




 本文详细介绍了HDFS(Hadoop Distributed File System)的优缺点、组成架构、文件块大小、Shell操作、Java操作、数据流、NameNode和SecondaryNameNode的工作机制、DataNode的特点以及HDFS的高可用特性,包括故障转移和数据完整性保障。此外,还涵盖了HDFS 2.x的新特性,如集群间数据拷贝、小文件存档、回收站和快照功能。
本文详细介绍了HDFS(Hadoop Distributed File System)的优缺点、组成架构、文件块大小、Shell操作、Java操作、数据流、NameNode和SecondaryNameNode的工作机制、DataNode的特点以及HDFS的高可用特性,包括故障转移和数据完整性保障。此外,还涵盖了HDFS 2.x的新特性,如集群间数据拷贝、小文件存档、回收站和快照功能。
HDFS
HDFS是一个分布式文件系统,适合一次写入多次读出的场景。
HDFS的优缺点
优点
- 高容错性:数据自动保存多个副本,默认是3,且在某个副本丢失后可以自动恢复
- 适合处理大数据:数据规模大,文件规模多
- 可以构建在廉价机器上,通过多副本机制,提高可靠性。
缺点
- 不适合低延时数据访问,比如毫秒级别的存储数据,是做不到的。
- 无法高效的对对大量小文件进行处理,所以可以采用特定的文件格式处理小文件
- 因为大量的小文件会占用大量的NameNode空间来存放元数据
- 小文件的存储和寻址时间会超过读取时间,违反了HDFS的设计目标。
- 不支持并发写入,文件随即修改
- 一个文件只能有一个写。
- 仅支持append,不支持文件的随即修改 。
HDFS 组成架构
NN:
- 管理HDFS的名称空间
- 配置副本策略
- 管理数据块映射信息
- 处理客户端读写请求
DN:
- 存储实际的数据块
- 执行数据块的读写操作
Client:
- 文件切分。文件上传刀HDFS的时候,Client将文件切成一个一个的Block,然后进行上传。
- 与NN交互,获取文件的位置信息。
- 与DN交互,读取或写入数据
- Client提供一些命令来管理HDFS,比如NN格式化
- 对HDFS进行增删改查
SNN:
- 辅助NN,分担其任务量,比如定期合并Fsimage和Edit并推送给NN
- 在紧急情况下,辅助NN恢复数据
HDFS文件块大小
- HDFS在物理上是分块存储,快的大小可以通过dfs.blockSize更改。
- 默认Hadoop2.X每块大小是128M,1.X是64MB,单机是32M。
- 寻址时间大约为传输时间的1%最好,我们默认寻址时间是10ms,传输速率是100MB/s,因此默认块大小是128mb。
- 块太小会影响到寻址时间。
- 块太大会影响到处理时间,让处理时间变慢。
HDFS的Shell操作
- -ls: 显示目录信息
- -mkdir:在HDFS上创建目录
- -moveFromLocal:从本地剪切粘贴到HDFS
- -appendToFile:追加一个文件到已经存在的文件末尾
- -cat:显示文件内容
- -chgrp 、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
- -copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
- -copyToLocal:从HDFS拷贝到本地
- -cp :从HDFS的一个路径拷贝到HDFS的另一个路径
- -mv:在HDFS目录中移动文件
- -get:等同于copyToLocal,就是从HDFS下载文件到本地
- -getmerge:合并下载多个文件,比如HDFS的目录 /user/atguigu/test下有多个文件:log.1, log.2,log.3,…
- -put:等同于copyFromLocal
- -tail:显示一个文件的末尾
- -rm:删除文件或文件夹
- -rmdir:删除空目录
- -du:统计文件夹的大小信息
- -setrep:设置HDFS中文件的副本数量
通过Java操作Hadoop
public class HdfsClient{
@Test
public void testMkdirs() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
// 配置在集群上运行
// configuration.set("fs.defaultFS", "hdfs://hadoop102:9000");
// FileSystem fs = FileSystem.get(configuration);
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "atguigu");
// 2 创建目录
fs.mkdirs(new Path("/1108/daxian/banzhang"));
// 3 关闭资源
fs.close();
}
}
客户端去操作HDFS时,是有一个用户身份的。默认情况下,HDFS客户端API会从JVM中获取一个参数来作为自己的用户身份:-DHADOOP_USER_NAME=win10,win10为用户名称。
HDFS的数据流
HDFS的写操作:
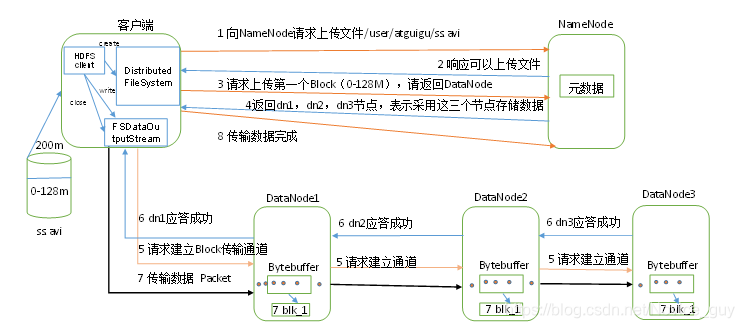
- 1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
- 2)NameNode返回是否可以上传。
- 3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
- 4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
- 5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
- 6)dn1、dn2、dn3逐级应答客户端。
- 7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet(默认64KB)会放入一个应答队列等待应答。
- 8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
