




 本文详细介绍了Java中Object类的clone方法实现浅拷贝和深拷贝的区别及实现方式,探讨了toString、equals、hashCode等方法的原理与应用,并深入解析了wait、notify与synchronized等同步机制。
本文详细介绍了Java中Object类的clone方法实现浅拷贝和深拷贝的区别及实现方式,探讨了toString、equals、hashCode等方法的原理与应用,并深入解析了wait、notify与synchronized等同步机制。
前言:
本文基于JDK1.8。
一、Object类概述
Object类存储在java.lang包中,是所有java类(Object类除外)的终极父类,任何类都默认继承Object。
当然,数组也继承了Object类。然而,接口是不继承Object类的,Object类不作为接口的父类。
Object类中主要有以下API:
toString()
getClass()
equals()
clone()
finalize()
getClass()
notify()
notifyAll()
wait()
注意:
Object类中的getClass(),notify(),notifyAll(),wait()等方法被定义为final类型,因此不能重写。
二、API介绍
1. clone()方法
/**
* Creates and returns a copy of this object...
*/
protected native Object clone()
throws CloneNotSupportedException;
由JDK源码 Object#clone() 方法可知,clone()是一个native即本地方法。源码无法探索其实现方式,由代码上的注释可知,其作用为创造和返回一个对象的复制。
(1) new和clone的异同
在Java语言中, clone方法被对象调用,所以会复制对象。所谓的复制对象,首先要分配一个和源对象同样大小的空间,在这个空间中创建一个新的对象。
在java语言中,有两种方式可以创建对象:
使用new操作符创建一个对象
使用clone方法复制一个对象
这两种方式的异同:
new操作符的本意是分配内存。程序执行到new操作符时, 首先去看new操作符后面的类型,因为知道了类型,才能知道要分配多大的内存空间。分配完内存之后,再调用构造函数,填充对象的各个域,这一步叫做对象的初始化,构造方法返回后,一个对象创建完毕,可以把他的引用(地址)发布到外部,在外部就可以使用这个引用操纵这个对象。
而clone方法在第一步是和new相似的, 都是分配内存。调用clone方法时,分配的内存和源对象(即调用clone方法的对象)相同,然后再使用原对象中对应的各个域,填充新对象的域, 填充完成之后,clone方法返回,一个新的相同的对象被创建,同样可以把这个新对象的引用发布到外部 。
(2) 复制引用与克隆(clone)对象
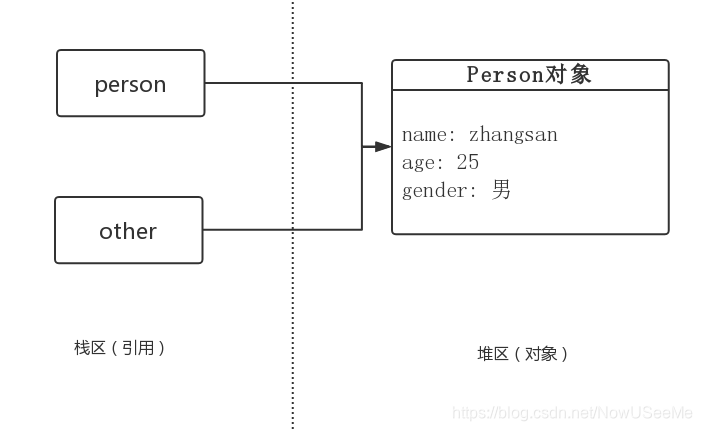
假设现在有Person类,有一个对象 Person person = new Person(“ZhangSan”, 22, “男”);
通常我们会有这样的赋值 Person other = person,这个时候只是简单了copy了一下reference,person和 other 都指向内存中同一个object。
具体代码如下:
// maven jar包引用
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.20</version>
<scope>provided</scope>
</dependency>
// 代码
// Person类
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
public class Person {
private String name;
private int age;
private String gender;
}
//测试类
public class CopyRefrenceDemo {
public static void main(String[] args) {
Person person =
new Person("zhangsan", 25, "男");
Person other = person;
System.out.println(person);
System.out.println(other);
}
}
//运行结果
com.test.clone.Person@61bbe9ba
com.test.clone.Person@61bbe9ba
可以看出,打印的地址值是相同的,既然地址都是相同的,那么肯定是同一个对象。p和p1只是引用而已,他们都指向了一个相同的对象Person(“zhangsan”, 25, “男”) 。 可以把这种现象叫做 引用的复制 。
上面代码执行过程中, 内存中的情景如下图所示:
如果要真正克隆一个对象,只需要做如下修改:
// Person类 添加实现 Cloneable接口和重写clone方法
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
