







1数据库的概述
数据库 即存储数据的“仓库”,其本质是一个文件系统。它保存了一系列有组织的数据。
数据库管理系统 是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制。用户通过数据库管理系统访问数据库中表内的数据。
SQL结构化查询语言 数据库通信的语言。
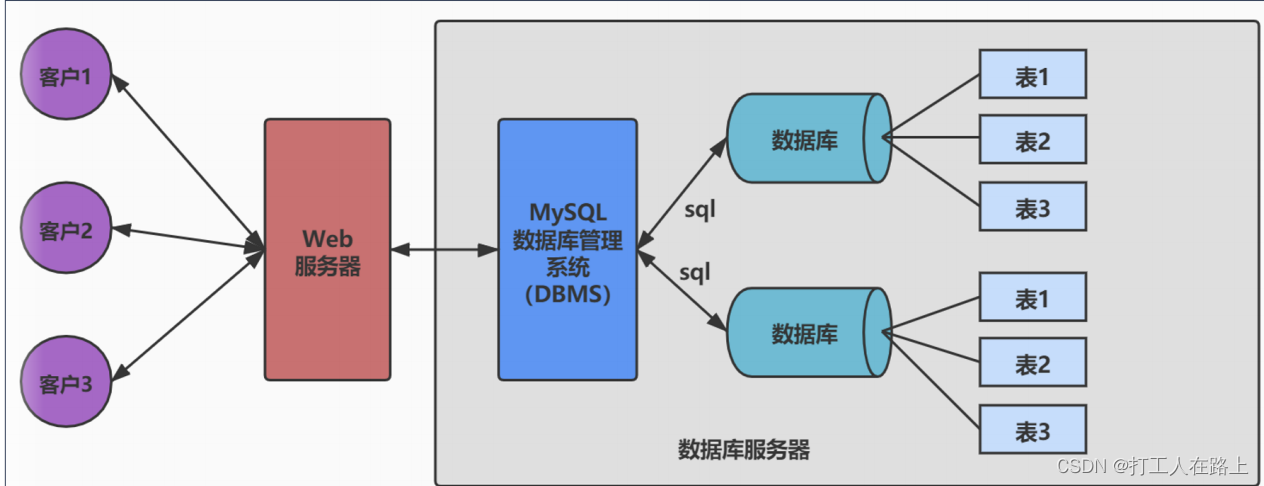
== 关系形数据库(RDBMS)== 行(row) 和 列(column) 的形式存储数据,以便于用户理解。SQL 就是关系型数据库的查询语言。
非关系形数据库:键值型数据库(Redis)
2.基本的select查询

DISTINCT 去重 distinct
IFNULL(commission_pct,0) 防止null参与运算导致结果是null
SQL中赋值符号使用 :=
desc table表名;
select distinct 字段 AS 别名,字段 别名
from 表名
where 过滤条件
group by 字段名 WITH ROLLUP
【WITH ROLLUP 关键字:增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。】
having 包含组函数的过滤条件
order by 字段名 DESC/ASC(默认),字段名称 DESC
limit 偏移量(从哪开始) 显示多少个;
#查询commission_pct等于NULL。比较如下的四种写法
SELECT employee_id,commission_pct FROM employees WHERE commission_pct IS NULL;
SELECT employee_id,commission_pct FROM employees WHERE commission_pct <=> NULL;
SELECT employee_id,commission_pct FROM employees WHERE ISNULL(commission_pct);
SELECT employee_id,commission_pct FROM employees WHERE commission_pct = NULL;
使用安全等于运算符时,两边的操作数的值都为NULL时,返回的结果为1而不是NULL,其他
返回结果与等于运算符相同。


