 基于深度学习的知识图谱客户端项目
基于深度学习的知识图谱客户端项目




一.项目概述
知识图谱(Knowledge Graph)是一种结构化的语义知识库,通过**实体(Entity)、关系(Relationship)和属性(Attribute)**的形式描述现实世界中的事物及其关联,并以图结构(节点和边)组织数据。它的核心目标是为机器提供可理解的语义信息,支持智能推理和复杂查询。
本项目采用tkinter以及其优化库ttkbootstrap写的知识图谱客户端,纯python代码所以配置环境不复杂,适合配合网页端手机端做客户端,文件里提供相关方式配合运行。该项目简单方便只需要python就可以运行。
可以添加网页端实现数据互通,这是客户端的部分,可以打包成电脑软件运行,网页端和手机端部分后续会发出。
该客户端主要是为了方便使用,可以进行知识图谱的提取,包括命名实体识别,关系抽取等方法构建。
核心技术栈
| 组件 | 技术选型 | 作用 |
|---|---|---|
| 前端框架 | tkinter + ttkbootstrap | 跨平台GUI开发,界面现代化 |
| NLP处理引擎 | bertbilstm-crf | 实体识别、关系抽取(支持自定义模型) |
| 图谱存储 | Neo4j/json文件 | 图数据管理与查询 |
| 部署工具 | PyInstaller | 打包为Windows/macOS/Linux可执行文件 |
二.配置相关环境(仅需python以及其相关库)
为了方便大家使用单独发出客户端方式的知识图谱来给大家使用本项目使用纯python代码,方便配置环境。
将文件夹切换到相关的文件夹内运行
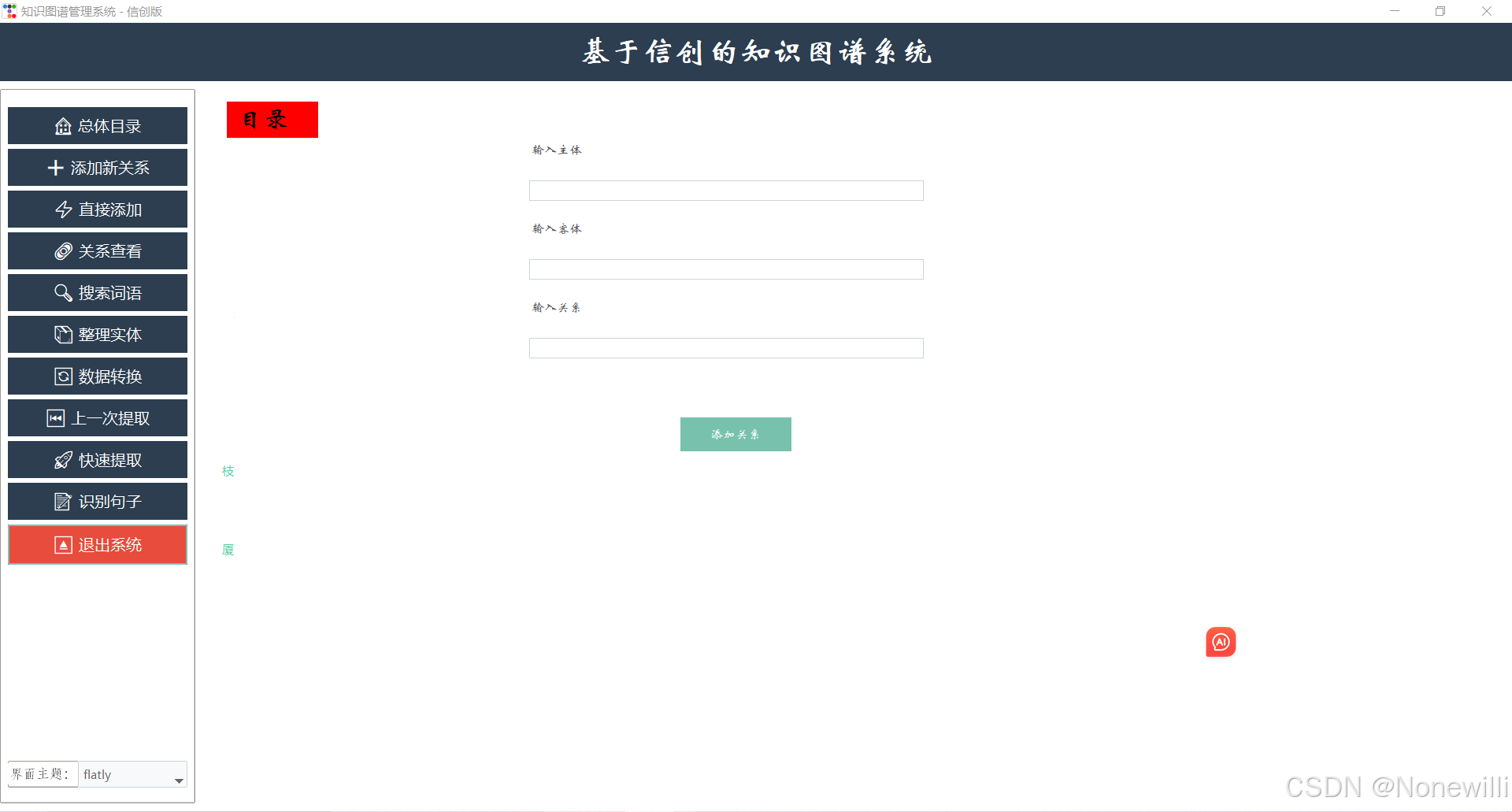
1. 基本用法
-
作用:根据
requirements.txt文件中的列表,自动安装所有依赖包。 -
命令格式:
pip install -r requirements.txt
2. 使用步骤
(1) 确保文件存在
-
在项目根目录下需要有一个
requirements.txt文件,内容格式如下:-
每行一个包,可指定版本(如
==1.0.0)或不指定(默认安装最新版)。
-
(2) 执行安装命令
-
打开终端(命令行),切换到
requirements.txt所在目录,运行:
pip install -r requirements.txt可以安装相关的库