public class Person implements Cloneable {
private String name;
private int age;
private String gender;
@Override
protected Object clone()
throws CloneNotSupportedException {
return super.clone();
}
}
//测试类
public class CloneDemo {
public static void main(String[] args)
throws Exception{
Person person =
new Person("zhangsan", 25, "男");
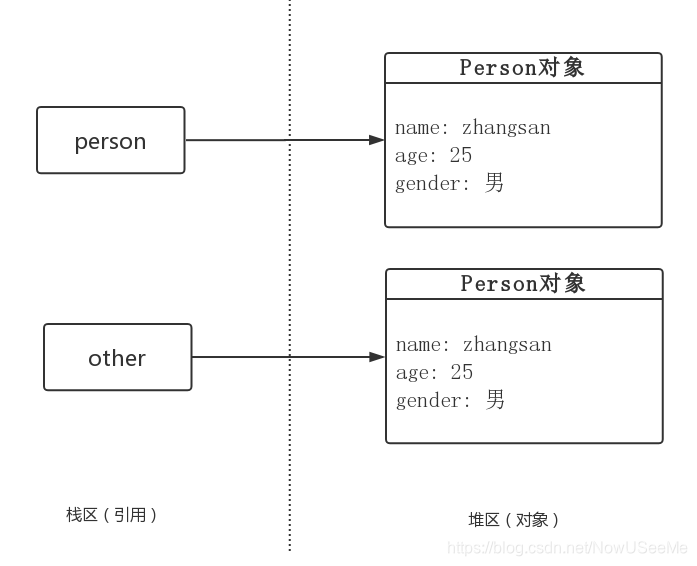
Person other = (Person)person.clone();
System.out.println(person);
System.out.println(other);
}
}
//输出结果:
com.test.clone.Person@61bbe9ba
com.test.clone.Person@610455d6
如以上输出所示,此时是是真真正正的克隆了一个对象。以上代码执行过程中, 内存中的情景如下图所示(此图还是不完整,没有细化,字段name和gender都是String对象,String对象其实是指向同一个对象,下面再深拷贝和浅拷贝再细化):
(3) 复制对象之深拷贝和浅拷贝
上面的示例代码中,Person中有三个成员变量,分别是name、age和gender。name和gender是String类型,age是int类型。
由于age是基本数据类型, 那么对它的拷贝没有什么疑议,直接将一个4字节的整数值拷贝过来就行。但是name和gender是String类型的, 它只是一个引用, 指向一个真正的String对象,那么对它的拷贝有两种方式:
①直接将源对象中的name和gender的引用值拷贝给新对象的name字段和gender字段;
②根据原Person对象中的name和gender指向的字符串对象分别创建一个新的相同的字符串对象,将这个新字符串对象的引用赋再分别给新拷贝的Person对象的name字段和gender字段。
这两种拷贝方式分别叫做 浅拷贝 和 深拷贝 。
原理如下图所示:
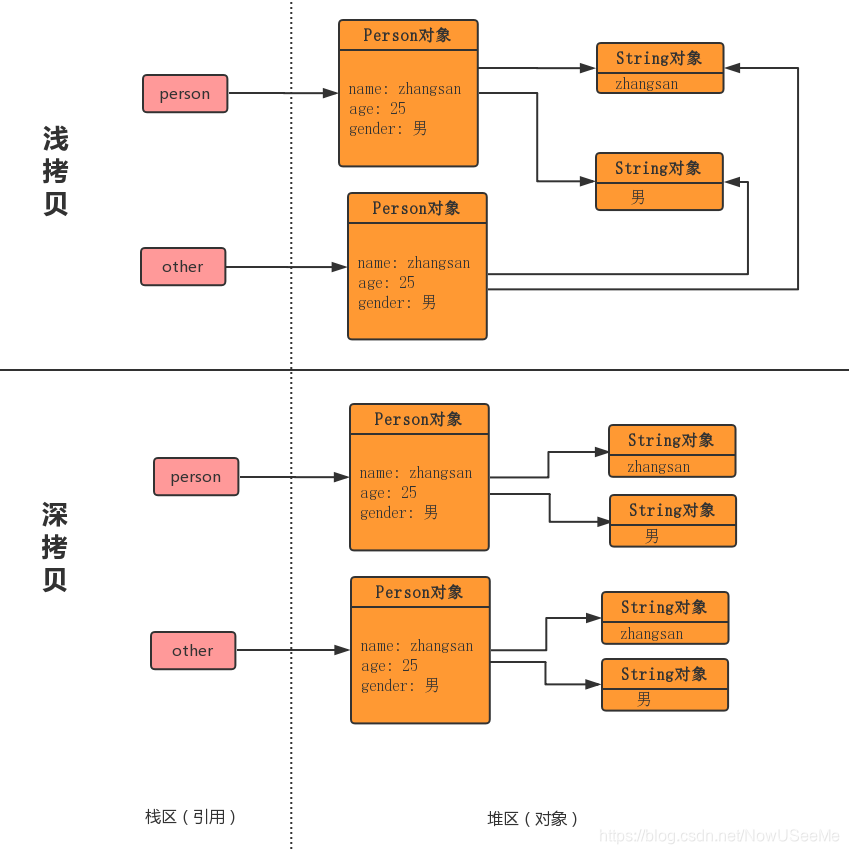
如果两个Person对象的name的地址值相同, 说明两个对象的name都指向同一个String对象, 也就是浅拷贝。 而如果两个对象的name的地址值不同, 那么就说明指向不同的String对象, 也就是在拷贝Person对象的时候, 同时拷贝了name引用的String对象, 也就是深拷贝。验证代码如下:
public static void main(String[] args) throws Exception{
Person person = new Person("zhangsan", 25, "男");
Person other = (Person)person.clone();
String result = person.getName() == other.getName() ?
"clone是浅拷贝的" : "clone是深拷贝的";
System.out.println(result);
}
打印结果:
clone是浅拷贝的
所以,clone方法执行的是浅拷贝, 在编写程序时要注意这个细节。
如果想要实现深拷贝,可以通过覆盖Object中的clone方法的方式。
(4) 如何进行深入的深clone
①为了要在clone对象时进行深拷贝,要 递归重写对象属性的对象的类的clone方法,在引用链上的每一级类都要显示的实现拷贝(重写拷贝接口)。即要实现Clonable接口,覆盖并实现clone方法,除了调用父类中的clone方法得到新的对象, 还要将该类中的引用变量也clone出来。如果只是用Object中默认的clone方法,是浅拷贝的。
以下做一个demo验证:
public class DeepCloneDemo {
static class Body implements Cloneable{
public Head head;
public Body() {}
public Body(Head head) {this.head = head;}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
static class Head {
public Head() {}
}
public static void main(String[] args) throws CloneNotSupportedException {
Body body1 = new Body(new Head());
Body body2 = (Body) body1.clone();
System.out.println("body1 == body2 : " + (body1 == body2) );
System.out.println("body1.head == body2.head : " +