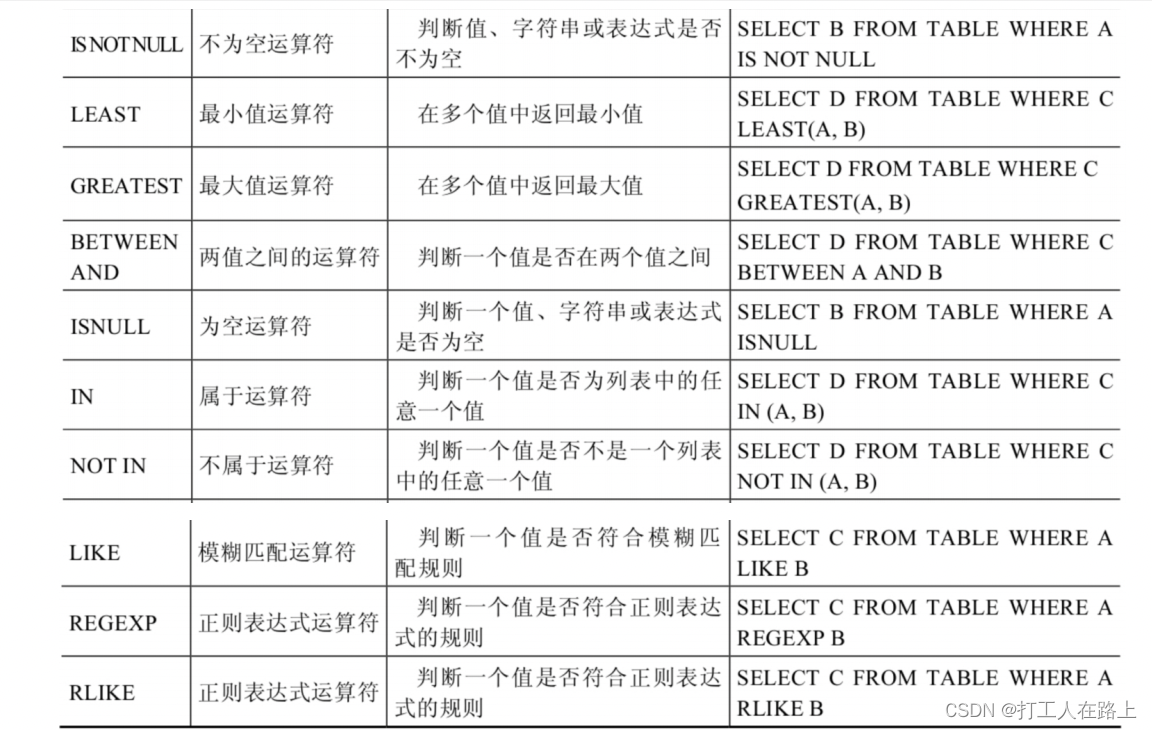
like 的通配符:“%”:匹配0个或多个字符。 “_”:只能匹配一个字符。
3.多表的查询
连接 n个表,至少需要n-1个连接条件。
最简单的多表 内查询(等值连接) :
#案例:查询员工的姓名及其部门名称
SELECT e.last_name, d.department_name
FROM employees e, departments d
WHERE e.department_id =d.department_id;
内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
如果是左外连接,则连接条件中左边的表也称为 主表 ,右边的表称为 从表 。
如果是右外连接,则连接条件中右边的表也称为 主表 ,左边的表称为 从表 。
内连接(sql99语法)
SELECT 字段列表
FROM A表
INNER JOIN B表
ON 关联条件
WHERE 等其他子句;
外连接
SELECT 字段列表
FROM A表
LEFT(RIGHT)【满外 full】 OUTER JOIN B表
ON 关联条件
WHERE 等其他子句;
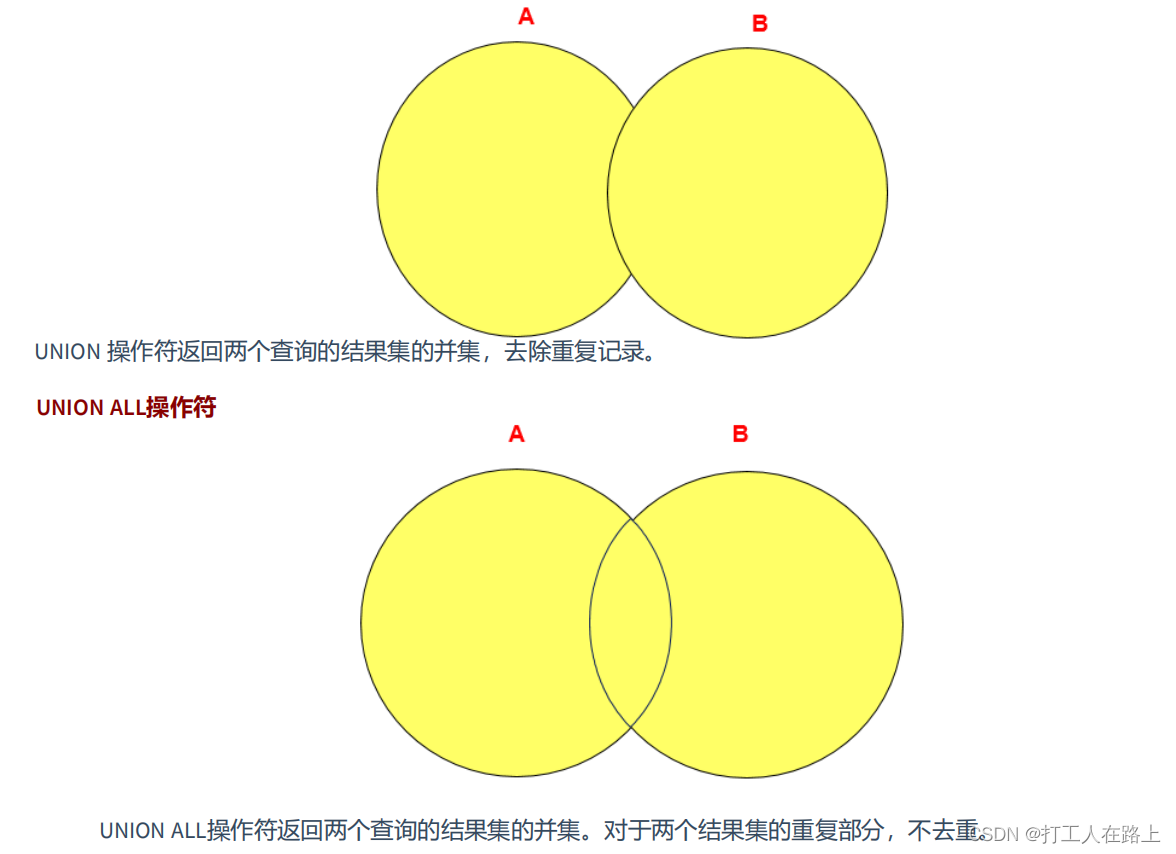
UNION的使用:可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并
时,两个表对应的列数和数据类型必须相同,并且相互对应。各个SELECT语句之间使用UNION或UNION ALL关键字分隔。
SELECT id,cname
FROM t_chinamale WHERE csex='男'
UNION ALL
SELECT id,tname FROM t_usmale WHERE tGender='male';
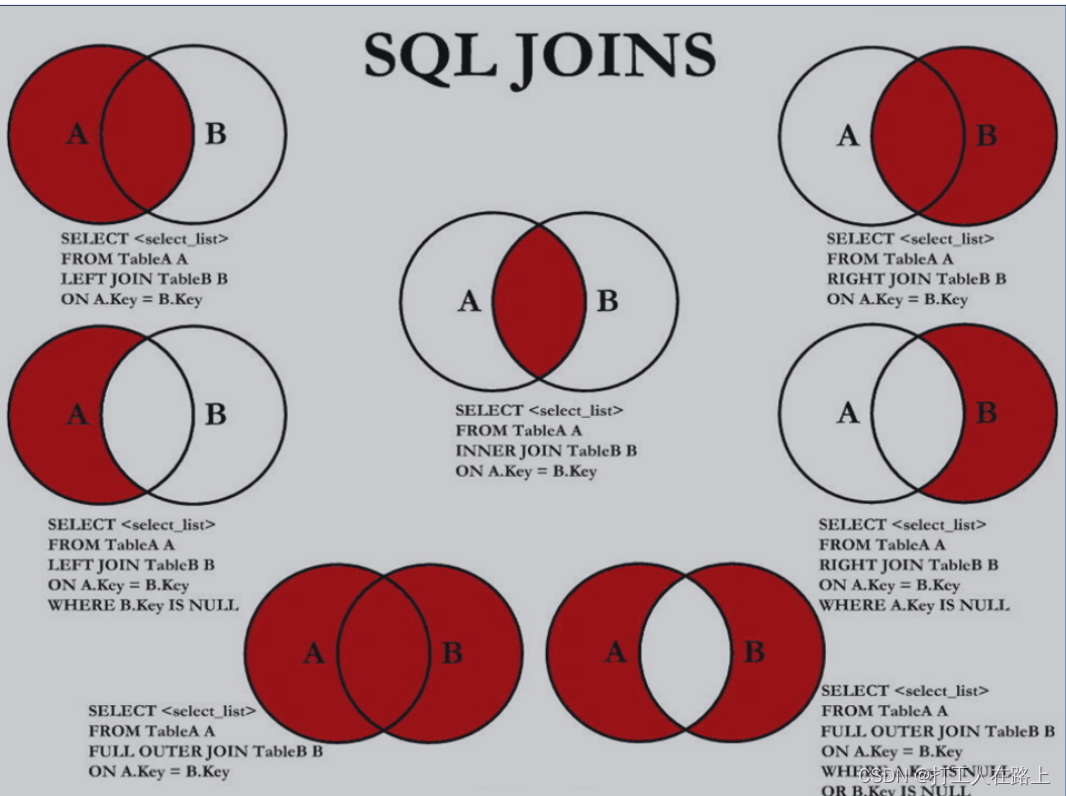


