



为什么不用火车头,因为暂时未发现火车头采集的脚本能自动回复,以为中创网要看到下载地址是需要回复的。所以换了思路用Python写一个代码:这是代码发布效果。
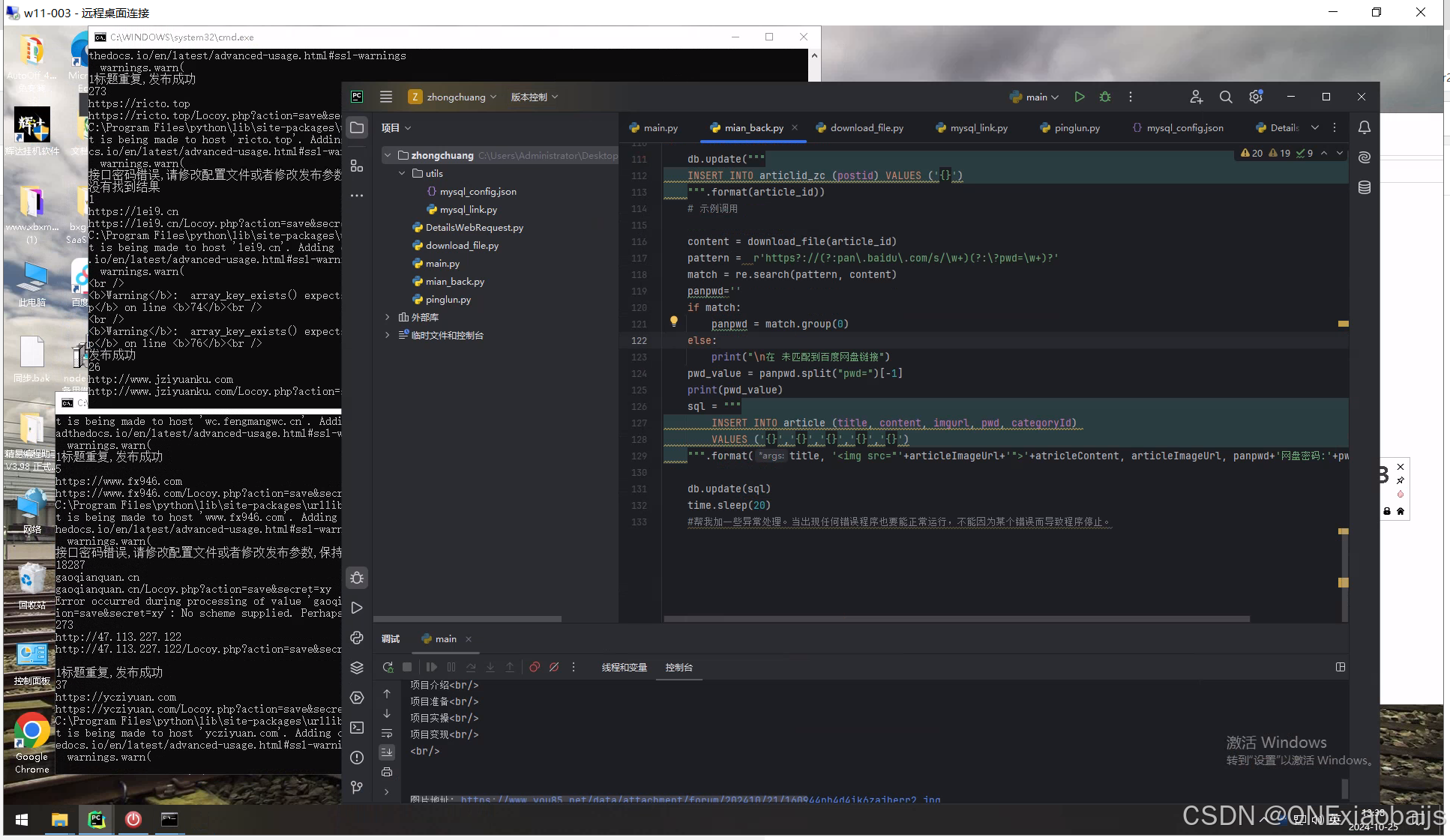
import requests
from bs4 import BeautifulSoup
from pinglun import post_message
import time
from DetailsWebRequest import WebRequest
from utils.mysql_link import db
from download_file import download_file
import re
def get_article_links(url):
# 发送GET请求到指定URL
response = requests.get(url)
# 确保请求成功
if response.status_code != 200:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")
return []
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.content, 'html.parser')
# 找到包含文章链接的div
news_portal = soup.find('div', class_='news_portal bp')
if not news_portal:
print("Could not find the news_portal bp div")
return []
# 在news_portal div中查找所有文章链接
links = []
for a in news_portal.select('.newMod ul li h3 a'):
href = a.get('href')
if href:
links.append(href)
return links
# 使用函数
url = 'https://www.you85.net/'
article_links = get_article_links(url)
# 打印结果
print("文章链接:")
for link in article_links:
article_id = link.split('thread-')[1].split('-')[0]
#先判断文章是否存在采集过,防止网站风控
postid = db.findOne("""
SELECT id FROM articlid_zc WHERE postid='{}'
""".format(article_id))
if postid is not None:
# 如果查询到数据,继续往下面走
# 这里放你想执行的代码
continue
else:
# 如果没有数据,结束本次循环,继续下一次
print(f"处理文章ID: {article_id}")
print(link)
url = "https://www.you85.net/"+link
# 创建 WebRequest 对象
web_request = WebRequest(url)
# 调用 send_request 方法
response_content = web_request.send_request()
# 打印返回的内容
# print(response_content)
soup = BeautifulSoup(response_content, 'html.parser')
# Extract the title from the element with id="thread_subject"
title = soup.find(id="thread_subject").text.strip()
