




 本文介绍了Tesseract OCR的安装与配置,包括环境变量设置、语言包配置和CMD命令行的操作。通过实例展示了如何在CMD中进行图片文字识别,以及在PyCharm中利用pytesseract库进行相同操作。此外,还提供了所需模块的安装方法。
本文介绍了Tesseract OCR的安装与配置,包括环境变量设置、语言包配置和CMD命令行的操作。通过实例展示了如何在CMD中进行图片文字识别,以及在PyCharm中利用pytesseract库进行相同操作。此外,还提供了所需模块的安装方法。
一、准备
1、安装Tesseract-OCR
- 64位的安装包链接
- tesseract各种语言集合包
tesseract各种语言集合包 https://pan.baidu.com/s/1hQIJgUJe5MUTyimyLU_uQw
https://pan.baidu.com/s/1hQIJgUJe5MUTyimyLU_uQw
二、环境变量的配置
下载好Tesseract-OCR文件后,找到tesseract.exe所在的文件路径,复制该文件所在的路径,并在环境变量中的用户变量和系统变量的Path中添加该路径。
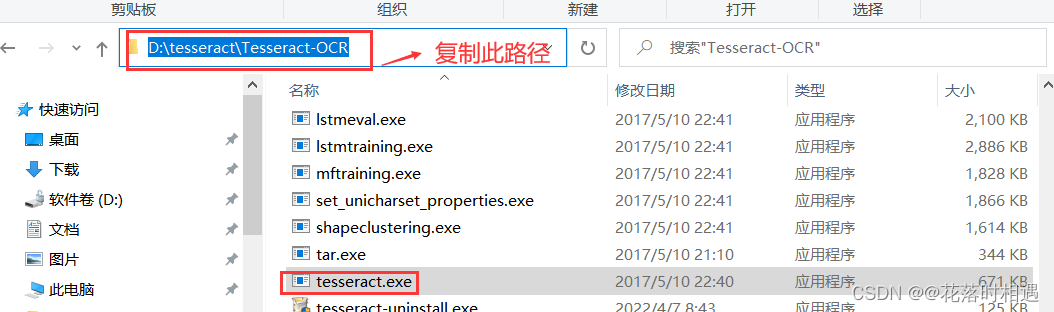
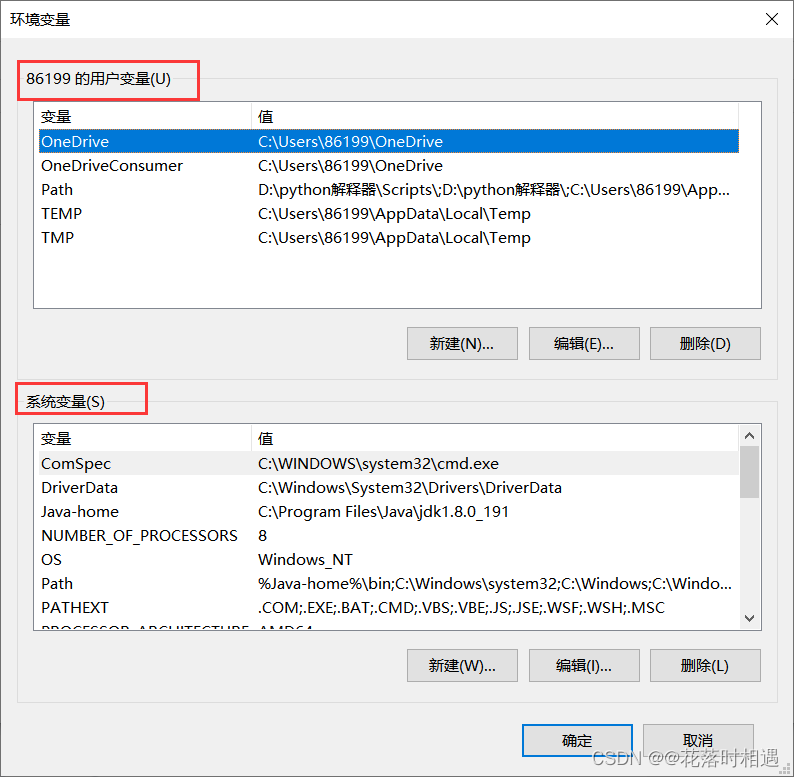