(body1.head == body2.head));
}
}
在以上代码,有两个类,Body和Head两个类, 在Body类中, 组合了一个Head对象。当对Body对象进行clone时, 它组合的Head对象只进行浅拷贝。
打印结果可以验证该结论:
body1 == body2 : false
body1.head == body2.head : true
②如果要使Body对象在clone时进行深拷贝, 那么就要在Body的clone方法中,将源对象引用的Head对象也clone一份。修正后的代码如下:
public class DeepCloneDemo {
static class Body implements Cloneable{
public Head head;
public Body() {}
public Body(Head head) {this.head = head;}
@Override
protected Object clone() throws CloneNotSupportedException {
Body newBody = (Body) super.clone();
newBody.head = (Head) head.clone();
return newBody;
}
}
static class Head implements Cloneable{
public Head() {}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
public static void main(String[] args) throws CloneNotSupportedException {
Body body1 = new Body(new Head());
Body body2 = (Body) body1.clone();
System.out.println("body1 == body2 : " + (body1 == body2) );
System.out.println("body1.head == body2.head : " + (body1.head == body2.head));
}
}
输出结果为:
body1 == body2 : false
body1.head == body2.head : false
由此可见, body1和body2内的head引用指向了不同的Head对象, 也就是说在clone Body对象的同时, 也拷贝了它所引用的Head对象, 进行了深拷贝。
③通过上面的讲解我们已经知道: 如果想要深拷贝一个对象, 这个对象必须要实现Cloneable接口,实现clone方法,并且在clone方法内部,把该对象引用的其他对象也要clone一份 , 这就要求这个被引用的对象必须也要实现Cloneable接口并且实现clone方法。
那么,按照上面的结论, Body类组合了Head类, 如果Head类组合了Face类,要想深拷贝Body类,必须在Body类的clone方法中将Head类也要拷贝一份,但是在拷贝Head类时,默认执行的是浅拷贝,也就是说Head中组合的Face对象并不会被拷贝。验证代码如下:
public class DeepCloneDemo {
static class Body implements Cloneable{
public Head head;
public Body() {}
public Body(Head head) {this.head = head;}
@Override
protected Object clone() throws CloneNotSupportedException {
Body newBody = (Body) super.clone();
newBody.head = (Head) head.clone();
return newBody;
}
}
static class Head implements Cloneable{
public Face face;
public Head() {}
public Head(Face face){this.face = face;}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
static class Face{}
public static void main(String[] args) throws CloneNotSupportedException {
Body body1 = new Body(new Head());
Body body2 = (Body) body1.clone();
System.out.println("body1 == body2 : " + (body1 == body2) );
System.out.println("body1.head == body2.head : " + (body1.head == body2.head));
System.out.println("body1.head.face == body2.head .face: " + (body1.head.face == body2.head.face));
}
}
输出结果:
body1 == body2 : false
body1.head == body2.head : false
body1.head.face == body2.head .face: true
到此,可以得到如下结论:如果在拷贝一个对象时,要想让这个拷贝的对象和源对象完全彼此独立,那么在引用链上的每一级对象都要被显式的拷贝。所以创建彻底的深拷贝是非常麻烦的,尤其是在引用关系非常复杂的情况下, 或者在引用链的某一级上引用了一个第三方的对象, 而这个对象没有实现clone方法, 那么在它之后的所有引用的对象都是被共享的。
2. toString()方法
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
Object 类的 toString 方法返回一个字符串,该字符串由类名(对象是该类的一个实例)、at 标记符“@”和此象哈希码的无符号十六进制表示组成。
该方法用得比较多,一般子类都有覆盖,打印日志的时候可以看到对象信息。
示例如下:
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
public class Person implements Cloneable {
private String name;
private Integer age;
private String gender;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
@Override
public String toString(){
System.out.println();
return new StringBuilder(name)
.append(" ")
.append(age)
.append(" ")
.append(gender)
.toString();
}
public static void main(String[] args) {
Person person = new Person("zhangsan", 25, "男");
System.out.println(person);
}
}
如不重写toString()方法,打印结果会是:
com.test.clone.Person@61bbe9ba
重写之后(如上代码所示),打印结果为:
zhangsan 25 男
重写toString多用于生产打印日志,不用转json序列化,直接把类的对象丢进日志打印即可。
3. getClass()方法
public final native Class<?> getClass();
4. finalize()方法
protected void finalize() throws Throwable {}
该方法用于释放资源。因为无法确定该方法什么时候被调用,很少使用。
Java允许在类中定义一个名为finalize()的方法。它的工作原理是:一旦垃圾回收器准备好释放对象占用的存储空间,将首先调用其finalize()方法。并且在下一次垃圾回收动作发生时,才会真正回收对象占用的内存。
关于垃圾回收,有三点需要记住:
对象可能不被垃圾回收。只要程序没有濒临存储空间用完的那一刻,对象占用的空间就总也得不到释放。
垃圾回收并不等于“析构”。
垃圾回收只与内存有关。使用垃圾回收的唯一原因是为了回收程序不再使用的内存。
finalize()的用途:
无论对象是如何创建的,垃圾回收器都会负责释放对象占据的所有内存。这就将对finalize()的需求限制到一种特殊情况,即通过某种创建对象方式以外的方式为对象分配了存储空间。
不过这种情况一般发生在使用“本地方法”的情况下,本地方法是一种在Java中调用非Java代码的方式。
5. hashCode()方法
public native int hashCode();
hashCode()的作用返回一个该对象int类型的哈希码;
hashCode也是一个原生方法, 他的实现依赖于底层的JVM实现。
在Java中,hashCode方法的主要作用是为了配合基于散列的集合一起正常运行,这样的散列集合包括HashSet、HashMap以及HashTable。
(1) 为什么要用hashCode
数组是java中效率最高的数据结构,但是“最高”是有前提的。第一我们需要知道所查询数据的所在位置。第二:如果我们进行迭代查找时,数据量一定要小,对于大数据量而言一般推荐集合。
在Java集合中有两类,一类是List,一类是Set他们之间的区别就在于List集合中的元素师有序的,且可以重复,而Set集合中元素是无序不可重复的。对于List好处理,但是对于Set而言我们要如何来保证元素不重复呢? 当向集合中插入对象时,如何判别在集合中是否已经存在该对象了?(注意:Set等集合中不允许重复的元素存在)
也许大多数人都会想到调用equals方法来逐个进行比较,这个方法确实可行。但是如果集合中已经存在一万条数据或者更多的数据,如果采用equals方法去逐一比较,效率必然是一个问题。
此时hashCode方法的作用就体现出来了,当集合要添加新的对象时,先调用这个对象的hashCode方法,得到对应的hashcode值。