三.项目介绍
该项目主要分为三个部分,其中第三部分为网页端手机端链接部分,该部分需要其他部分代码配合,暂不演示。
项目结构整体目录
Knowledge-graph(主要的文件)
-part 项目用的函数库(包括bertbilstm,lstm等算法)
-model 包括训练的模型,命名实体识别等
-gui.py 项目运行文件
-requirements.txt 安装相关的库
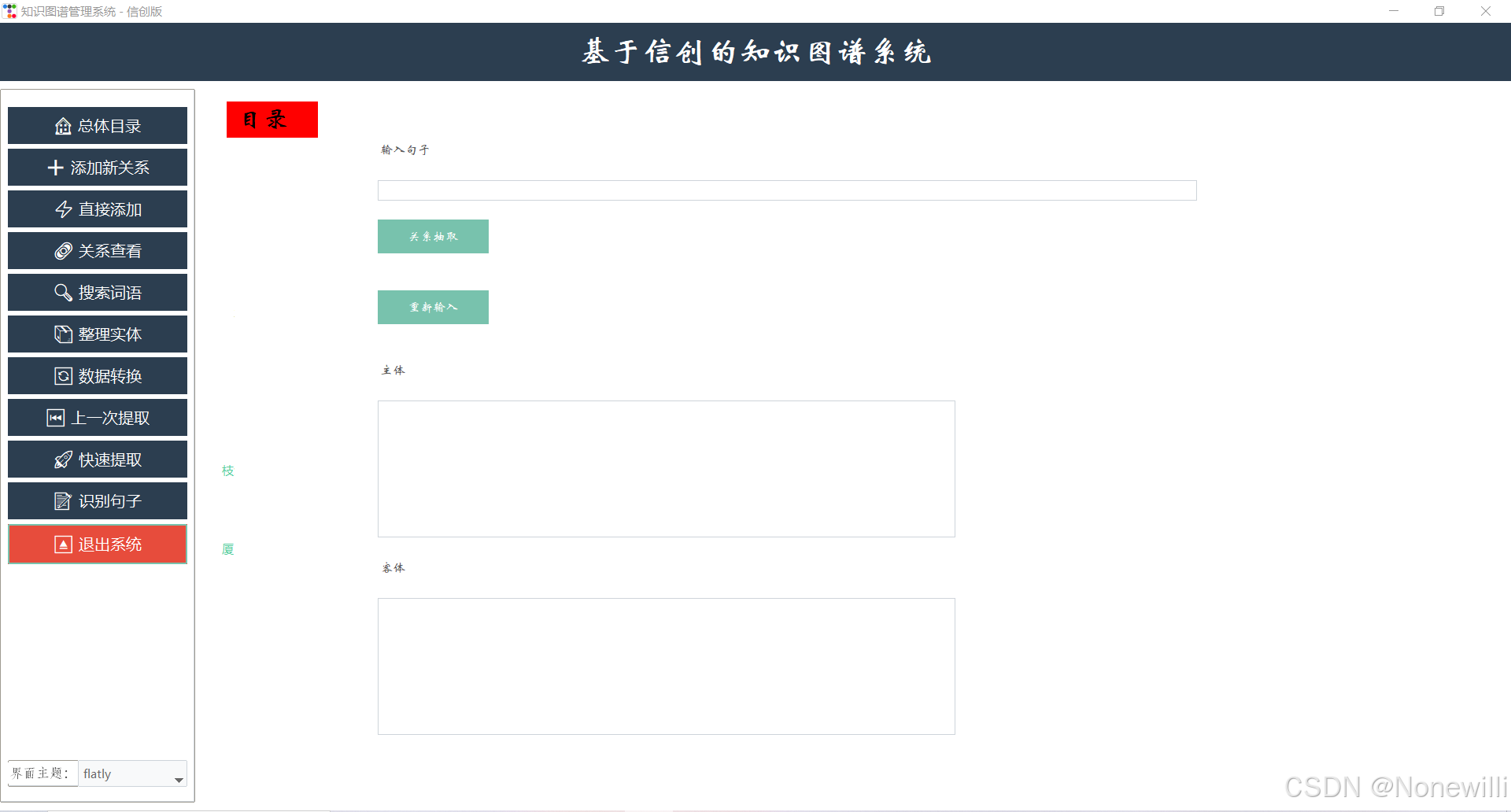
1.界面设计
由于tkinter本身的组件没有html内的丰富,所以对于这些字,我们采用直接覆盖式添加主键(如果看的人多的话我会考虑再优化优化)
def mulu():
global y_index
global num_nums
y_index = 0
num_nums = 0
tianchong()
def create_knowledge_graph(window, data, relation_data, selected_node):
# Clear previous content
for widget in window.winfo_children():
if isinstance(widget, ttk.Frame) and widget.winfo_name() == "graph_frame":
widget.destroy()
# Create styled frame
frame = ttk.Frame(window, width=1500, height=820, name="graph_frame")
frame.place(relx=0.15, rely=0.15, relwidth=0.9, relheight=0.9)
# Create canvas with modern gradient background
canvas = tk.Canvas(frame, width=1500, height=820, highlightthickness=0)
canvas.pack(fill="both", expand=True)
# Draw gradient background
for i in range(820):
gradient_ratio = i / 820
color = '#{:02x}{:02x}{:02x}'.format(