HDFS的读操作
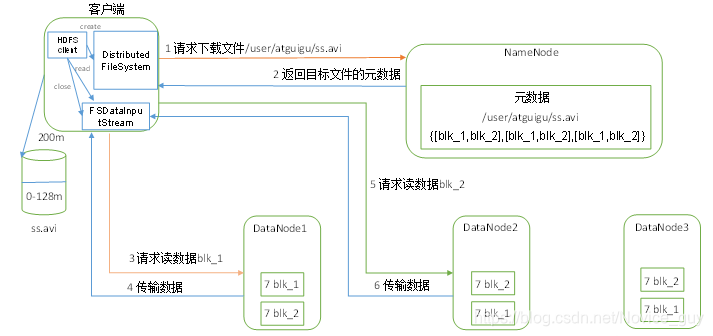
- 1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找- 到文件块所在的DataNode地址。
- 2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
- 3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
- 4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
网络拓扑-节点距离计算
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。
- 同一节点上的进程:distance=0
- 同一机架上的不同节点:distance = 2
- 同一数据中心里的不同机架:distance = 4
- 不同数据中心:distance=6
副本节点选择
- 第一个副本在Client所在的节点上
- 第二个副本在相同机架上其他节点
- 第三个位于不同机架随即节点
NameNode和SecondaryNameNode
NN和2NN工作机制
- NN元数据存储在内存中,但是为了防止断电丢失数据,因此需要落盘。
- 产生在磁盘中备份元数据的FsImage。
- 当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,如果断电就会产生数据丢失。
- 因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。
- 一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
- 因为如果合并的任务交给NN去处理,会导致NN的工作负荷过大,因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
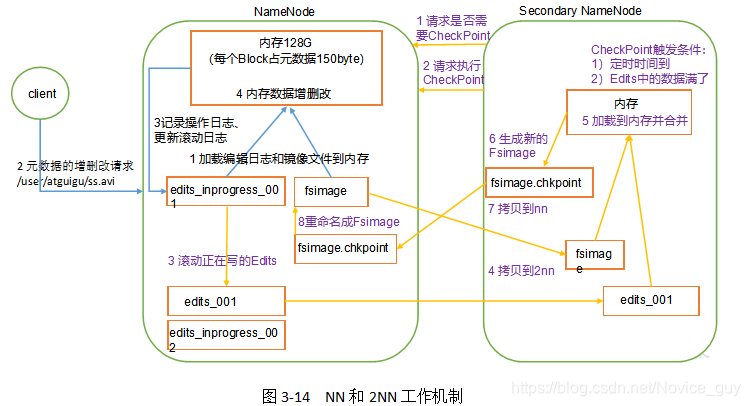
1. 第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对数据进行增删改。
2. 第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
NN和2NN工作机制详解:
-
Fsimage:NameNode内存中元数据序列化后形成的文件。
-
Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。 -
由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
-
SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中。
Fsimage和Edits解析
- Fsimage文件:HDFS文件系统元数据的一个永久检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息。
- Edits文件:存在HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
- seen-txid文件保存是一个数字,就是最后一个edits_的数字。
- 每次NameNode启动的时候都会将Fsimage文件读入内存,加载Fsimage中的内容到内存中,保证内存中的元数据是最新的,可以理解成NN启动时自动整合了FSimage和edits。
oiv查看Fsimage文件
- hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
oev查看Edits文件
- hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
CheckPoint时间设置
- 通常情况下,SecondaryNameNode每隔一小时执行一次。
- 一分钟检查一次操作次数,3当操作次数达到1百万时,SecondaryNameNode执行一次。
NameNode故障处理
- 方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
- 1.kill -9 NameNode进程
- 2.删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
- 3.拷贝SecondaryNameNode中数据到原NameNode存储数据目录
- 4.重新启动NameNode
- 方法二:使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
- 1.修改hdfs-site.xml中的"dfs.namenode.checkpoint.period"
- 2.kill -9 NameNode进程
- 3.删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
- 4.如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件
- 5.导入检查点数据(等待一会ctrl+c结束掉)
- 6.启动NameNode
集群安全模式
- NameNode刚启动时候,因为要整和Fsimage和edits,因此会进入一段只读阶段。
- DataNode在安全阶段想NameNode发送存储在当前节点上数据的映射。
- 只有当最小副本数达到99%30秒后,就会退出安全模式。
NameNode多目录配置
- 在hdfs-site.xml文件中增加如下内容
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value>
</property>
DataNode
DataNode工作机制
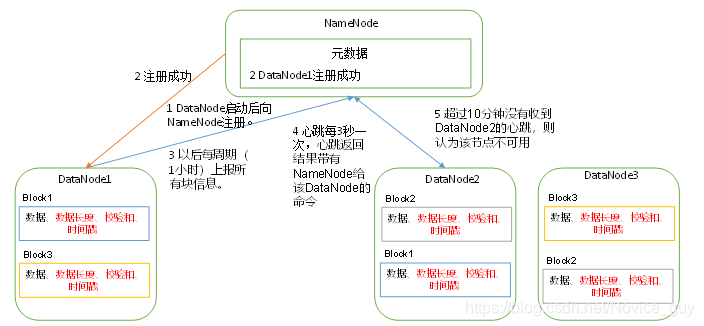
- 1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳.
