




 本文介绍了LSTM的工作原理,以及如何在Decoder类中结合Attention机制进行文本生成。Decoder的初始化包括Embedding、LSTM和Attention层,forward函数中使用矩阵乘法和连接操作。通过softmax归一化得到每个单词的概率,使用beam-search方法生成结果。
本文介绍了LSTM的工作原理,以及如何在Decoder类中结合Attention机制进行文本生成。Decoder的初始化包括Embedding、LSTM和Attention层,forward函数中使用矩阵乘法和连接操作。通过softmax归一化得到每个单词的概率,使用beam-search方法生成结果。
2021SC@SDUSC
在论文中,Decoder采用的是LSTM编码模型,故首先对LSTM进行学习。
一、LSTM
LSTM:全称Long Short-Term Memory,是RNN(Recurrent Neural Network)的一种。LSTM由于其设计的特点,非常适合用于对时序数据的建模,如文本数据。
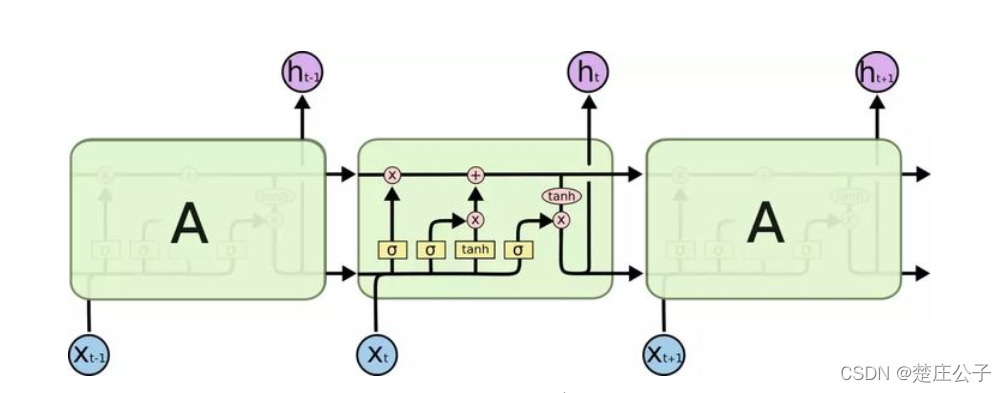
整体结构如图:
- 首先计算遗忘门,选择要遗忘的信息。
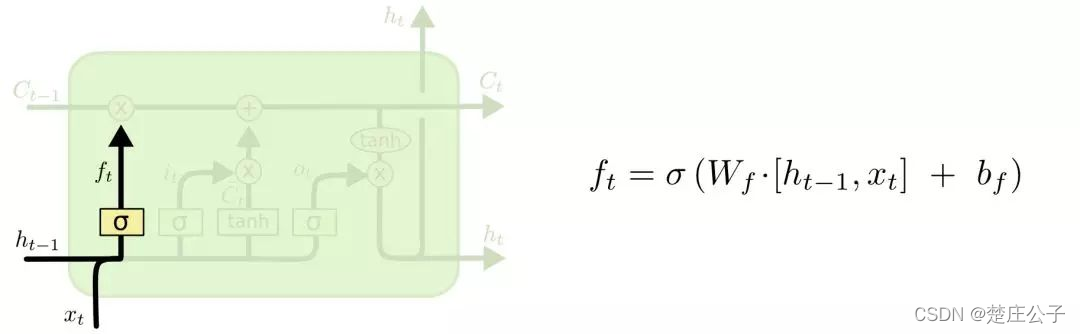
输入:前一时刻的隐层状态ht-1,当前时刻的输入词Xt
输出:遗忘门的值ft
- 计算记忆门,选择要记忆的信息。
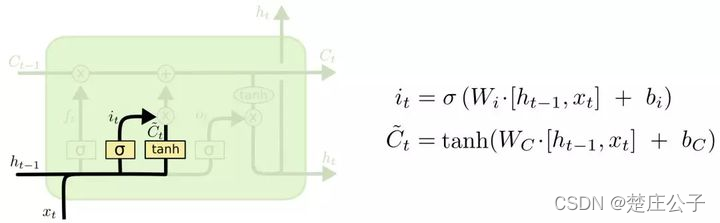
输入:前一时刻的隐层状态ht-1,当前时刻的输入词Xt
输出:记忆门的值it,临时细胞状态Ct
- 计算输出门和当前时刻隐层状态
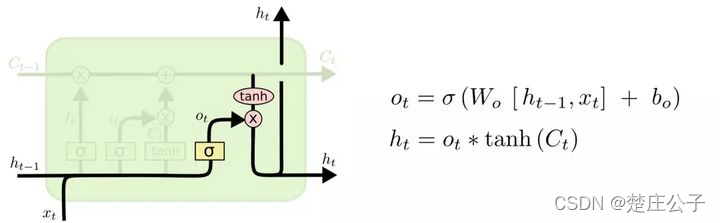
输入:前一时刻的隐层状态ht-1,当前时刻的输入词Xt,当前时刻细胞状态Ct
输出:输出门的值ot,隐层状态ht
- 最终,得到与句子长度相同的隐层状态序列{h0,h1…,hn-1}
二、Decoder类
__ init() __函数
使用继承nn.Module类的方式,实现共享参数。
首先定义__init__函数,在其内定义层。
#以继承nn.Module类的方式实现网络结构的自定义
class Decoder(nn.Module):
#在__init__函数中定义层
def __init__(self, output_dim=50004, emb_dim=200, hid_dim=256, dropout=0.5, name='emb_kp20k2.npy'):
#继承nn.Module类的__init__()方法
super().__init__()
#指定每个词输出的向量维度
self.hid_dim = hid_dim
#下一层的单元的个数
self.output_dim = output_dim
#emb_dim,嵌入后的向量大小
self.embedding = nn.Embedding(output_dim, emb_dim)
#attention layer,使用slef.atten_layer()获得用于后续计算权重的向量
self.attention_layer = nn.Sequential(
nn.Linear(self.hid_dim, self.hid_dim),