自然连接 NATURAL JOIN 用来表示自然连接。自然连接理解为 SQL92 中的等值连接。它会帮你自动查询两张连接表中 所有相同的字段 ,然后进行 等值 连接 。
SELECT employee_id,last_name,department_name
FROM employees e NATURAL JOIN departments d;
4.内置函数
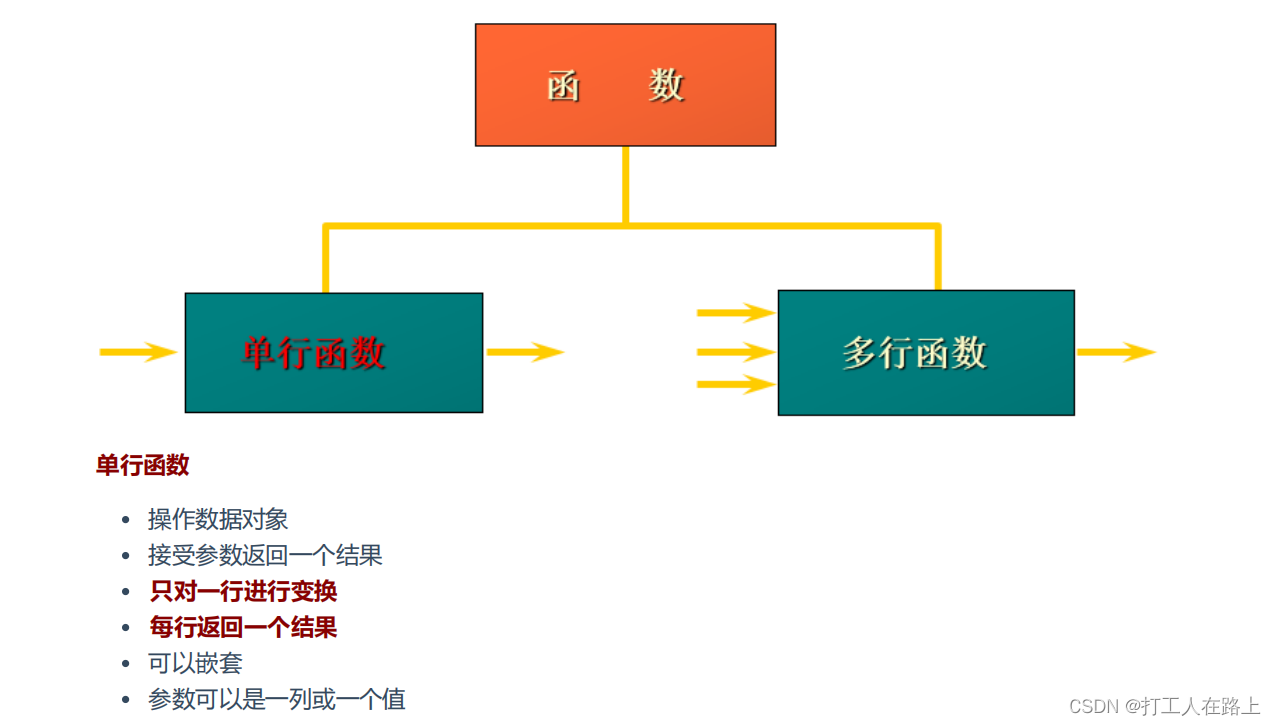
基本函数
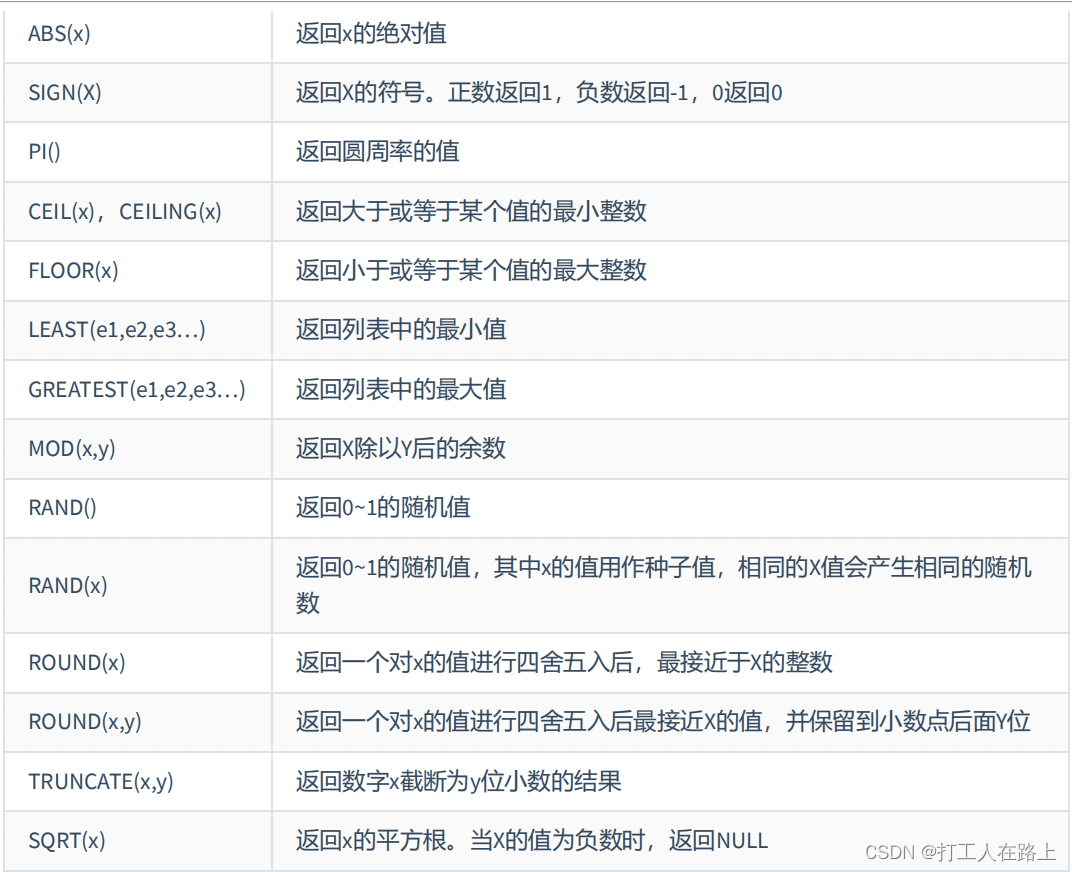
二进制转化函数
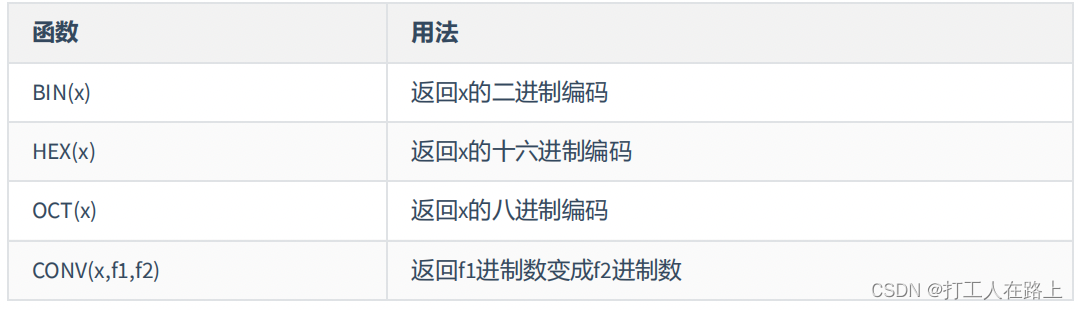
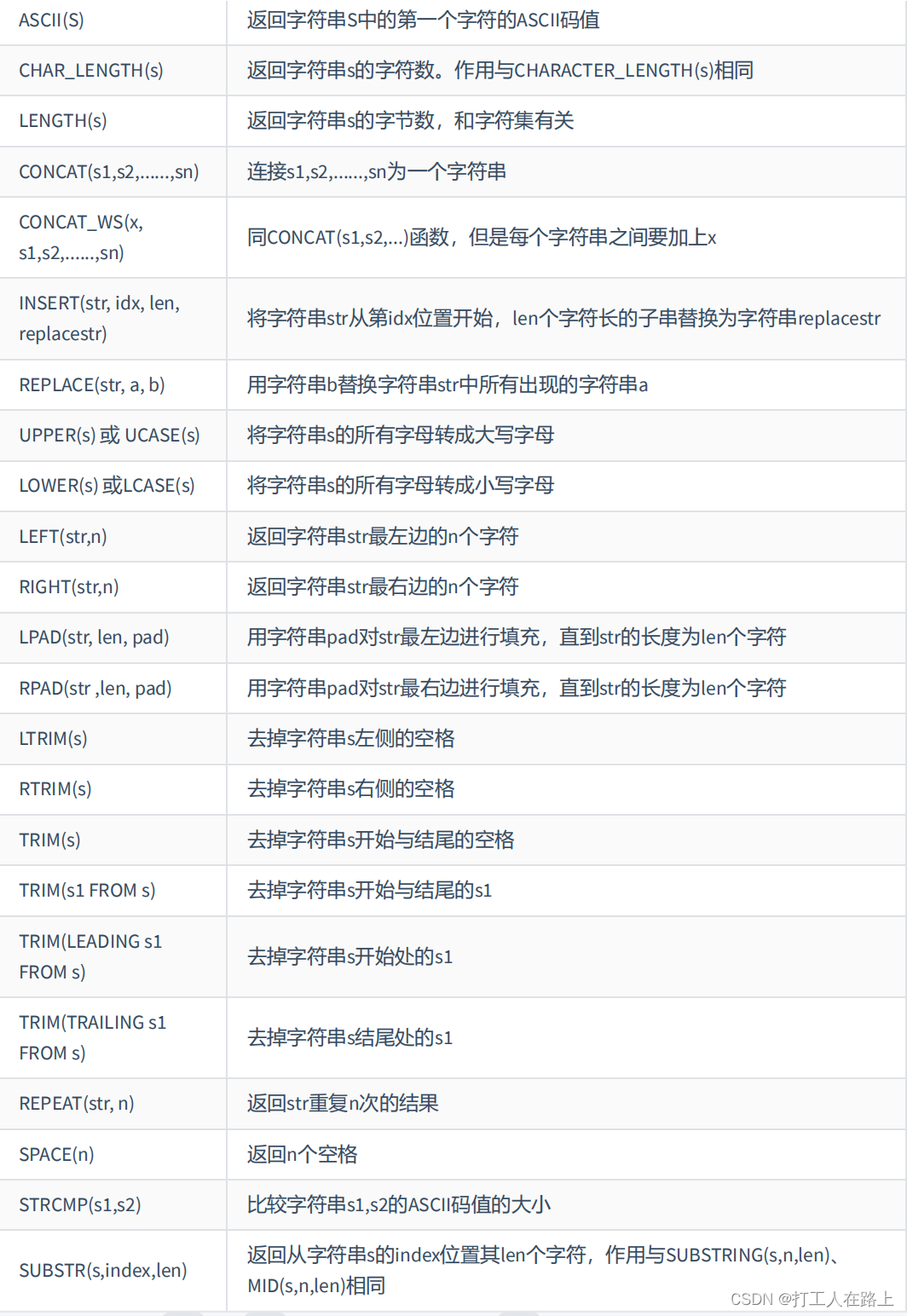
字符串函数
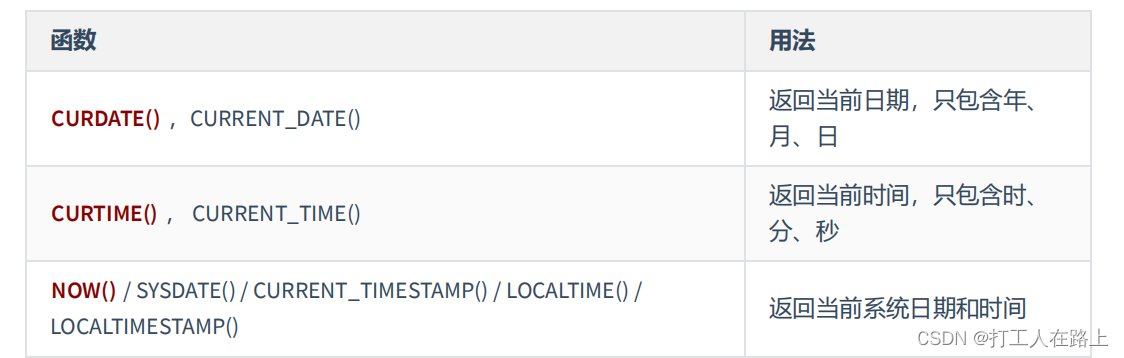
5.聚合函数
对数值型数据使用AVG 和 SUM 函数。
对任意数据类型的数据使用 MIN 和 MAX 函数。
COUNT()返回表中记录总数,**适用于任意数据类型。
**count()会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。