然后进入Tesseract-OCR的文件夹中找到tessdata文件夹并进入(此文件夹中包含的是各种语言包,提供识别功能)并复制此路径,然后在系统变量中点击新建,添加一个系统变量,变量名为TESSDATA_PREFIX,变量值为tessdata文件夹的路径。
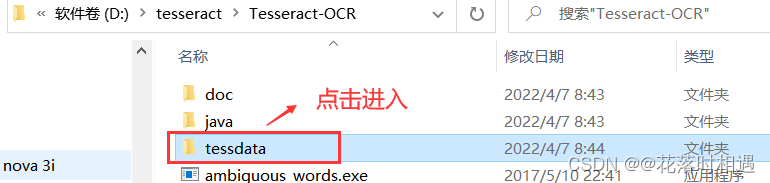
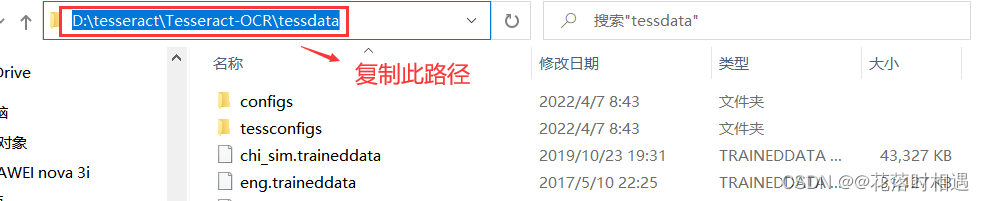
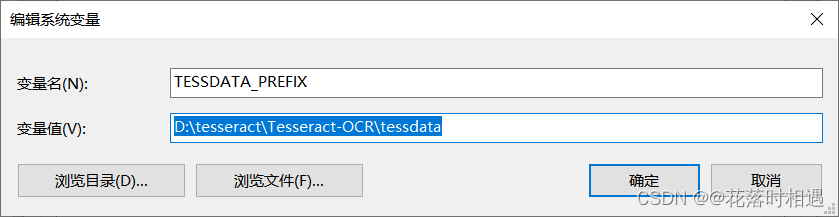
检测环境变量是否安装成功
打开cmd命令框并输入tesseract后回车,如果出现以下内容则表示环境变量安装成功
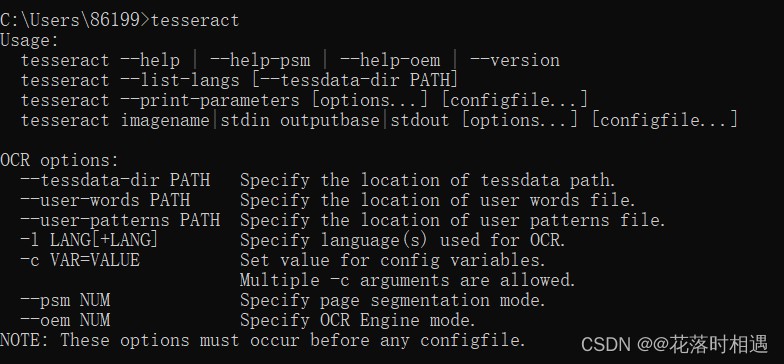
三、语言包的配置使用
下载好语言包并解压后点击进入文件,即可看见里面有很多语言包(chi_sim是中文识别包,equ是数学公式包,eng是英文包 )
- 若想识别某一种语言,即可复制或移动到tesseract文件夹中
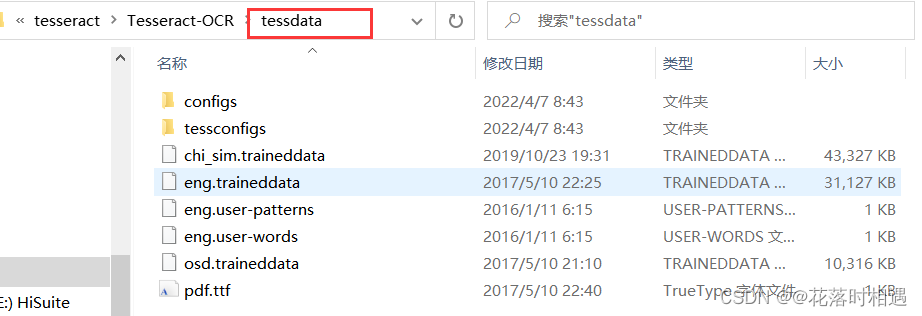
四、CMD命令框中进行图片识别操作
- 首先进入所要识别图片所在的路径
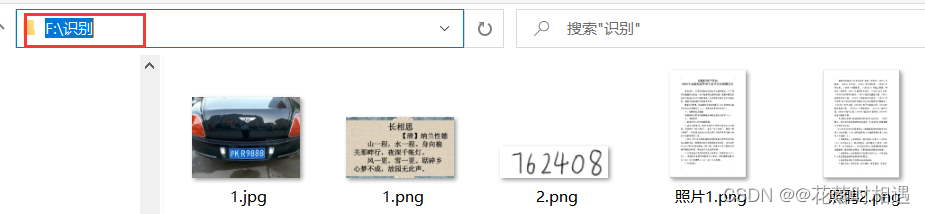
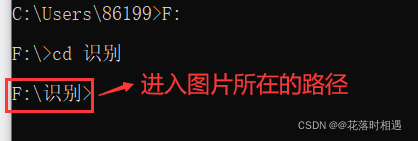
举例一:识别数字
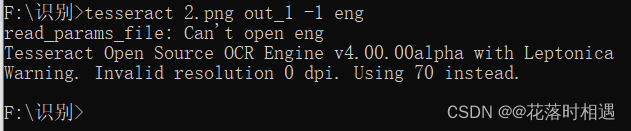
- 然后输入命令进行图片文字的识别