实际上在HashMap的具体实现中会用一个table保存已经存进去的对象的hashcode值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址,所以这里存在一个冲突解决的问题,这样一来实际调用equals方法的次数就大大降低了。说通俗一点:Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值。当我们向一个集合中添加某个元素,集合会首先调用hashCode方法,这样就可以直接定位它所存储的位置,若该处没有其他元素,则直接保存。若该处已经有元素存在,就调用equals方法来匹配这两个元素是否相同,相同则不存,不同则散列到其他位置。
所以hashCode在上面扮演的角色为寻域(寻找某个对象在集合中区域位置)。hashCode可以将集合分成若干个区域,每个对象都可以计算出他们的hash码,可以将hash码分组,每个分组对应着某个存储区域,根据一个对象的hash码就可以确定该对象所存储区域,这样就大大减少查询匹配元素的数量,提高了查询效率。
下面这段以 java.util.HashMap的#put() 方法的具体实现分析:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
put方法是用来向HashMap中添加新的元素,从put方法的具体实现可知,会先调用hashCode方法得到该元素的hashCode值,然后查看table中是否存在该hashCode值,如果存在则调用equals方法重新确定是否存在该元素,如果存在,则更新value值,否则将新的元素添加到HashMap中。从这里可以看出,hashCode方法的存在是为了减少equals方法的调用次数,从而提高程序效率。
(2) hashCode的hotspot虚拟机实现
位于hotspot/src/share/vm/runtime/synchronizer.cpp
static inline intptr_t get_next_hash(Thread * Self, oop obj) {
intptr_t value = 0 ;
if (hashCode == 0) {
// This form uses an unguarded global Park-Miller RNG,
// so it's possible for two threads to race and generate the same RNG.
// On MP system we'll have lots of RW access to a global, so the
// mechanism induces lots of coherency traffic.
value = os::random() ;
} else
if (hashCode == 1) {
// This variation has the property of being stable (idempotent)
// between STW operations. This can be useful in some of the 1-0
// synchronization schemes.
intptr_t addrBits = intptr_t(obj) >> 3 ;
value = addrBits ^ (addrBits >> 5) ^ GVars.stwRandom ;
} else
if (hashCode == 2) {
value = 1 ; // for sensitivity testing
} else
if (hashCode == 3) {
value = ++GVars.hcSequence ;
} else
if (hashCode == 4) {
value = intptr_t(obj) ;
} else {
// Marsaglia's xor-shift scheme with thread-specific state
// This is probably the best overall implementation -- we'll
// likely make this the default in future releases.
unsigned t = Self->_hashStateX ;
t ^= (t << 11) ;
Self->_hashStateX = Self->_hashStateY ;
Self->_hashStateY = Self->_hashStateZ ;
Self->_hashStateZ = Self->_hashStateW ;
unsigned v = Self->_hashStateW ;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8)) ;
Self->_hashStateW = v ;
value = v ;
}
value &= markOopDesc::hash_mask;
if (value == 0) value = 0xBAD ;
assert (value != markOopDesc::no_hash, "invariant") ;
TEVENT (hashCode: GENERATE) ;
return value;
}
hashcode值判断两个对象是否相等?