having的使用:必须放在GROUP BY后面,使用了聚类函数的过滤条件


SELECT DISTINCT ...,....,... 【5】
FROM ... 【1】
JOIN ... ON 多表的连接条件
WHERE 不包含聚函数的过滤条件 【2】
AND/OR 不包含聚函数的过滤条件
GROUP BY ...,... 【3】
HAVING 包含聚函数的过滤条件 【4】
ORDER BY ... ASC/DESC 【6】
LIMIT ...,...【7】
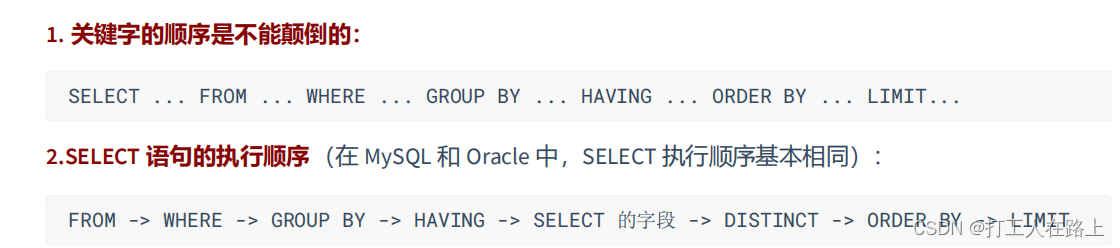
6.子查询



case字段名 when xxxxxx then
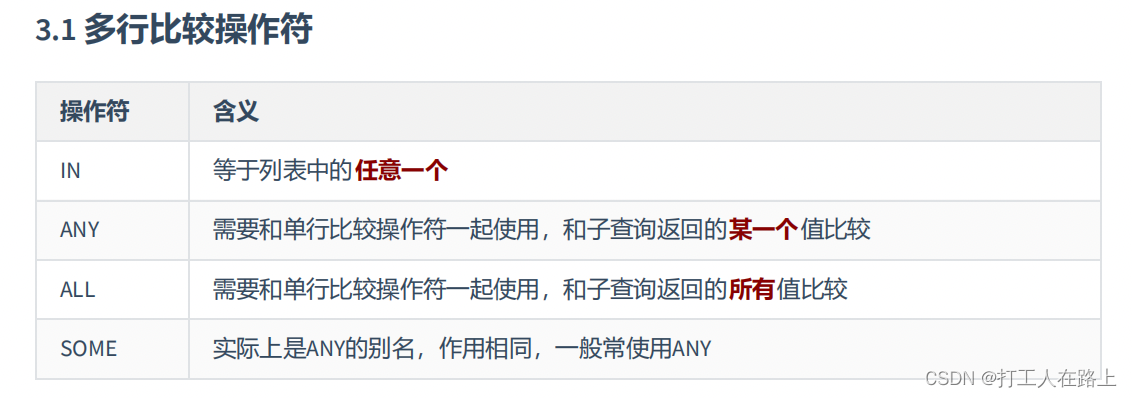
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) <= ALL (
SELECT AVG(salary) avg_sal
FROM employees
GROUP BY department_id )
相关子查询:如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为 关联子查询 。
相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询。
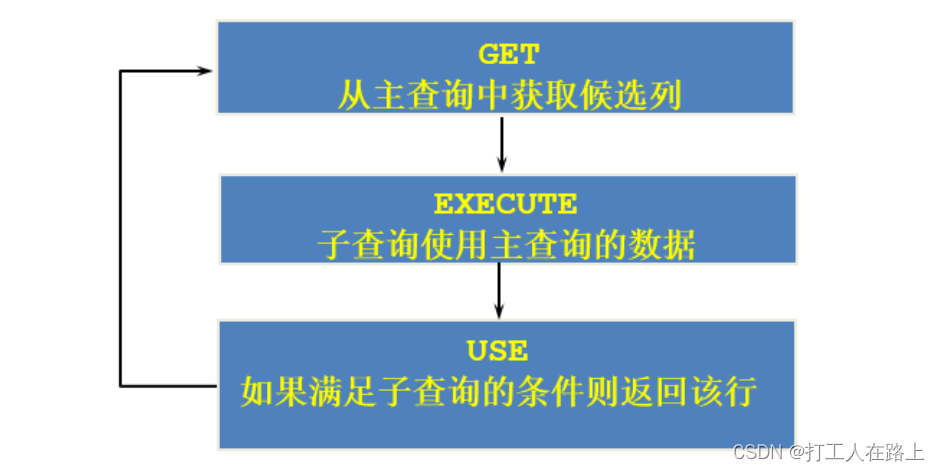
题目:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id
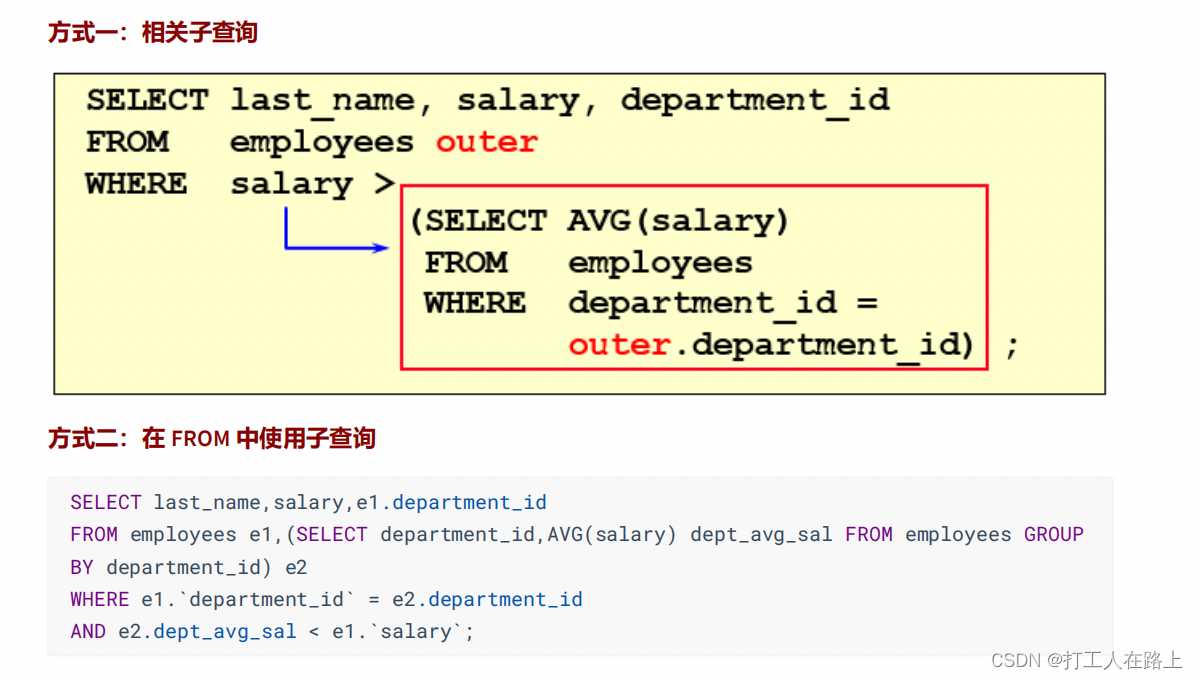
EXISTS 与 NOT EXISTS关键字:用来检查在子查询中是否存在满足条件的行。
查询公司管理者的employee_id,last_name,job_id,department_id信息
SELECT employee_id, last_name, job_id, department_id
FROM employees e1
WHERE EXISTS (
SELECT *
FROM employees e2
WHERE e2.manager_id = e1.employee_id
);
7.创建和管理数据库(表)DDL