int(245 + 10 * gradient_ratio),
int(247 + 8 * gradient_ratio),
int(250 - 10 * gradient_ratio)
)
canvas.create_line(0, i, 1500, i, fill=color)
mulu()函数通过建立相关的主键按钮来对相关项目进行建立,初始化全局变量后调用create_knowledge_graph()创建可视化界面。

def create_knowledge_graph(window, data, relation_data, selected_node):
"""
Creates an optimized, aesthetically pleasing knowledge graph visualization
Args:
window: The parent window
data: Dictionary of node data
relation_data: Dictionary of relationship data
selected_node: The selected central node
"""
# Clear previous content
for widget in window.winfo_children():
if isinstance(widget, ttk.Frame) and widget.winfo_name() == "graph_frame":
widget.destroy()
# Create styled frame
frame = ttk.Frame(window, width=1500, height=820, name="graph_frame")
frame.place(relx=0.15, rely=0.15, relwidth=0.9, relheight=0.9)
# Create canvas with modern gradient background
canvas = tk.Canvas(frame, width=1500, height=820, highlightthickness=0)
canvas.pack(fill="both", expand=True)
# Draw gradient background
for i in range(820):
gradient_ratio = i / 820
color = '#{:02x}{:02x}{:02x}'.format(
int(245 + 10 * gradient_ratio),
int(247 + 8 * gradient_ratio),
int(250 - 10 * gradient_ratio)
)
canvas.create_line(0, i, 1500, i, fill=color)
# Modern color scheme
colors = {
'primary': '#4A90E2',
'secondary': '#7ED321',
'accent': '#FF6B6B',
'text': '#2C3E50',
'background': '#F8F9FA',
'relation': '#A389D4',
'shadow': '#000000'
}
# Improved node styling parameters
NODE_CONFIG = {
'central_radius': 48,
'node_radius': 36,
'relation_radius': 28,
'font': ('Segoe UI', 14),
'line_width': 3
}
# Create dynamic layout positions
center_x, center_y = 750, 410
node_positions = {}
# Draw central node with modern effects
def create_central_node():
# Glow effect
for i in range(1, 6):
glow_size = NODE_CONFIG['central_radius'] + i * 6
canvas.create_oval(
center_x - glow_size, center_y - glow_size,
center_x + glow_size, center_y + glow_size,
outline=f'#FF6B6B',
width=0,
stipple='gray50'
)
# Main node
canvas.create_oval(
center_x - NODE_CONFIG['central_radius'],