可以直接根据hashcode值判断两个对象是否相等吗?不同的对象可能会生成相同的hashcode值。虽然不能根据hashcode值判断两个对象是否相等,但是可以直接根据hashcode值判断两个对象不等,如果两个对象的hashcode值不等,则必定是两个不同的对象。如果要判断两个对象是否真正相等,必须通过equals方法。
也就是说对于两个对象,如果调用equals方法得到的结果为true,则两个对象的hashcode值必定相等;
如果equals方法得到的结果为false,则两个对象的hashcode值不一定不同;
如果两个对象的hashcode值不等,则equals方法得到的结果必定为false;
如果两个对象的hashcode值相等,则equals方法得到的结果未知。
hashCode重写需遵循三点原则:
hashCode没有声明成final, 证明可以被子类重写, 但是重写时需遵从以下三点约定:
在java程序执行过程中,在一个对象没有被改变的前提下,无论这个对象被调用多少次,hashCode方法都会返回相同的int值。这个int值可在不同的程序中不同。
如果两个对象根据equals(Object o)方法是相等的,则调用这两个对象中任一对象的hashCode方法必须产生相同的整数结果。
如果两个对象根据equals(Object o)方法是不相等的,则调用这两个对象中任一个对象的hashCode方法,不要求产生不同的整数结果。但如果能不同,则可能提高散列表的性能。
6. equals()方法
public boolean equals(Object obj) {
return (this == obj);
}
对于equals,我们必须遵循如下规则:
对称性:如果x.equals(y)返回是“true”,那么y.equals(x)也应该返回是“true”。
反射性:x.equals(x)必须返回是“true”。
类推性:如果x.equals(y)返回是“true”,而且y.equals(z)返回是“true”,那么z.equals(x)也应该返回是“true”。
一致性:如果x.equals(y)返回是“true”,只要x和y内容一直不变,不管你重复x.equals(y)多少次,返回都是“true”。
任何情况下,x.equals(null),永远返回是“false”;x.equals(和x不同类型的对象)永远返回是“false”。
7. wait()、notify()、notfiyAll()方法
(1) wait()方法
wait()方法为阻塞等待,提供阻塞功能呢,分为超时和永久阻塞。实际上,底层只提供一个JNI方法:
// 这个是底层提供的JNI方法,参数为超时时间的阻塞等待,响应中断
// 其他两个方法都是调用这个底层方法
public final native void wait(long timeout) throws InterruptedException;
// timeout为0 表示永久阻塞,响应中断
public final void wait() throws InterruptedException {
wait(0L);
}
// 带超时的阻塞,超时时间分两段:毫秒和纳秒,实际上纳秒大于0直接毫秒加1,响应中断
public final void wait(long timeout, int nanos) throws InterruptedException {
if (timeout < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
if (nanos > 0) {
timeout++;
}
wait(timeout);
}
由以上Object类源码可知,只有一个wait(long timeoutMillis)方法是JNI接口,其他两个方法相当于:
wait()等价于wait(0L)。
wait(long timeoutMillis, int nanos)在参数合法的情况下等价于 wait(timeoutMillis + 1L)。
完整描述下wait(long timeoutMillis, int nanos)这个方法的具体用法以及原理:
当前线程调用wait方法会阻塞等待直到被唤醒。唤醒的情况一般有三种:notify(All)被调用、线程被中断或者在指定了超时阻塞的情况下超过了指定的阻塞时间。
当前线程必须获取此对象的监视器锁(monitor lock),也就是调用阻塞等待方法之前一个线程必须成为此对象的监视器锁的拥有者。
调用了wait()方法之后,当前线程会把自身放到当前对象的等待集合(wait-set),然后释放所有在此对象上的同步声明(then to relinquish any nd all synchronization claims on this object),谨记只有当前对象上的同步声明会被释放,当前线程在其他对象上的同步锁只有在调用其wait()方法之后才会释放。
Warning:线程被唤醒之后(notify()或者中断)就会从等待集合(wait-set)中移除并且重新允许被线程调度器调度。通常情况下,这个被唤醒的线程会与其他线程竞争对象上的同步权(锁),一旦线程重新控制了对象(regained control of the object),它对对象的所有同步声明都恢复到以前的状态,即恢复到调用wait()方法时(其实准确来说,是调用wait()方法前)的状态。
如果任意线程在它调用了wait()之前,或者调用过wait()方法之后处于阻塞等待状态,一旦线程调用了Thread#interrupt(),线程就会中断并且抛出InterruptedException异常,线程的中断状态会被清除。InterruptedException异常会延迟到在第4点提到”它对对象的所有同步声明都恢复到以前的状态”的时候抛出。
简单用伪代码描述下上述的过程:
final Object lock = new Object();
// 竞争获取对象监视器锁 对象lock的ObjectMonitor
synchronized(lock){
