




一、引言:爬取背景与合规声明
在电商运营、竞品分析、市场调研等场景中,淘宝商品详情页的公开数据(如商品标题、价格、销量、详情图等)具有重要参考价值。但需明确:本文仅针对淘宝平台公开可访问的数据,爬取过程严格遵守《网络安全法》《电子商务法》等法律法规,不侵犯用户隐私与平台商业秘密,且需遵守淘宝平台《robots 协议》及用户服务条款,禁止高频次、大规模爬取影响平台正常运营。
本文将完整分享从环境搭建、接口分析、数据爬取到 API 封装的全流程,并提供可直接使用的封装 API 示例,帮助技术开发者快速实现合法的数据获取需求。
二、前期准备:环境与工具搭建
2.1 开发环境配置
推荐使用 Python 3.8 + 版本(兼容性强、生态完善),核心依赖库如下:
# 安装核心库
pip install requests # 发送HTTP请求
pip install fastapi # 封装API(轻量高效)
pip install uvicorn # 运行API服务
pip install python-dotenv # 管理环境变量(保护敏感信息)
pip install beautifulsoup4 # 可选:解析HTML格式数据2.2 关键参数准备
爬取淘宝商品数据需提前获取 3 类核心参数,且需通过个人正常账号操作,禁止盗用他人信息:
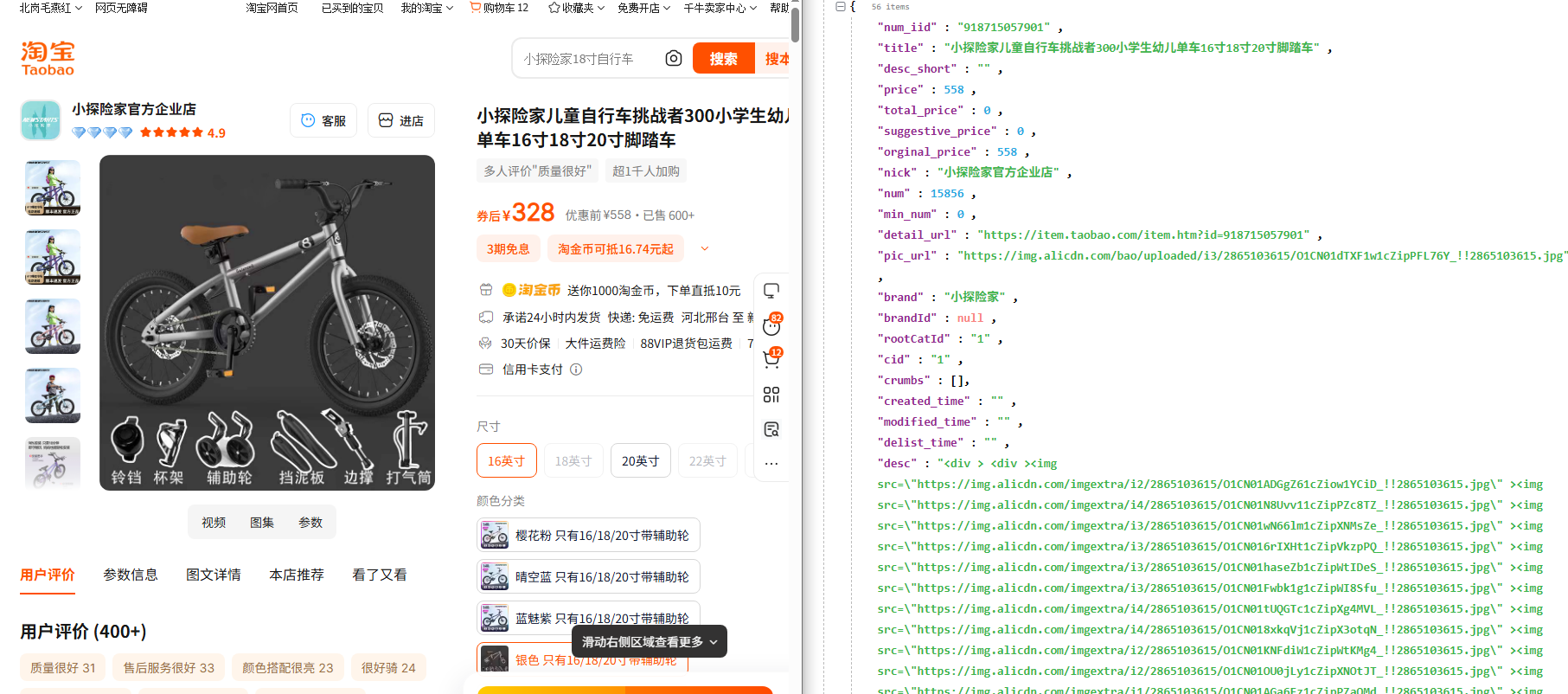
- 商品 ID(num_iid):从淘宝商品详情页 URL 中提取,例如https://item.taobao.com/item.htm?id=123456789,其中123456789即为商品 ID。
- User-Agent:模拟浏览器请求,避免被识别为爬虫。可在 Chrome 浏览器按F12→Network→任意请求→Headers中复制User-Agent,示例:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36
- Cookie:用于验证用户身份(淘宝部分公开数据需登录态)。同样在浏览器Network请求的Headers中复制Cookie,注意定期更新(Cookie 有效期约 7-15 天)。
2.3 抓包工具使用
需通过浏览器开发者工具分析淘宝商品数据接口,步骤如下:
- 打开淘宝商品详情页,按F12打开开发者工具,切换至Network标签;
- 刷新页面,筛选XHR请求(淘宝动态数据多通过 XHR 加载);
- 在请求列表中搜索含item或detail的关键词(如item_get类请求),找到返回商品核心数据的接口(Response 格式为 JSON);
- 记录该接口的Request URL、Request Method(通常为 GET)及请求参数(如num_iid、timestamp等)。
三、核心爬取过程:从接口分析到数据提取
3.1 接口分析:定位公开数据接口
通过抓包可发现,淘宝商品详情页的公开数据多通过固定格式接口返回,以常见的 “商品基础信息接口” 为例(接口可能随平台更新变化,需重新抓包确认):
- 接口 URL:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