center_y - NODE_CONFIG['central_radius'],
center_x + NODE_CONFIG['central_radius'],
center_y + NODE_CONFIG['central_radius'],
fill=colors['accent'],
outline=''
)
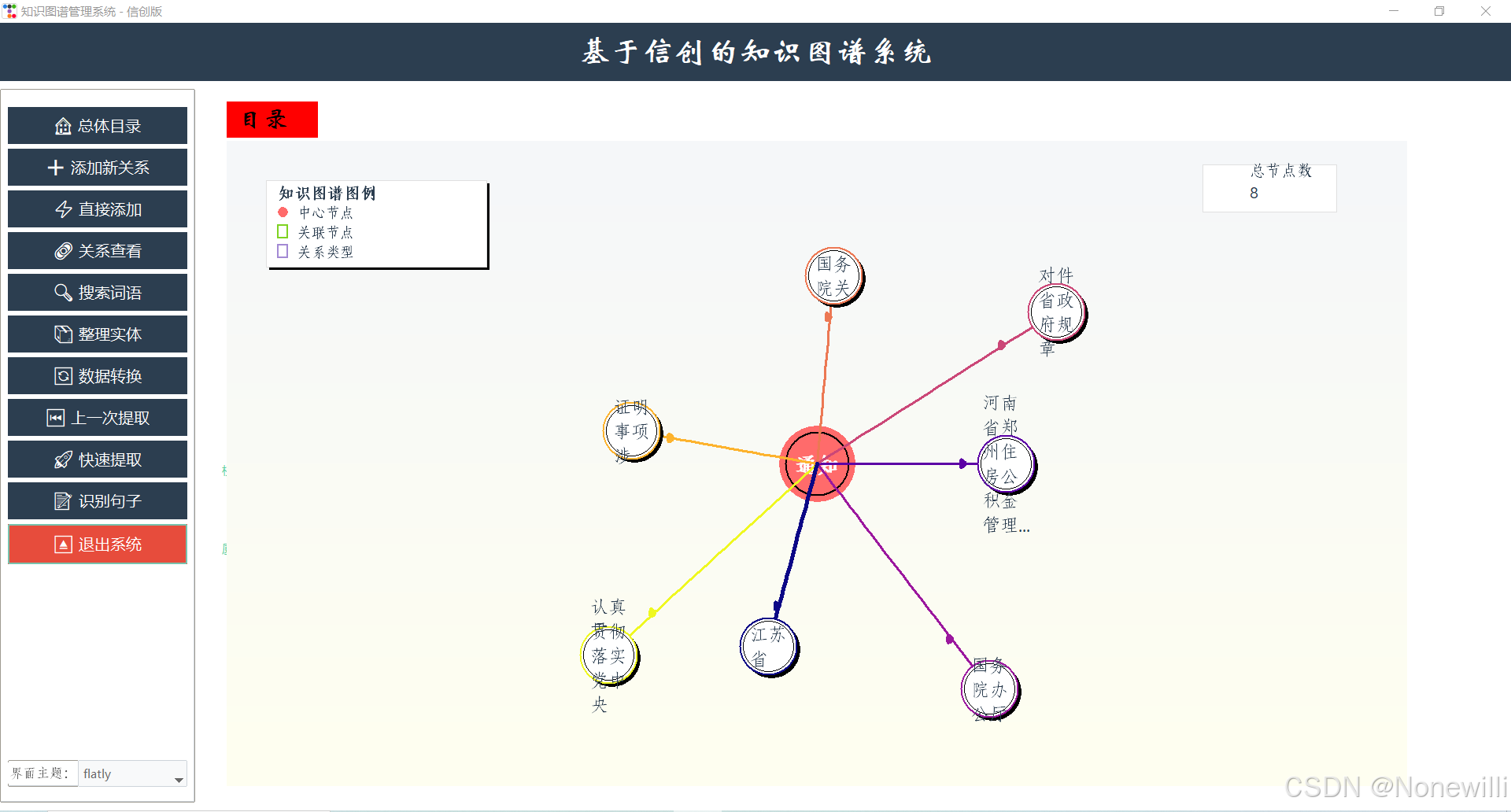
create_knowledge_graph()函数对相关的图进行绘制,如果是网页项目可以采用neo4j来写,这是客户端部分,可以使用neo4j但是为了好运行采用了json文件来储存
,
2.算法设计
这些函数包括命名实体识别,关系抽取等算法。具体放在文件包里了。
命名实体识别采用bert配合bilstm来进行抽取相关的实体,通过将句子通过bert模型来对相关词进行向量处理,然后通过bilstm来对得到相关实体。
-
BERT层:将输入文本转换为上下文相关的词向量。
-
例如,句子
"Apple released a new product"中的 "Apple" 会根据上下文被编码为“公司”而非“水果”。
-
-
BiLSTM层:捕获序列的长期依赖关系(如前后词的关联)。
-
双向LSTM分别从正向和反向处理序列,融合两个方向的隐藏状态。
-
class BiLSTM_CRF(nn.Module):
def __init__(self, embedding_dim, hidden_dim, vocab, label_map, device='cpu'):
super(BiLSTM_CRF, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = len(vocab)
self.tagset_size = len(label_map)
self.device = device
self.state = 'train'
self.bert = BertModel.from_pretrained('bert-base-chinese')
config = self.bert.config
self.tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