step 1. 线程进入同步代码块,意味着获取对象监视器锁成功
while(!condition){
step 2. 线程调用wait()进行阻塞等待 lock.wait();
break;
}
step 3. 线程从wait()的阻塞等待中被唤醒,恢复到第1步之后的同步状态
step 4. .继续执行后面的代码,直到离开同步代码块
}
注意:
一个线程必须成为此对象的监视器锁的拥有者才能正常调用wait()系列方法,也就是wait()系列方法必须在同步代码块(synchronized代码块)中调用,否则会抛出IllegalMonitorStateException异常。
(2) notify()方法
public final native void notify();
唤醒一个阻塞等待在此对象监视器上的线程,(如果存在多个阻塞线程)至于选择哪一个线程进行唤醒是任意的,取决于具体的现实,一个线程通过调用wait()方法才能阻塞在对象监视器上。
被唤醒的线程并不会马上继续执行,直到当前线程(也就是当前调用了notify()方法的线程)释放对象上的锁。被唤醒的线程会与其他线程竞争在对象上进行同步(换言之只有获得对象的同步控制权才能继续执行),在成为下一个锁定此对象的线程时,被唤醒的线程没有可靠的特权或劣势。
此方法只有在一个线程获取了此对象监视器的所有权(the owner)的时候才能调用,具体就是:同步方法中、同步代码块中或者静态同步方法中。否则,会抛出IllegalMonitorStateException异常。
(3) notifyAll()方法
public final native void notify();
唤醒所有阻塞等待在此对象监视器上的线程,一个线程通过调用wait()方法才能阻塞在对象监视器上。
其余与notify()方法类似。
(4) wait 和 synchronized
一般来说,wait()方法是需要和synchronized一起使用的。说白了,wait()方法需要依赖synchronized获取对象锁,不然就会抛出 IllegalMonitorStateException异常。
synchronized关键字的用法:
普通同步方法,同步或者说锁定的是当前实例对象。
静态同步方法,同步或者说锁定的是当前实例对象的Class对象。
同步代码块,同步或者说锁定的是括号里面的实例对象。
对于普通同步方法或者静态同步方法而言,synchronized方法会被翻译成普通的方法调用和返回指令,如:invokevirtual等等,在JVM字节码层面并没有任何特别的指令来实现被synchronized修饰的方法,而是在Class文件的方法表中将该方法的access_flags字段中的synchronized标志位置1,表示该方法是同步方法并使用调用该方法的对象或该方法所属的Class在JVM的内部对象表示Klass做为锁对象。
对于同步代码块而言,synchronized关键字抽象到字节码层面就是同步代码块中的字节码执行在monitorenter和monitorexit指令之间:
代码:
synchronized(xxxx){
...code block 同步代码块
}
↓↓↓↓↓↓↓↓↓↓
monitorenter;
... code block 同步代码块 (字节码bytecode)
monitorexit;
JVM需要保证每一个monitorenter都有一个monitorexit与之相对应。任何对象都有一个monitor(实际上是ObjectMonitor)与之相关联,当且一个monitor被持有之后,它将处于锁定状态。线程执行到monitorenter指令时,将会尝试获取对象所对应的monitor所有权,即尝试获取对象的锁。
(5) synchronized、wait和notify(All)的内部运行流程
在线程进入synchronized方法或者代码块,相当于获取监视器锁成功,如果此时成功调用wait()系列方法,那么它会立即释放监视器锁,并且添加到等待集合(Wait Set)中进行阻塞等待。
由于已经有线程释放了监视器锁,那么在另一个线程进入synchronized方法或者代码块之后,它可以调用notify(All)方法唤醒等待集合中正在阻塞的线程,但是这个唤醒操作并不是调用notify(All)方法后立即生效,而是在该线程退出synchronized方法或者代码块之后才生效。
从wait()方法阻塞过程中被唤醒的线程会竞争监视器目标对象的控制权,一旦重新控制了对象,那么线程的同步状态就会恢复到步入synchronized方法或者代码块时候的状态(也就是成功获取到对象监视器锁时候的状态),这个时候线程才能够继续执行。
举例demo:
package com.test.object;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
/**
* @author nowuseeme
*/
public class WaitDemo {
private static final Object lock = new Object();
private static final DateTimeFormatter F =
DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss.SSS");
private static class WaitRunnable implements Runnable {
@Override
public void run() {
synchronized (lock) {
System.out.println(String.format(
"[%s]-线程[%s]获取锁成功,准备执行wait方法",
F.format(LocalDateTime.now()),
Thread.currentThread().getName()));
while (true) {
try {
lock.wait();
} catch (InterruptedException e) {
//ignore
}
