






kafka消费模式
Kafka的消费模式主要有两种:一种是一对一的消费,也即点对点的通信,即一个发送一个接收。第二种为一对多的消费(发布/订阅模式),即一个消息发送到消息队列,消费者根据消息队列的订阅拉取消息消费。
点对点模式
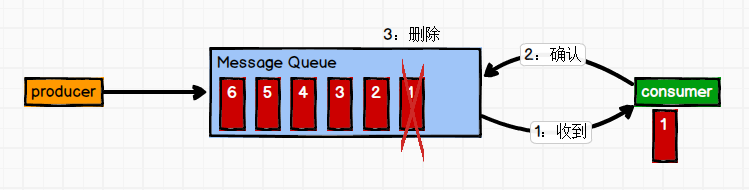
消息生产者发布消息到Queue队列中,通知消费者从队列中拉取消息进行消费。消息被消费之后则删除,Queue支持多个消费者,但对于一条消息而言,只有一个消费者可以消费,即一条消息只能被一个消费者消费。
发布/订阅模式
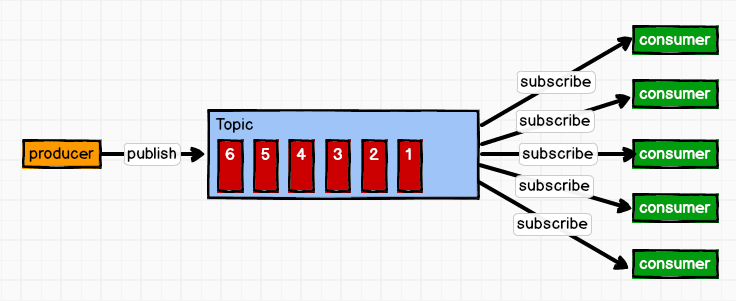
发布/订阅模式,即利用Topic存储消息,消息生产者将消息发布到Topic中,同时有多个消费者订阅此topic,消费者可以从中消费消息,注意发布到Topic中的消息会被多个消费者消费,消费者消费数据之后,数据不会被清除,Kafka会默认保留一段时间,然后再删除。
注意:同一消费者组内的消费者共享主题分区,每个分区仅被组内一个消费者消费,实现消息的负载均衡。
kafka基础架构
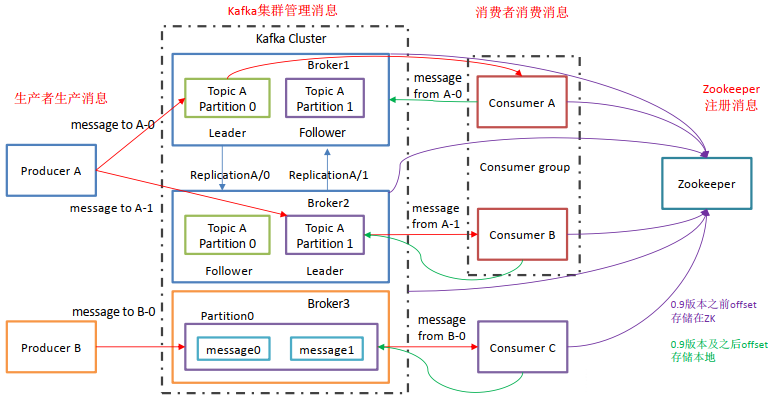
Kafka像其他Mq一样,也有自己的基础架构,主要存在生产者Producer、Kafka集群Broker、消费者Consumer、注册消息Zookeeper.