nn.ReLU(inplace=True))
#采用LSTM返回每个训练的cell
self.rnn = nn.LSTM(emb_dim, hid_dim)
#FC层
self.fc_out = nn.Linear(emb_dim + hid_dim, output_dim)
#使用dropout进行处理RNN
self.dropout = nn.Dropout(dropout)
-
Attention机制:由于LSTM获得每个时间点的输出信息之间的“影响程度”都是一样的,而在关系分类中,为了能够突出部分输出结果对分类的重要性,引入加权的思想,注意力机制本质上就是加权求和。
将LSTM层输入的向量集合表示为H:[h1,h2,…,hT]。其Attention层得到的权重矩阵由下面的方式得到 :
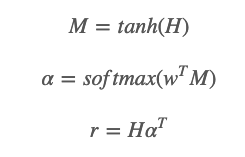
-
在LSTM模型上加入Attention层,在LSTM中用最后一个时序的输出向量作为特征向量,然后进行文本分类。Attention是先计算每个时序的权重,然后将所有时序的向量进行加权和作为特征向量,然后进行文本分类。
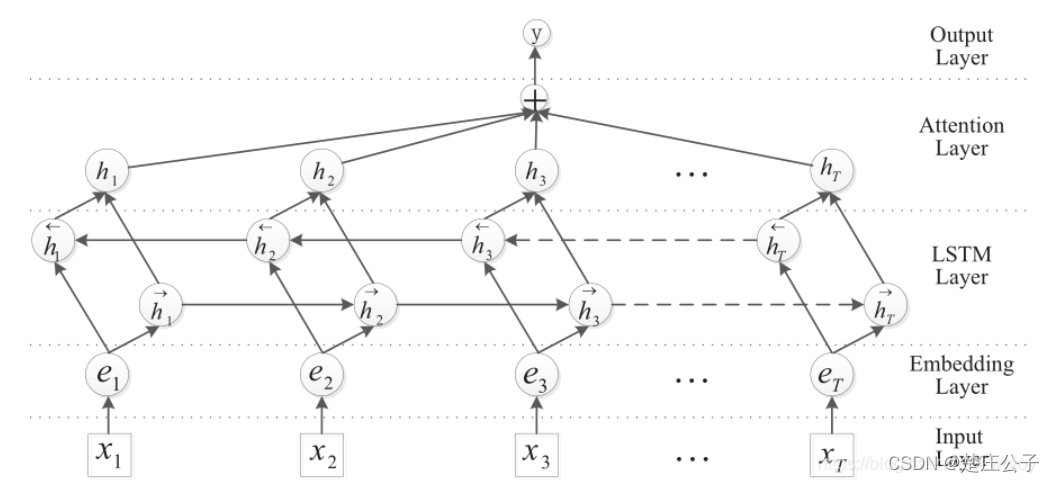
输入层:将句子输入到模型中
Embedding层:将每个词映射到低维空间
LSTM层:使用双向LSTM从Embedding层获取高级特征
Attention层:生成一个权重向量,通过与这个权重向量相乘,使每一次迭代中的词汇级的特征合并为句子级的特征。
输出层:将句子级的特征向量用于关系分类 -
总体上,__ init __()初始化了一个词汇表大小为50004,嵌入后向量大小为200,每个词的输出向量维度为256的层。接下来定义forward函数,使用该层。
forward()函数
#forward函数使用定义在__init__函数中的层
def forward(self, input, hidden, context):
input = input.unsqueeze(0)
embedded = self.dropout(self.embedding(input))
#输出来自隐藏顶层
#output = [seq len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
output, hidden = self.rnn(embedded, hidden)
#在解码器中,n层和n个方向总是1
#output = [1, batch size, hid dim]
#hidden = [1, batch size, hid dim]
h,c = hidden
context = nn.Tanh()(context)
h = self.attention_layer(h)
#使两者矩阵相乘
w = torch.bmm(context, h.permute(1,2,0))
#将context的第二维度消掉
w = w.squeeze()
#使用F.softmax(w,dim=-1)归一化,得到基于上下文权重的w
w = F.softmax(w,dim=-1)
#使用torch.bmm(w, h)得到基于权重的LSTM输出context
w = torch.bmm(w.unsqueeze(1), context)
w = w.squeeze()
#纵向连接