self.word_embeds = nn.Embedding(self.vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, num_layers=2, bidirectional=True, batch_first=True)
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size, bias=True)
self.crf = CRF(label_map, device)
self.dropout = nn.Dropout(p=0.5, inplace=True)
self.layer_norm = nn.LayerNorm(self.hidden_dim)
self.max_length = 50
self.linear = nn.Linear(768, 128)
def _get_lstm_features(self, sentence, seq_len):
embeds = sentence
self.dropout(embeds)
packed = torch.nn.utils.rnn.pack_padded_sequence(embeds, seq_len.cpu(), batch_first=True, enforce_sorted=False)
lstm_out, _ = self.lstm(packed)
seq_unpacked, _ = torch.nn.utils.rnn.pad_packed_sequence(lstm_out, batch_first=True)
seqence_output = self.layer_norm(seq_unpacked)
lstm_feats = self.hidden2tag(seqence_output)
return lstm_feats
def __get_lstm_features(self, sentence, seq_len):
max_len = sentence.shape[1]
mask = [[1] * seq_len[i] + [0] * (max_len - seq_len[i]) for i in range(sentence.shape[0])]
embeds = self.word_embeds(sentence)
self.dropout(embeds)
mask = torch.tensor(mask, dtype=torch.float32, device=self.device)