- 2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
- 3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
- 4)集群运行中可以安全加入和退出一些机器。
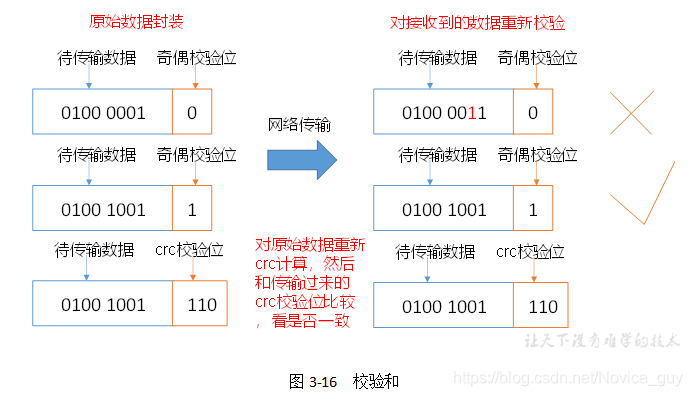
数据完整性
DataNode节点保证数据完整性的方法:
- 1)当DataNode读取Block的时候,它会计算CheckSum。
- 2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
- 3)Client读取其他DataNode上的Block。
- 4)DataNode在其文件创建后周期验证CheckSum,如图3-16所示。
服役新数据节点
在原有集群基础上动态添加新的数据节点:
- 直接启动DataNode,即可关联到集群
- 如果数据不均衡,可以用命令实现集群的再平衡
atguigu@hadoop102 sbin]$ ./start-balancer.sh
starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-atguigu-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
退役旧数据节点
添加白名单
- 1.在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts文件
- 2.添加主机名称
- 3.在NameNode的hdfs-site.xml配置文件中增加dfs.hosts属性
- 4.配置文件分发,刷新NameNode
- 5.更新ResourceManager节点
- 6.如果数据不均衡,可以用命令实现集群的再平衡
黑名单退役
- 1.在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts.exclude文件
- 2.添加要退役的节点主机名称
- 3.在NameNode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
- 4.刷新NameNode、刷新ResourceManager
- 5.如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役,如图3-18所示
- 6.如果数据不均衡,可以用命令实现集群的再平衡
HDFS 2.X新特性
集群间数据拷贝
1.scp实现两个远程主机之间的文件复制
scp -r hello.txt root@hadoop103:/user/atguigu/hello.txt // 推 push
scp -r root@hadoop103:/user/atguigu/hello.txt hello.txt // 拉 pull
scp -r root@hadoop103:/user/atguigu/hello.txt root@hadoop104:/user/
//是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
2.采用distcp命令实现两个Hadoop集群之间的递归数据复制
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop distcp
hdfs://haoop102:9000/user/atguigu/hello.txt hdfs://hadoop103:9000/user/atguigu/hello.txt
小文件存档
- 每个文件按块存储,本省并不会影响磁盘占有量,但是因为每个小文件都需要在NN中存储元数据,这样会大量占用NN的内存,因此效率十分低下。
- HDFS存档文件或HAR文件可以解决这个问题,他将文件存入HDFS块,在减少NN内存使用的同时,允许对文件进行透明的访问,也就是说对内是一个一个小文件,对HDFS来讲是一个整体文件,可以理解成压缩包那种存储感觉,减少了NN的内存使用。
归档方法:
- 归档文件
bin/hadoop archive -archiveName input.har –p /user/atguigu/input /user/atguigu/output
- 查看归档
hadoop fs -lsr /user/atguigu/output/input.har