output = torch.cat((embedded.squeeze(0),w),
dim = 1)
#output = [batch size, emb dim + hid dim * 2]
prediction = self.fc_out(output)
#prediction = [batch size, output dim]
return prediction, hidden
- torch.bmm()函数:
计算两个tensor的矩阵乘法,torch.bmm(a,b),tensor a 的size为(b,h,w),tensor b的size为(b,w,h),两个tensor的维度必须为3。
示例代码:
>>> c=torch.randn((2,5))
>>> print(c)
tensor([[ 1.0559, -0.3533, 0.5194, 0.9526, -0.2483],
[-0.1293, 0.4809, -0.5268, -0.3673, 0.0666]])
>>> d=torch.reshape(c,(5,2))
>>> print(d)
tensor([[ 1.0559, -0.3533],
[ 0.5194, 0.9526],
[-0.2483, -0.1293],
[ 0.4809, -0.5268],
[-0.3673, 0.0666]])
>>> e=torch.bmm(c,d)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: Dimension out of range (expected to be in range of [-2, 1], but got 2)
tensor维度为2时报错。
- torch.cat(seq,dim,out=None)函数:
其中seq表示要连接的两个序列,以元组的形式给出,例如:seq=(a,b), a,b 为两个可以连接的序列。dim 表示以哪个维度连接,dim=0, 横向连接,dim=1,纵向连接。在此表示纵向方式连接embedded和w两个序列。
示例代码:
import torch
a = torch.ones([1, 2])
b = torch.ones([1, 2])
print(torch.cat([a, b], 1)) # dim=1纵向连接
print(torch.cat([a, b], 0)) # dim=0横向连接
输出结果:
tensor([[1., 1., 1., 1.]])
tensor([[1., 1.],
[1., 1.]])
纵向连接之后,维度变成1 * 4
横向连接之后,维度变成2 * 2
- 总体上,decoder的输出作为最终输出层的输入,经过两步
(1)linear线性连接,也即是w * x + b
(2)softmax归一化,向量长度等于vocabulary的长度,得到vocabulary中每个字的概率。利用beam-search方法,即可得到生成结果。
三、总结
本周学习了LSTM模型,并由此对Model.py的Decoder类展开了分析。下周将开展对my_dataloader.py的分析。


















 2749
2749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