命令(举例):tesseract 2.png out_1 -1 eng
2.png:图片名称
out_1:识别后形成的文本文件名称
eng:识别的是数字或英文
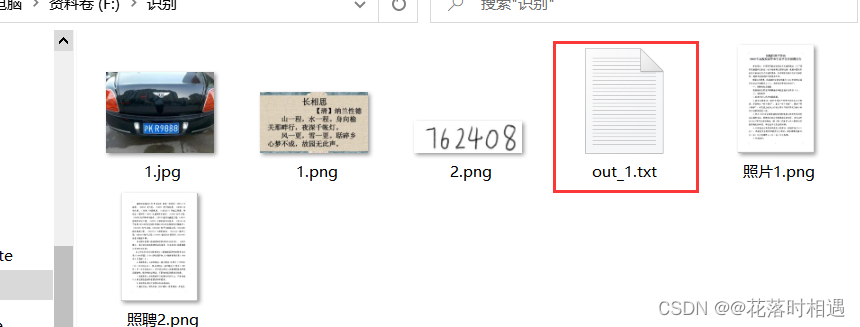
- 运行结束后即可看到在图片的同路径下生成了一个out_1的文本文件,文件中的内容就是识别出的内容。

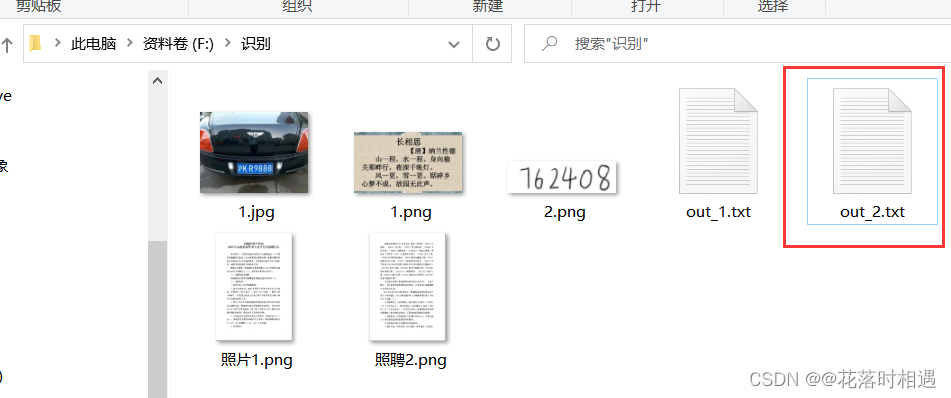
举例二:识别文字
命令(举例):tesseract 1.png out_2 -l chi_sim
1.png:图片名称
out_2:识别后形成的文本文件名称
chi_sim:识别的是中文


5、pycharm中进行图片识别操作
需要下载的模块:
pip install PIL
pip install pytesseract
from PIL import Image
from pytesseract import pytesseract
a = pytesseract.image_to_string(Image.open('F:/识别/1.png'), lang='chi_sim')
print(a)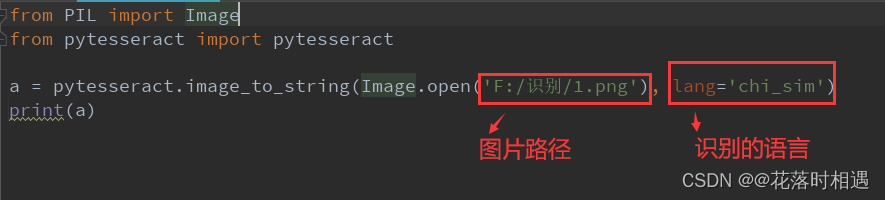



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











