spider): # 爬虫开始时执行一次
self.f = openpyxl.Workbook()
self.sheet = self.f.create_sheet('豆瓣250')
# 构建表头
self.sheet.append(['电影名', '评分', '导演', '编剧', '主演', '类型', '上映日期', '片长', '电影简介'])
# 设置字体样式
self.algn = Alignment(vertical='center', horizontal='center')
self.font = Font(name='宋体', size=12)
side = Side(style='thin', color='000000')
self.border = Border(top=side, left=side, right=side, bottom=side)
for i in self.sheet[1]:
i.alignment = self.algn
i.font = self.font
i.border = self.border
# 修改列宽
self.sheet.column_dimensions['A'].width = 20
self.sheet.column_dimensions['C'].width = 20
self.sheet.column_dimensions['D'].width = 20
self.sheet.column_dimensions['E'].width = 20
self.sheet.column_dimensions['F'].width = 20
self.sheet.column_dimensions['G'].width = 20
self.sheet.column_dimensions['H'].width = 15
self.sheet.column_dimensions['I'].width = 30
def process_item(self, item, spider):
# 把传递数据的载体item对象转为一个字典
dic_item = dict(item)
row_max = self.sheet.max_row + 1
# 设计字体样式
for k in self.sheet[row_max]:
k.alignment = self.algn
k.font = self.font
k.border = self.border
# 写入电影名
self.sheet.cell(row_max, 1).value = dic_item['name']
# 写入评分
self.sheet.cell(row_max, 2).value = dic_item['average']
# 写入导演
director = ''
for i in item['director']:
director += i + '、'
self.sheet.cell(row_max, 3).value = director[:-1]
# 写入编剧
screenwriter = ''
for i in item['screenwriter']:
screenwriter += i + '、'
self.sheet.cell(row_max, 4).value = screenwriter[:-1]
# 写入主演
to_stars = ''
for i in item['to_stars']:
to_stars += i + '、'
self.sheet.cell(row_max, 5).value = to_stars[:-1]
# 写入类型
types = ''
for i in item['types']:
types += i + '、'
self.sheet.cell(row_max, 6).value = types[:-1]
# 写入上映日期
initialReleaseDate = ''
for i in item['initialReleaseDate']:
initialReleaseDate += i + '、'
self.sheet.cell(row_max, 7).value = initialReleaseDate[:-1]
# 写入片场
self.sheet.cell(row_max, 8).value = dic_item['runtime']
# 写入电影简介
self.sheet.cell(row_max, 9).value = dic_item['summary']
return item
def close_spider(self, spider):
self.f.save('豆瓣250.xlsx')
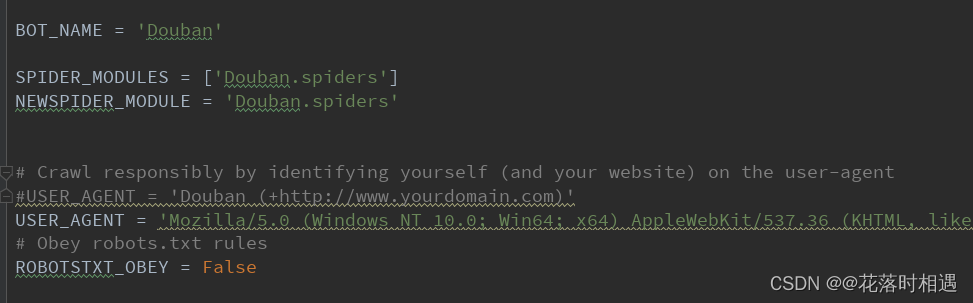
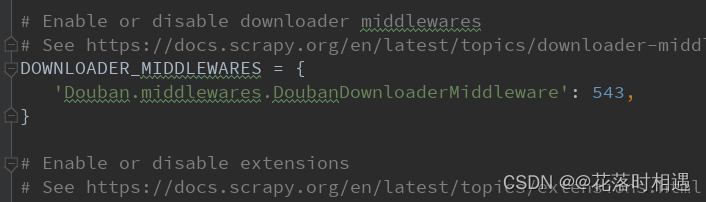
settings.py
运行结果

代码部分讲解说明
get()
response.xpath(……).get() 表示获取一个元素
getall()
response.xpath(……).getall() 表示获取多个元素
meta = {‘item’ : item}
yield scrapy.Request(info_link, callback=self.parse_info, meta={‘item’: item})
meta={‘item’: item} 表示向self.parse_info() 传入item
def parse_info(self, response):
# 获取item
item = response.meta['item']
pipelines.py的文件保存
- def open_spider(self, spider) – 爬虫开始时执行一次该函数(也就是整个运行只执行一次),该函数主要用来打开和创建文件。
- def process_item(self, item, spider) – 此函数为文件写入,根据爬虫文件(movies.py)文件中的yield item 获取item并写入文件
- def close_spider(self, spider) – 爬虫结束时执行一次该函数(也就是整个运行只执行一次),该函数主要用来保存和关闭文件。


















 1464
1464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