System.out.println(String.format(
"[%s]-线程[%s]从wait中唤醒,准备exit",
F.format(LocalDateTime.now()),
Thread.currentThread().getName()));
try {
Thread.sleep(500);
} catch (InterruptedException e) {
//ignore
}
break;
}
}
}
}
private static class NotifyRunnable implements Runnable {
@Override
public void run() {
synchronized (lock) {
System.out.println(String.format(
"[%s]-线程[%s]获取锁成功,准备执行notifyAll方法",
F.format(LocalDateTime.now()),
Thread.currentThread().getName()));
lock.notifyAll();
System.out.println(String.format(
"[%s]-线程[%s]先休眠3000ms",
F.format(LocalDateTime.now()),
Thread.currentThread().getName()));
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
//ignore
}
System.out.println(String.format(
"[%s]-线程[%s]准备exit",
F.format(LocalDateTime.now()),
Thread.currentThread().getName()));
}
}
}
public static void main(String[] args) throws InterruptedException {
new Thread(new WaitRunnable(), "WaitThread-1").start();
new Thread(new WaitRunnable(), "WaitThread-2").start();
Thread.sleep(50);
new Thread(new NotifyRunnable(), "NotifyThread").start();
Thread.sleep(Integer.MAX_VALUE);
}
}
运行结果:
[2019-07-17 01:40:52.202]-线程[WaitThread-1]获取锁成功,准备执行wait方法
[2019-07-17 01:40:52.220]-线程[WaitThread-2]获取锁成功,准备执行wait方法
//这一步执行完说明WaitThread已经释放了锁
[2019-07-17 01:40:52.227]-线程[NotifyThread]获取锁成功,准备执行notifyAll方法
[2019-07-17 01:40:52.227]-线程[NotifyThread]先休眠3000ms
//这一步后NotifyThread离开同步代码块
[2019-07-17 01:40:55.227]-线程[NotifyThread]准备exit
//这一步WaitThread-2解除阻塞
[2019-07-17 01:40:55.227]-线程[WaitThread-2]从wait中唤醒,准备exit
//这一步WaitThread-1解除阻塞,
//注意发生时间在WaitThread-2解除阻塞500ms之后,符合我们前面提到的
[2019-07-17 01:40:55.727]-线程[WaitThread-1]从wait中唤醒,准备exit
结合wait()和notify()可以简单总结出一个同步代码块的伪代码如下:
final Object lock = new Object();
// 等待
synchronized(lock){
1、线程进入同步代码块,意味着获取对象监视器锁成功
while(!condition){
lock.wait(); 2.线程调用wait()进行阻塞等待,释放对象监视器锁
break;
}
3.线程从wait()的阻塞等待中被唤醒,尝试恢复第1步之后的同步状态,并不会马上生效,直到notify被调用并且调用notify方法的线程已经释放锁,同时当前线程需要竞争成功
4.继续执行后面的代码,直到离开同步代码块
}
// 唤醒
synchronized(lock){
1、线程进入同步代码块,意味着获取对象监视器锁成功
lock.notify(); 2.唤醒其中一个在对象监视器上等待的线程
3.准备推出同步代码块释放锁,只有释放锁之后第2步才会生效
(6) 图解Object提供的阻塞和唤醒机制
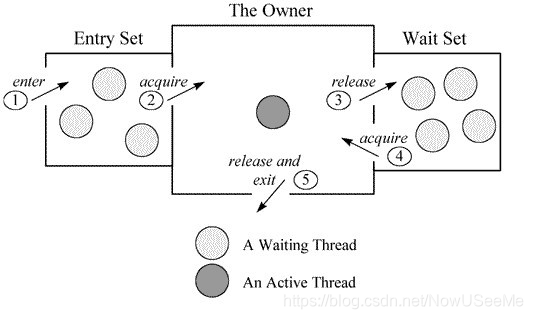
Entry Set(实际上是ObjectMonitor中的_EntryList属性):存放等待锁并且处于阻塞状态的线程。
Wait Set(实际上是ObjectMonitor中的_WaitSet属性):存放处于等待阻塞状态的线程。
The Owner(实际上是ObjectMonitor中的_owner属性):指向获得对象监视器的线程,在同一个时刻只能有一个线程被The Owner持有,通俗来看,它就是监视器的控制权。
五、参考
深入理解多线程(四)—— Moniter的实现原理:https://www.hollischuang.com/archives/2030
blog.youkuaiyun.com/zhangjg_blog/article/details/18369201/
https://docs.oracle.com/javase/specs/jls/se7/html/jls-9.html#jls-9.6.3.4

















 553
553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









