




点击上方“中兴开发者社区”,关注我们
每天读一篇一线开发者原创好文
译者:XTH
英文原文:https://www.codeproject.com/Articles/1197167/Random-Forest-Python
随机森林介绍
随机森林是一种在集成学习中很受欢迎的算法,可用于分类和回归。这意味着随机森林中包括多种决策树,并将每个决策树结果的平均值作为随机森林的最终输出。决策树有一些缺点,比如训练集的过拟合导至很高的差异性,不过这在随机森林中已经可以通过Bagging(Bootstrap Aggregating)的帮助解决。因为随机森林实际上是由多种不同的决策树组成的,所以我们最好先了解一下决策树算法,然后再学习随机森林的相关知识。
决策树:
决策树用树形图来查看各元素之间的关系,以尽可能的做出最好的决定。举个例子,现在我们知道有一个网球运动员,他会根据不同的天气条件来选择是否进行比赛。于是现在我们想知道:在第15天的时候他是否会进行比赛呢?
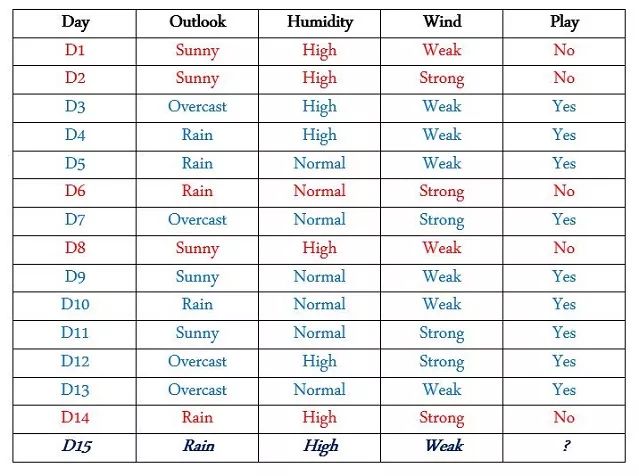
寻找“纯净”分支
这里有15天的数据,其中有9天他进行了比赛,5天没有比赛。你需要仔细观察表中提供的训练数据,其中包括多种特征及各不相同的特征值。我们需要找到哪些特征的特征值对结果的影响是相同的(在该特征值出现时,所有的PLAY = Yes/PLAY = No),或者换句话说,哪个值在表中始终与Play值的颜色相同。
“纯净”分支选择过程:
(Humidity = High For all days: (Play = Yes) | (Play = No)) No
(Humidity = Normal For all days: (Play = Yes) | (Play = No)) No
(Wind = Weak For all days: (Play = Yes) | (Play = No)) No
(Wind = Strong For all days: (Play = Yes) | (Play = No)) No
(Outlook = Rain For all days: (Play = Yes) | (Play = No)) No
(Outlook = Sunny For all days: (Play = Yes) | (Play = No)) No
(Outlook = Overcast For all days: (Play = Yes) | (Play = No)) Yes √
所以我们的运动员总是在"outlook = overcast"(D3,D7,D12,D13)时参加比赛,所以我们应该将"outlook"这个特征作为我们的根节点,并从其开始继续寻找分支。接下来我们寻找特征"Outlook = Sunny"(D1,D2,D8,D9,D11)条件下的“纯净”分支,查看"humidity"和"wind"的哪个特征值
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