input = embeds * mask.unsqueeze(2)
lstm_out, _ = self.lstm(input)
seqence_output = self.layer_norm(lstm_out)
lstm_feats = self.hidden2tag(seqence_output)
return lstm_feats
def forward(self, sentence, seq_len, text, tags=''):
sen = []
for sen_s in text:
x = self.tokenizer.encode_plus(sen_s, return_token_type_ids=True, return_attention_mask=True,
return_tensors='pt',
padding='max_length', max_length=self.max_length).to(device)
bert_output = \
self.bert(input_ids=x.input_ids, attention_mask=x.attention_mask, token_type_ids=x.token_type_ids)[0]
bert_output = self.linear(bert_output)
bert_output = torch.squeeze(bert_output, dim=0)
bert_output = bert_output.tolist()
lens = len(bert_output)
if lens > 50:
del bert_output[50:lens]
sen.append(bert_output)
sen = torch.Tensor(sen).to(device)
sentence = sen
feats = self._get_lstm_features(sentence, seq_len)
if self.state == 'train':
loss = self.crf.neg_log_likelihood(feats, tags, seq_len)
return loss
elif self.state == 'eval':
all_tag = []
for i, feat in enumerate(feats):
all_tag.append(self.crf._viterbi_decode(feat[:seq_len[i]])[1])
return all_tag
else:
return self.crf._viterbi_decode(feats[0])[1]
同时关系抽取中我们采用bert-bilstm-crf模型来对数据进行处理
(1) BERT层:生成上下文词向量
-
功能:将输入的文本转换为动态的上下文相关向量。
-
输入:原始文本(如句子:
["CLS"] + ["Einstein", "was", "born", "in", "Germany"] + ["SEP"]) -
输出:每个token的上下文嵌入(维度:
[batch_size, seq_len, hidden_size=768]) -
关键点:
-
BERT捕捉双向语义(如“苹果”根据上下文区分公司或水果)。
-
通常使用预训练模型(如
bert-base-uncased)并可能微调。
-
(2) BiLSTM层:捕捉序列依赖
-
功能:进一步学习序列的局部和长期依赖关系。
-
输入:BERT输出的词向量(
[batch_size, seq_len, 768]) -
输出:每个token的双向隐藏状态(维度:
[batch_size, seq_len, hidden_size*2],如256×2=512) -
关键点:
-
双向LSTM同时考虑过去和未来信息。
-
可堆叠多层增强表达能力。
-
(3) CRF层:全局标签解码
-
功能:根据标签转移约束,解码最优标签序列。
-
输入:BiLSTM的输出(发射分数矩阵
[batch_size, seq_len, num_tags]) -
输出:最优标签序列(如
B-PER, O, O, O, B-LOC) -
关键点:
-
转移矩阵:学习标签之间的转移概率(如
B-PER后不能接I-LOC)。 -
维特比算法:解码时寻找全局最优路径。
-
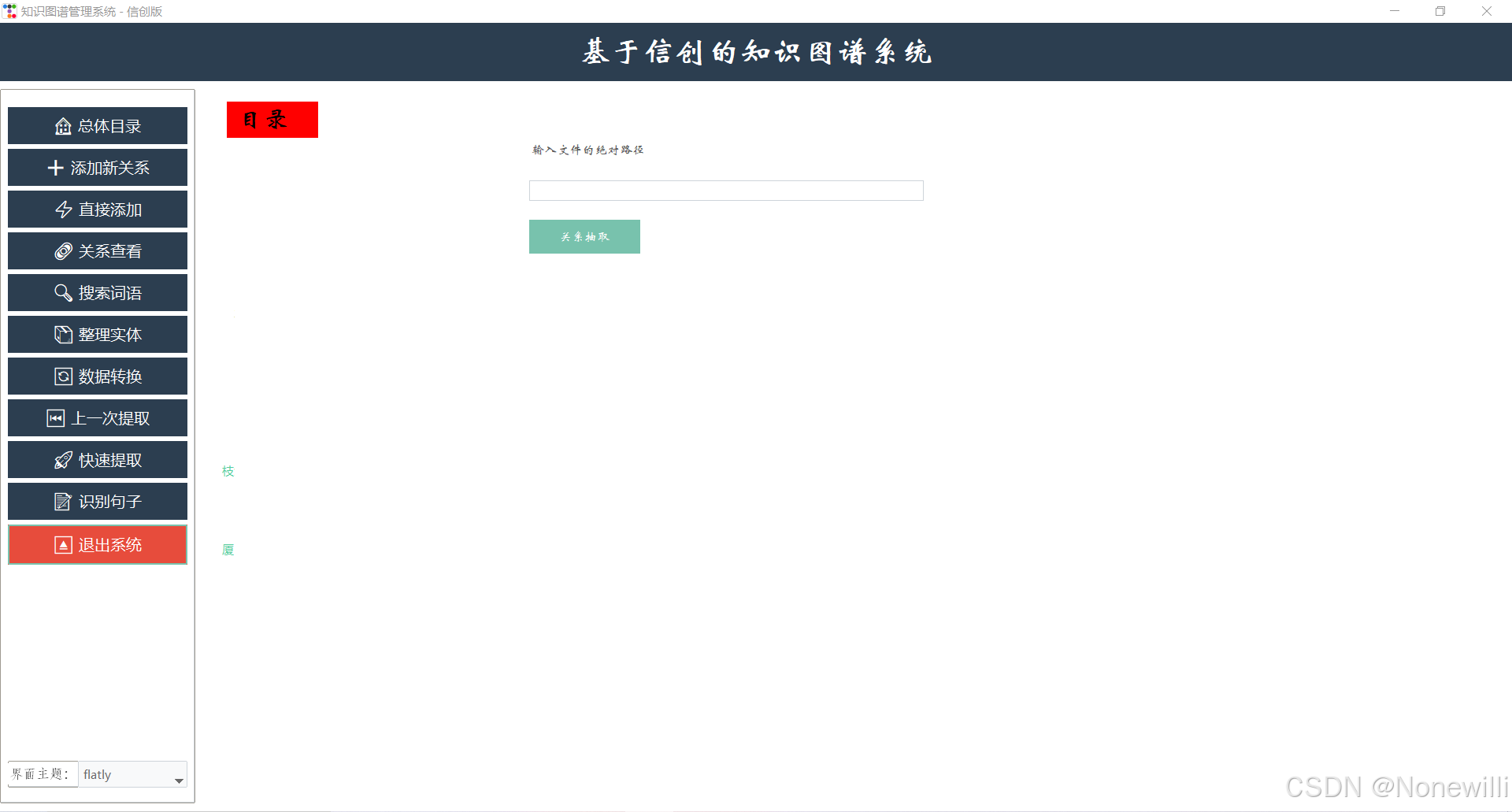
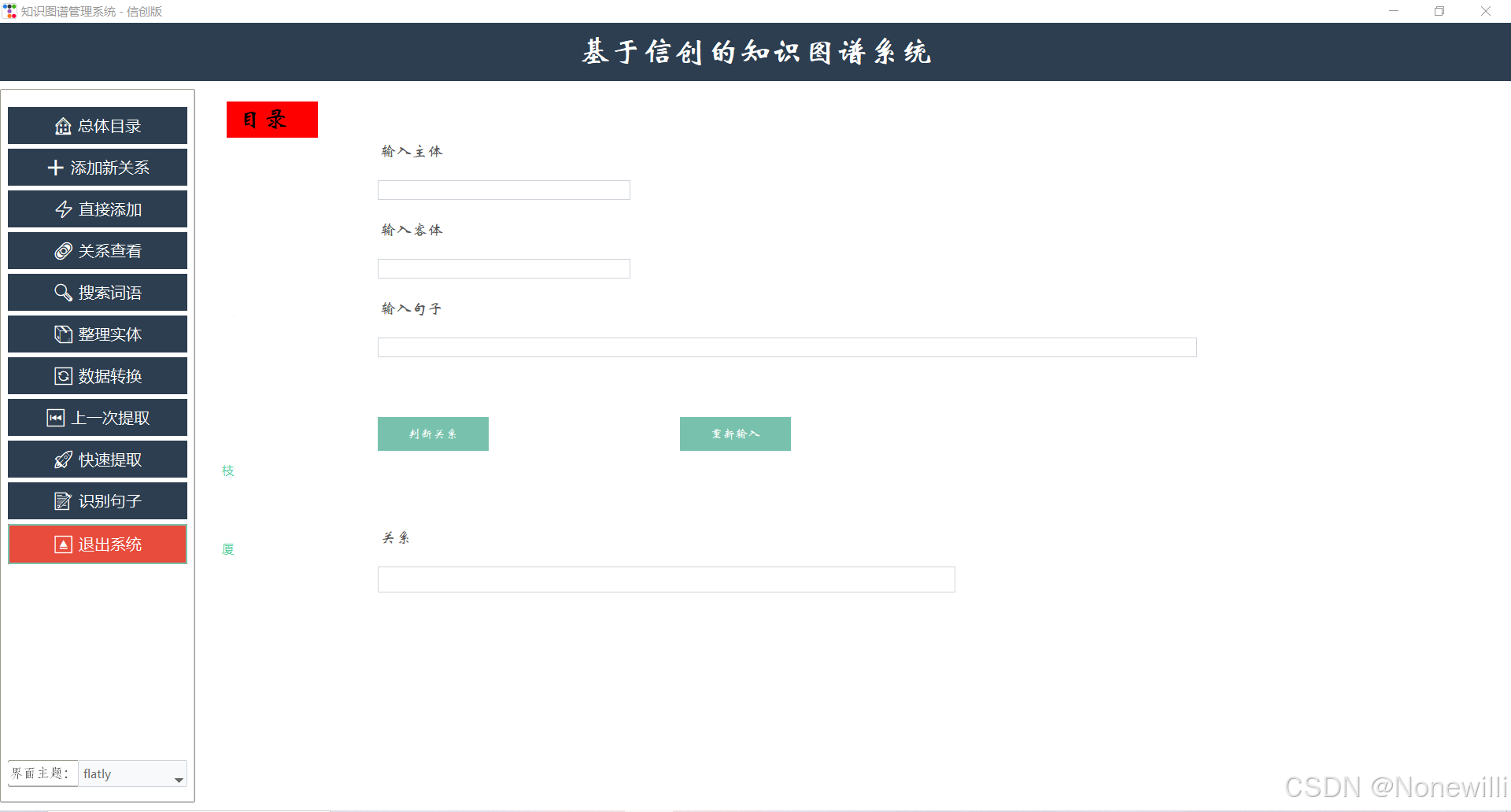
四.项目获得
项目我放到github上了,想要的可以自行下载,记得点个star,谢谢。
_(:3 ⌒゙)_

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