从系统架构的层次上看,MySQL 数据库系统从大到小依次是数据库服务器 、 数据库 、 数据表 、数据表的 行与列 。
数据库的操作指令:create alter drop
CREATE DATABASE IF NOT EXISTS 数据库名;
更改数据库:ALTER DATABASE 数据库名 CHARACTER SET 字符集;
DROP DATABASE IF EXISTS 数据库名;
表table的创建
方法一:
CREATE TABLE [IF NOT EXISTS] 表名(
id, int PRIMARY KEY AUTO_INCREMENT default x,
字段2, 数据类型 [约束条件] [默认值],
字段3, 数据类型 [约束条件] [默认值]
constraint 起个别名 PRIMARY KEY (deptno) #表约束
);
方法二:

SHOW CREATE TABLE【database】 表名【数据库名】
修改表ALTER alter 增加: add 修改:modify 重命名:change 删除
格式:alter table 表名 add/modify/change/drop
add 添加
ALTER TABLE 表名 ADD 字段名 字段类型 【FIRST|AFTER 字段名】;
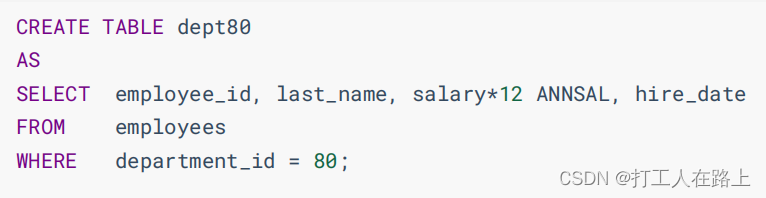
ALTER TABLE dept80 ADD job_id varchar(15);
modify 修改
ALTER TABLE 表名 MODIFY 字段名 字段类型 【DEFAULT 默认值】【FIRST|AFTER 字段名 2】;
ALTER TABLE dept80 MODIFY last_name VARCHAR(30);
change 重命名
ALTER TABLE 表名 CHANGE 【column】 列名 新列名 新数据类型;
ALTER TABLE dept80 CHANGE department_name dept_name varchar(15);
ALTER TABLE dept80 DROP COLUMN job_id;
drop 删除
ALTER TABLE 表名 DROP 【COLUMN】字段名
ALTER TABLE dept80 DROP COLUMN job_id;
8.数据处理之增删改DML
insert into / update / delete 表名 values/set/
insert into 插入
INSERT INTO departments(可填写字段,与下面的数值一一对应)
VALUES (70, 'Pub', 100, 1700),(30, 'Ab', 22, 3333);
INSERT INTO emp2
SELECT * FROM employees
WHERE department_id = 90;
update 更新 set
UPDATE employees
SET department_id = 55
WHERE department_id = 110;
delete from 删除
DELETE FROM departments WHERE department_name = 'Finance';
使用INSERT同时插入多条记录时,MySQL会返回一些在执行单行插入时没有的额外信息
● Records:表明插入的记录条数。
● Duplicates:表明插入时被忽略的记录,原因可能是这些记录包含了重复的主键值。
● Warnings:表明有问题的数据值。
计算列【geberated always as 】:简单来说就是某一列的值是通过别的列计算得来的
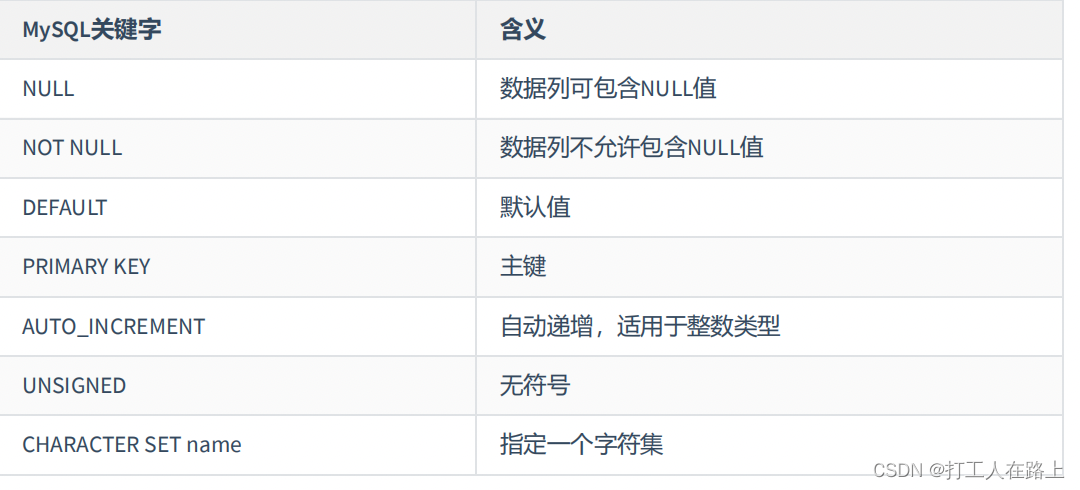
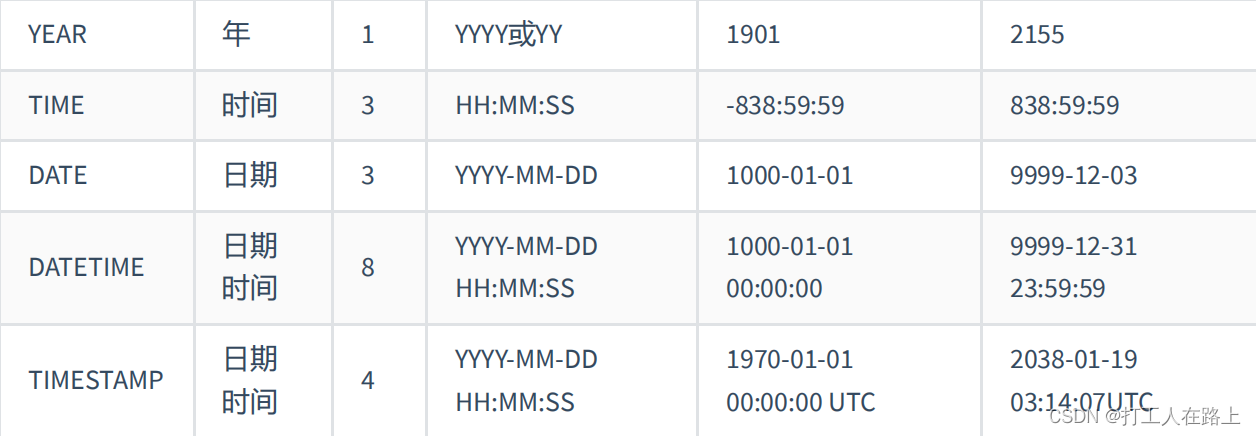
9.数据类型
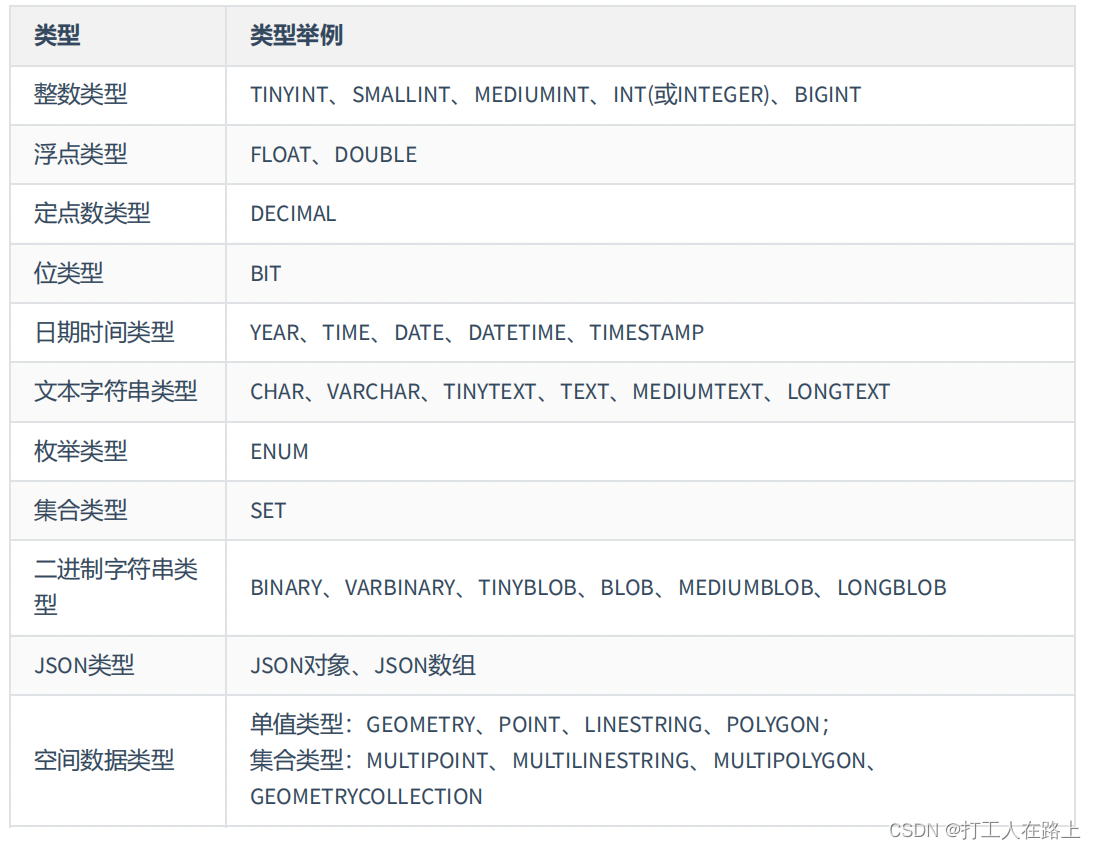
数值类型的属性