- Producer:消息生产者,向Kafka中发布消息的角色。
- Consumer:消息消费者,即从Kafka中拉取消息消费的客户端。
- Consumer Group:消费者组,消费者组则是一组中存在多个消费者,消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费
- Broker:经纪人,一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic。
- Topic:主题,可以理解为一个队列,生产者和消费者都是面向一个Topic
- Partition:分区,为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)
- Replica:副本Replication,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower
- Leader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
- Follower:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。
上述一个Topic会产生多个分区Partition,分区中分为Leader和Follower,消息一般发送到Leader,Follower通过数据的同步与Leader保持同步,消费的话也是在Leader中发生消费,如果多个消费者,则分别消费Leader和各个Follower中的消息,当Leader发生故障的时候,某个Follower会成为主节点,此时会对齐消息的偏移量。
个人理解:kafka集群,由多个Broker组成,一个Broker里面可以容纳多个Topic,每个Topic由多个partition组成,多个partition分散存储在多个Broker中,为了实现高可用,每个partition可以存在多个副本(一个Leader和多个Follower),消息生产者发送的消息最终都是先发送在指定topic下的某个Leader partition中,Follower partition会实时的从Leader中同步数据,Leader发生故障的时候,某个Follower会成为新的Leader。
真实项目使用
kafka集群由3个broker组成。可以看到,该topic有4个partition,并且partition的副本数量为2,则总共有8个partition,4个Leader和4个Follower。
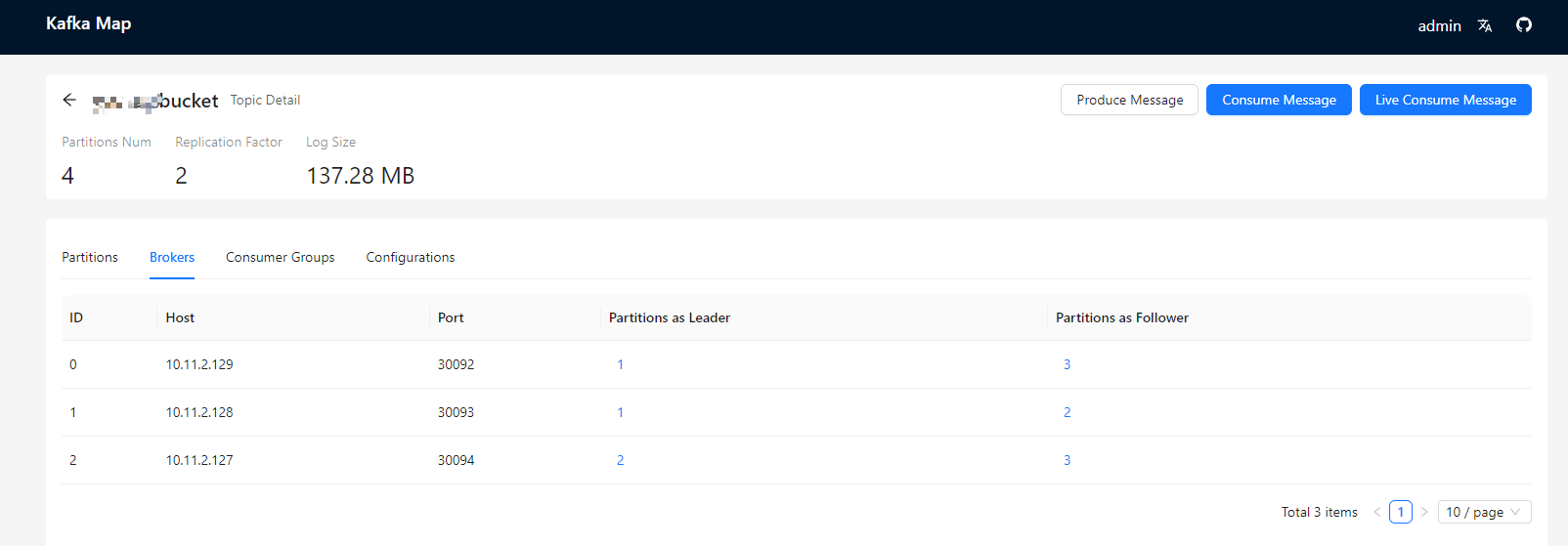
并且在主机id为0和1上面,均存储了一个Leader partition,而主机id为3上面存储了2个Leader partition。
在我们项目中,某个服务监听了该topic的消息,并且该服务已配置了自己的消费者组id。
在部署该服务的时候,给这个服务配置了6个实例,即在这个消费者组id下,共有6个消费者,在接收kafka消息时,同一消费者组下只会有一个消费者接收到消息。

















 1043
1043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