print("Title:", title)
font_tag = soup.find('font', size="4")
atricleContent =''
if font_tag:
# 提取该标签的所有内容,包括嵌套的HTML
content = font_tag.decode_contents()
# 查找 <font color="Red"> 标签的位置
red_font_index = content.find('<font color="Red">')
if red_font_index != -1:
# 如果找到了 <font color="Red"> 标签,只保留它之前的内容
content = content[:red_font_index]
# 去除首尾的空白字符
atricleContent = content.strip()
print(content)
else:
print("未找到 <font size='4'> 标签")
print(article_id)
# 提取 class="byg_shoufei_z z" 中的图片地址
image_div = soup.find('div', class_="byg_shoufei_z z")
articleImageUrl=''
if image_div:
image_tag = image_div.find('img')
if image_tag:
articleImageUrl = ' https://www.xxx5.net/'+ image_tag.get('src')
print("\n图片地址:")
print(articleImageUrl)
else:
print("\n在 class='byg_shoufei_z z' 的 div 中未找到图片")
else:
print("\n未找到 class='byg_shoufei_z z' 的 div")
#发布程序
post_message(article_id)
db.update("""
INSERT INTO articlid_zc (postid) VALUES ('{}')
""".format(article_id))
# 示例调用
content = download_file(article_id)
pattern = r'https?://(?:pan\.baidu\.com/s/\w+)(?:\?pwd=\w+)?'
match = re.search(pattern, content)
panpwd=''
if match:
panpwd = match.group(0)
else:
print("\n在 未匹配到百度网盘链接")
pwd_value = panpwd.split("pwd=")[-1]
print(pwd_value)
sql = """
INSERT INTO article (title, content, imgurl, pwd, categoryId)
VALUES ('{}','{}','{}','{}','{}')
""".format(title, '<img src="'+articleImageUrl+'">'+atricleContent, articleImageUrl, panpwd+'网盘密码:'+pwd_value, 2)
db.update(sql)
time.sleep(20)
#帮我加一些异常处理。当出现任何错误程序也要能正常运行,不能因为某个错误而导致程序停止。
完整版:www.baipiaozhong.xyz

















 1847
1847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