10.约束
约束是表级的强制规定。
可以在创建表时规定约束(通过 CREATE TABLE 语句),或者在表创建之后通过 ALTER TABLE 语句规定约束。

CREATE TABLE 表名称(
字段名 数据类型, unique
字段名 数据类型 NOT NULL default 默认值,
字段名 数据类型 primary key AUTO_INCREMENT,
constrint 约束名称 unique key(字段名1,字段名2)
);
ALTER TABLE 表名 DROP INDEX 约束名称;
alter table 表名称 modify 字段名 数据类型 not null; 添加非空约束
alter table 表名称 modify 字段名 数据类型; 删除非空约束
FOREIGN KEY 约束
FOREIGN KEY(从表的某个字段) references 主表名(被参考字段)
主表(父表):被引用的表,被参考的表
从表(子表):引用别人的表,参考别人的表

ALTER TABLE 从表名 ADD [CONSTRAINT 约束名]
FOREIGN KEY (从表的字段) REFERENCES 主表名(被引用 字段)
[on update xx][on delete xx]; xx是约束等级


create table dept(
did int primary key check(did>0), #部门编号
dname varchar(50) #部门名称
);
create table emp(
eid int primary key, #员工编号
ename varchar(5), #员工姓名
deptid int, #员工所在的部门
foreign key (deptid) references dept(did) on update cascade on delete set null
#把修改操作设置为级联修改等级,把删除操作设置为set null等级
);
删除外键约束

check,defulat 字段约束
alter table 表名称 modify 字段名 数据类型 default 默认值;

11.视图
常见的数据库对象

▷视图是一种 虚拟表 ,本身是 不具有数据 的,占用很少的内存空间,它是 SQL 中的一个重要概念。
▷视图建立在已有表的基础上, 视图赖以建立的这些表称为基表。
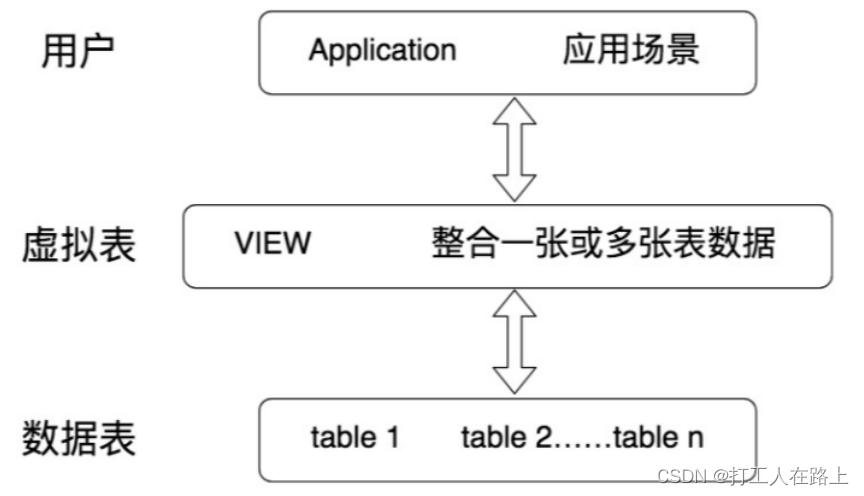
视图的创建和删除只影响视图本身,不影响对应的基表。但是当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化,反之亦然。
向视图提供数据内容的语句为 SELECT 语句, 可以将视图理解为存储起来的 SELECT 语句在数据库中,视图不会保存数据,数据真正保存在数据表中。当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化;