hadoop fs -lsr har:///user/atguigu/output/input.har
- 解归档文件
hadoop fs -cp har:/// user/atguigu/output/input.har/* /user/atguigu
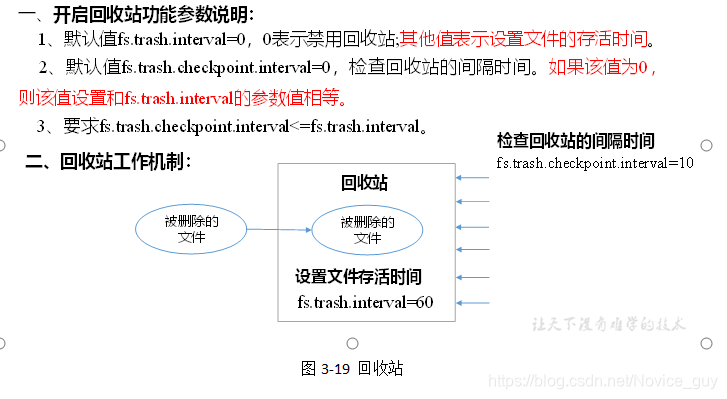
回收站
- 可以通过设置参数开启
快照
- 快照相当于对目录进行一个备份,并不会复制所有文件,而是记录文件变化。

HDFS HA高可用
HA概述
- 1)所谓HA(High Available),即高可用(7*24小时不中断服务)。
- 2)实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
- 3)Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。
- 4)NameNode主要在以下两个方面影响HDFS集群
- NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启
- NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
- HDFS HA功能通过配置Active/Standby两个NameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
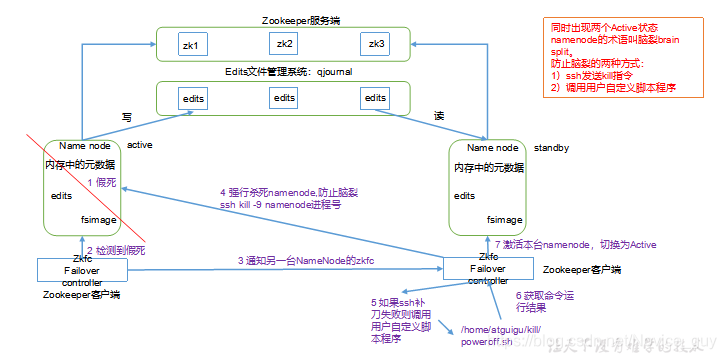
故障转移机制
- 1)故障检测:集群中的每个NameNode在ZooKeeper中维护了一个持久会话,如果机器崩溃,ZooKeeper中的会话将终止,ZooKeeper通知另一个NameNode需要触发故障转移。
- 2)现役NameNode选择:ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排外锁以表明它应该成为现役NameNode。
ZKFC是自动故障转移中的另一个新组件,是ZooKeeper的客户端,也监视和管理NameNode的状态。每个运行NameNode的主机也运行了一个ZKFC进程,ZKFC负责:- 1)健康监测:ZKFC使用一个健康检查命令定期地ping与之在相同主机的NameNode,只要该NameNode及时地回复健康状态,ZKFC认为该节点是健康的。如果该节点崩溃,冻结或进入不健康状态,健康监测器标识该节点为非健康的。
- 2)ZooKeeper会话管理:当本地NameNode是健康的,ZKFC保持一个在ZooKeeper中打开的会话。如果本地NameNode处于active状态,ZKFC也保持一个特殊的znode锁,该锁使用了ZooKeeper对短暂节点的支持,如果会话终止,锁节点将自动删除。
- 3)基于ZooKeeper的选择:如果本地NameNode是健康的,且ZKFC发现没有其它的节点当前持有znode锁,它将为自己获取该锁。如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地NameNode为Active。故障转移进程与前面描述的手动故障转移相似,首先如果必要保护之前的现役NameNode,然后本地NameNode转换为Active状态。
HDFS Federation架构设计
NameNode架构的局限性:
- (1)Namespace(命名空间)的限制:由于NameNode在内存中存储所有的元数据(metadata),因此单个NameNode所能存储的对象(文件+块)数目受到NameNode所在JVM的heap size的限制。50G的heap能够存储20亿(200million)个对象,这20亿个对象支持4000个DataNode,12PB的存储(假设文件平均大小为40MB)。随着数据的飞速增长,存储的需求也随之增长。单个DataNode从4T增长到36T,集群的尺寸增长到8000个DataNode。存储的需求从12PB增长到大于100PB。
- (2)隔离问题:由于HDFS仅有一个NameNode,无法隔离各个程序,因此HDFS上的一个实验程序就很有可能影响整个HDFS上运行的程序。
- (3)性能的瓶颈:由于是单个NameNode的HDFS架构,因此整个HDFS文件系统的吞吐量受限于单个NameNode的吞吐量。


















 1993
1993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