CREATE VIEW emp_year_salary (ename,year_salary)
AS SELECT ename,salary*12*(1+IFNULL(commission_pct,0)) FROM t_employee;
查看视图: show/desc tables;
修改视图:
方式1:使用CREATE OR REPLACE VIEW 子句修改视图
CREATE OR REPLACE VIEW empvu80
(id_number, name, sal, department_id)
AS
SELECT employee_id, first_name || ' ' || last_name, salary, department_id
FROM employees
WHERE department_id = 80;
方式2:ALTER VIEW
ALTER VIEW 视图名称 AS查询语句
**DROP VIEW IF EXISTS 视图名称;**删除视图只是删除视图的定义,并不会删除基表的数据。
视图的优点;
1. 操作简单
将经常使用的查询操作定义为视图,可以使开发人员不需要关心视图对应的数据表的结构、表与表之间的关联关系,也不需要关心数据表之间的业务逻辑和查询条件,而只需要简单地操作视图即可,极大简化了开发人员对数据库的操作。
2. 减少数据冗余
视图跟实际数据表不一样,它存储的是查询语句。所以,在使用的时候,我们要通过定义视图的查询语句来获取结果集。而视图本身不存储数据,不占用数据存储的资源,减少了数据冗余。
3. 数据安全
MySQL将用户对数据的 访问限制 在某些数据的结果集上,而这些数据的结果集可以使用视图来实现。用户不必直接查询或操作数据表。这也可以理解为视图具有 隔离性 。视图相当于在用户和实际的数据表之间加了一层虚拟表
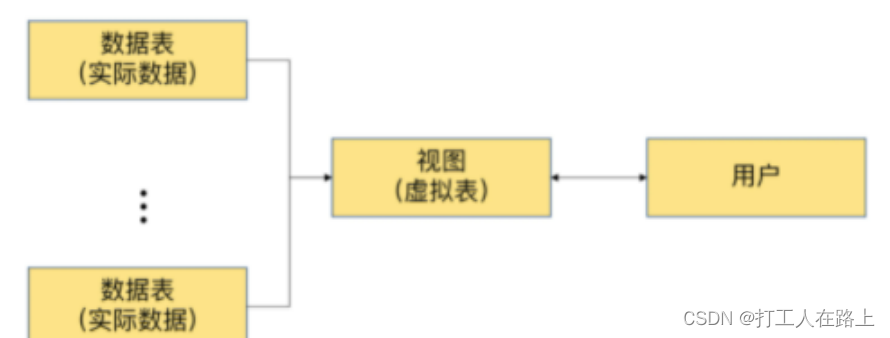
同时,MySQL可以根据权限将用户对数据的访问限制在某些视图上,用户不需要查询数据表,可以直接通过视图获取数据表中的信息。这在一定程度上保障了数据表中数据的安全性。
4. 适应灵活多变的需求 当业务系统的需求发生变化后,如果需要改动数据表的结构,则工作量相对较大,可以使用视图来减少改动的工作量。
5. 能够分解复杂的查询逻辑 数据库中如果存在复杂的查询逻辑,则可以将问题进行分解,创建多个视图获取数据,再将创建的多个视图结合起来,完成复杂的查询逻辑。
12.存储过程与函数
存储过程:Stored Procedure 就是一组经过 预先编译 的 SQL 语句的封装。
执行过程:存储过程预先存储在 MySQL 服务器上,需要执行的时候,客户端只需要向服务器端发出调用存储过程的命令,服务器端就可以把预先存储好的这一系列 SQL 语句全部执行。
存储过程的参数类型可以是IN、OUT和INOUT。
DELIMITER //
CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型,...)
[characteristics ...]
BEGIN
存储过程体
END //
DELIMITER ;
characteristics 表示创建存储过程时指定的对存储过程的约束条件,其取值信息如下:
LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'
举例
DELIMITER $
CREATE PROCEDURE select_all_data()
BEGIN
SELECT * FROM emps;
END $
DELIMITER ;


调用存储过程:call 存储过程名字(参数);
SET @name=值; CALL sp1(@name);
函数:FUNCTION中总是默认为IN参数
调用:SELECT 函数名(实参列表)
DELIMITER $ ,
CREATE FUNCTION 函数名(参数名 参数类型,...)
RETURNS 返回值类型
[characteristics ...]
BEGIN
函数体 #函数体中肯定有
RETURN 语句
END $
DELIMITER ;
DELIMITER //
CREATE FUNCTION email_by_id(emp_id INT)
RETURNS VARCHAR(25)
DETERMINISTIC
CONTAINS SQL BEGINRETURN (SELECT email FROM employees WHERE employee_id = emp_id); END // DELIMITER ;
如果没加修饰的字段【characteristics】会报错
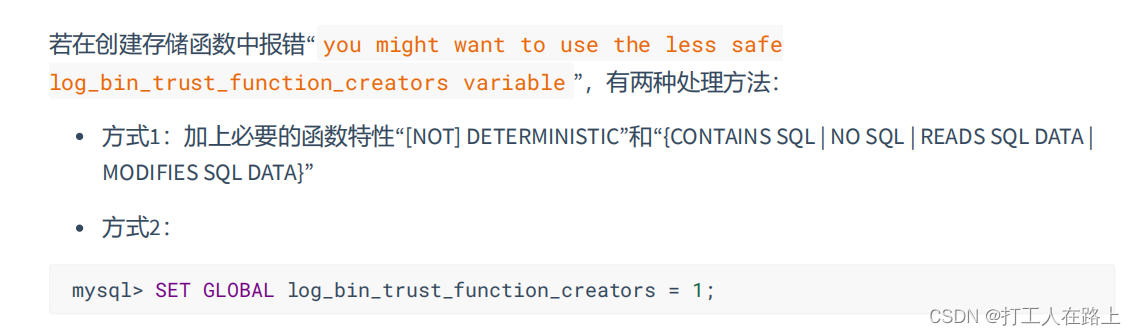

修改 删除 和table表操作差不多 改成 proceduer/function
13.变量,流程控制与游标
变量分为:系统变量和用户自定变量
系统变量分为全局系统变量(需要添加 global 关键字)以及会话系统变量(需要添加 session 关键字),有时也把全局系统变量简称为全局变量,有时也把会话系统变量称为local变量。如果不写,默认会话级别。
静态变量(在 MySQL 服务实例运行期间它们的值不能使用 set 动态修改)属于特殊的全局系统变量。
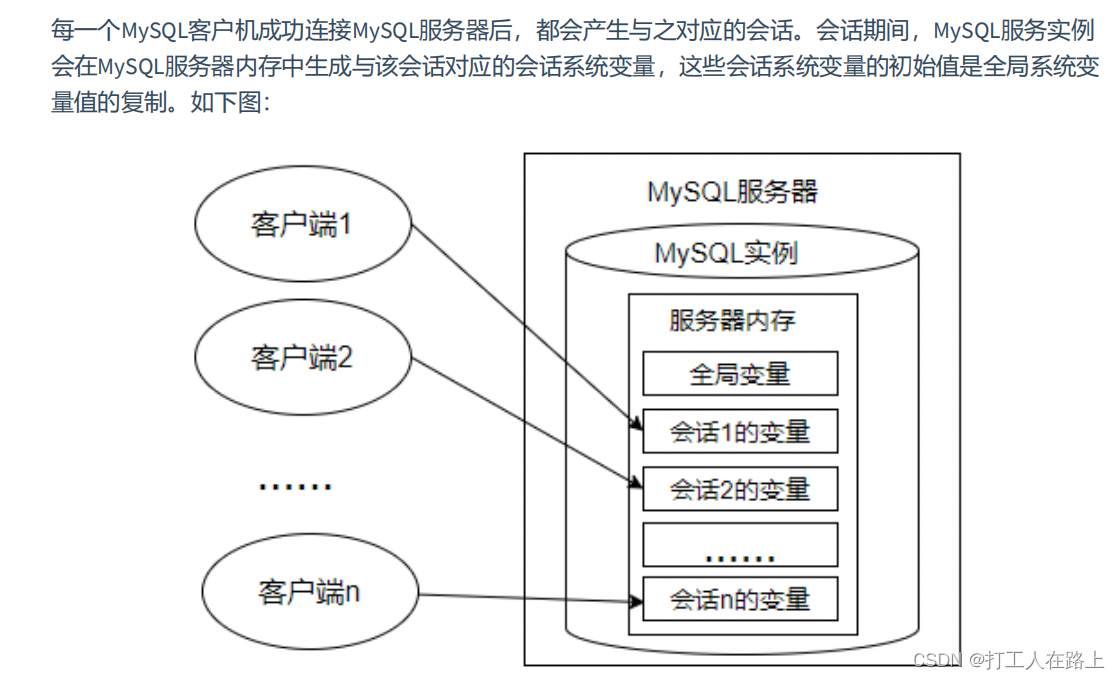
为某个系统变量赋值
#方式1:
SET @@global.变量名=变量值;
SET GLOBAL 变量名=变量值;
#为某个会话变量赋值
#方式1:
SET @@session.变量名=变量值;
#方式2:
SET SESSION 变量名=变量值;
用户变量:一般是会话变量@
#方式1:“=”或“:=”
SET @用户变量 = 值; SET @用户变量 := 值;
#方式2:“:=” 或 INTO关键字
SELECT @用户变量 := 表达式 [FROM 等子句];
SELECT 表达式 INTO @用户变量 [FROM 等子句];
局部变量:可以使用 DECLARE 语句定义一个局部变量,仅仅在定义它的 BEGIN … END 中有效
BEGIN
#声明局部变量
DECLARE 变量名1 变量数据类型 [DEFAULT 变量默认值];
DECLARE 变量名2,变量名3,... 变量数据类型 [DEFAULT 变量默认值];
#为局部变量赋值
SET 变量名1 = 值;
SELECT 值 INTO 变量名2 [FROM 子句]; #查看局部变量的值
SELECT 变量1,变量2,变量3;
END

定义处理错误的程序
定义条件 是事先定义程序执行过程中可能遇到的问题
处理程序 定义了在遇到问题时应当采取的处理方式,并且保证存储过程或函数在遇到警告或错误时能继续执行。这样可以增强存储程序处理问题的能力,避免程序异常停止运行。
说明:定义条件和处理程序在存储过程、存储函数中都是支持的。
定义条件:给MySQL中的错误码命名,这有助于存储的程序代码更清晰。它将一个 错误名字 和 指定的 错误条件 关联起来。这个名字可以随后被用在定义处理程序的 DECLARE HANDLER 语句中。
DECLARE 错误名称 condition FOR 错误码(或错误条件)

处理错误类型
DECLARE 处理方式 handler FOR 错误类型 处理语句

#方法1:捕获sqlstate_value
DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02' SET @info = 'NO_SUCH_TABLE';
#方法2:捕获mysql_error_value
DECLARE CONTINUE HANDLER FOR 1146 SET @info = 'NO_SUCH_TABLE';
#方法3:先定义条件,再调用 DECLARE no_such_table CONDITION FOR 1146;
DECLARE CONTINUE HANDLER FOR NO_SUCH_TABLE SET @info = 'NO_SUCH_TABLE';
#方法4:使用SQLWARNING
DECLARE EXIT HANDLER FOR SQLWARNING SET @info = 'ERROR';
#方法5:使用NOT FOUND
DECLARE EXIT HANDLER FOR NOT FOUND SET @info = 'NO_SUCH_TABLE';
#方法6:使用SQLEXCEPTION
DECLARE EXIT HANDLER FOR SQLEXCEPTION SET @info = 'ERROR';
流程控制
IF 表达式1 THEN 操作1
ELSEIF 表达式2 THEN 操作2
……
ELSE 操作N
END IF

case when then

循环:loop===》使用levae语句结束循环
DECLARE id INT DEFAULT 0;
add_loop:LOOP
SET id = id +1;
IF id >= 10 THEN LEAVE add_loop;
END IF;
END LOOP add_loop;

循环while
WHILE 循环条件 DO
循环体
END WHILE [while_label];
循环结构之REPEAT until
REPEAT
SET i = i + 1;
until i >= 10
END REPEAT;
leav label 【等同于break】
ITERATE label【等同于continue】
游标的使用
游标,让我们能够对结果集中的每一条记录进行定位,并对指向的记录中的数据进行操作的数据结构。游标让 SQL 这种面向集合的语言有了面向过程开发的能力。
在 SQL 中,游标是一种临时的数据库对象,可以指向存储在数据库表中的数据行指针。这里游标充当了 指针的作用 ,我们可以通过操作游标来对数据行进行操作。
第一步:声明游标 declare xxx cursor for 查询语句
declare 游标名 cursor for 查询语句;
第二步:打开游标 open xxx
第三步,使用游标
fetch 游标名称 INTO emp_id, emp_sal ;
这个游标来读取当前行,并且将数据保存到 var_name 这个变量中,游标指针指到下一行。
第四步,关闭游标 close cursor_name

14.触发器
触发器是由 事件来触发 某个操作,这些事件包括 INSERT 、 UPDATE 、 DELETE 事件。所谓事件就是指用户的动作或者触发某项行为。如果定义了触发程序,当数据库执行这些语句时候,就相当于事件发生了,就会 自动 激发触发器执行相应的操作。
当对数据表中的数据执行插入、更新和删除操作,需要自动执行一些数据库逻辑时,可以使用触发器来实现。
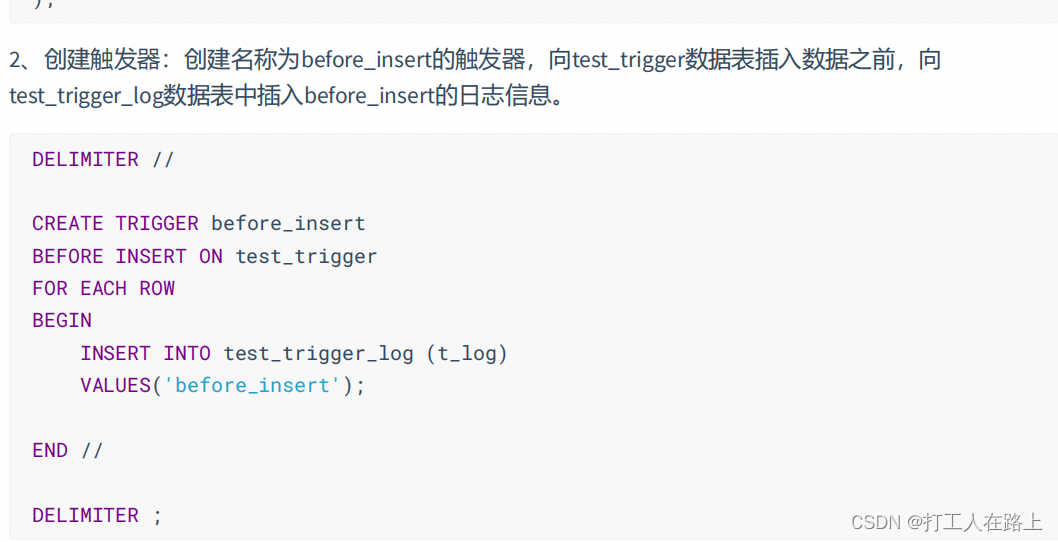
CREATE TRIGGER 触发器名称
{BEFORE|AFTER} {INSERT|UPDATE|DELETE} ON 表名
FOR EACH ROW
触发器执行的语句块;
DROP TRIGGER IF EXISTS 触发器名称;
表名 :表示触发器监控的对象。
BEFORE|AFTER :表示触发的时间。BEFORE 表示在事件之前触发; AFTER表示在事件之后触发。
INSERT|UPDATE|DELETE :表示触发的事件。 INSERT 表示插入记录时触发; UPDATE表示更新记录时触发; DELETE 表示删除记录时触发。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









