






Elasticsearch作为常用的中间件,在搜索方面是极其高效的,本文在于帮助大家快速学习与复习es基础,怎么操作,为什么高效,与mysql的区别等等
采用倒排索引
-
传统数据库是正向索引:
- 在查非索引字段是逐行扫描(效率低)
- 查索引字段直接找到(效率高)
-
倒排索引包括:
- 文档: 每条数据就是一个文档
- 词条: 文档按照语义分成的词语
比如 我要对标题进行倒排索引,将标题分为多个词条,每个词条对应多个文档id
词条不重复,为词条创建索引,数据少可用哈希法,多用b+树
搜多个词条,取出来是id交集,并集等(看需求)
es与mysql的差别
差别1:
- es存储数据是用json来存储的
差别2:
- es的多维度索引: 相同类型的文档的集合
- es的映射: 索引中文档的字段约束信息,类似表的结构约束
差别3:
- Mysql: 擅长事务型操作,可以确保数据的安全和一致性
- Elasticsearch: 擅长海量数据的搜索,分析,计算,可达千万级。
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是Elasticsearch提供的JSON风格的请求语句,用来操作Elasticsearch,实现CRUD |
通过kibana初步使用es
kibana作为操作es的图形化工具,两个要相互通信才行
- 初步:
GET _search { "query": { "match_all": {} } } 等价于GET / ,就是在url对应的请求方式-
GET _search:这是一个 HTTP GET 请求,用于执行搜索操作。_search是一个端点,允许用户对一个或多个索引执行查询。 -
"query":这是 JSON 请求体的一部分,包含了实际的查询定义。在这个例子中,我们只定义了一个简单的查询部分。 -
"match_all": {}:这是查询语句本身,表示匹配所有的文档,即不应用任何过滤条件。空对象{}表示没有额外的参数。
-
IK分词器
Elasticsearch在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好。
我们在Kibana的DevTools中测试:
POST /_analyze
{
"analyzer": "standard",
"text": "宁猫学java!"
}
语法说明:
- POST:请求方式
/_analyze:请求路径,这里省略了http://192.168.150.101:9200,有Kibana帮我们补充
- 请求参数,json风格:
- analyzer:分词器类型,这里是默认的standard分词器
- text:要分词的内容
可以发现他分的不友好,处理中文分词,一般使用IK分词器
包含两种模式:
- ik_smmart:最少切分
- ik_max_word:最细切分
最少切分(效率)
- 分的少,比如程序员切分为程序员
最细切分(准度) - 分的会更多,比如程序员分别切分,程序,员,程序员
底层都是基于词库来进行分词的
我们可以扩展和停用词库
- 在ik分词器目录中的config目录中的Analyzer.cfg.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!-- 用户可以在这里配置自己的扩展字典 *** 添加扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!-- 用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典 -->
<entry key="ext_stopwords">stopword.dic</entry>
</properties>
- 确保在配置文件指定的目录下创建相应的词典文件(如
ext.dic或stopword.dic),并在其中添加你需要的词汇。
操作索引库
mapping:
- 对索引库文档的约束
-
type: 字段的数据类型,常见的简单类型有:
- 字符串:
text: 可分词的文本(例如:品牌、国家、IP 地址)keyword: 精确值(例如:品牌、国家、IP 地址)
- 数值:
longintegershortbytedoublefloat
- 日期:
date
- 布尔:
boolean
- 对象:
object
- 注意他是没有数组类型但允许一个字段存多个数,如【flase,true】,【1,2,1】
- 字符串:
-
index: 是否创建(倒排)索引,默认为true
-
analyzer: 使用那种分词器
-
properties: 用于定义
object类型字段的子字段
创建索引库:
- 通过Restful请求操作索引库,文档。内容用DSL语句表示
- 模板
PUT /索引库名称 { "mappings": { "properties": { "字段名": { "type": "text", "analyzer": "ik_smart" }, "字段名2": { "type": "keyword", "index": "false" }, "字段名3": { "properties": { "子字段": { "type": "keyword" } } } } } } - 示例
PUT /book { "mappings" : { "properties" : { "id" : { "type" : "long" }, "authorId" : { "type" : "long" }, "authorName" : { "type" : "text", "analyzer": "ik_smart" }, "bookName" : { "type" : "text", "analyzer": "ik_smart" }, "bookDesc" : { "type" : "text", "analyzer": "ik_smart" }, "bookStatus" : { "type" : "short" }, "categoryId" : { "type" : "integer" }, "categoryName" : { "type" : "text", "analyzer": "ik_smart" }, "lastChapterId" : { "type" : "long" }, "lastChapterName" : { "type" : "text", "analyzer": "ik_smart" }, "lastChapterUpdateTime" : { "type": "long" }, "picUrl" : { "type" : "keyword", "index" : false, "doc_values" : false }, "score" : { "type" : "integer" }, "wordCount" : { "type" : "integer" }, "workDirection" : { "type" : "short" }, "visitCount" : { "type": "long" } } } }
其他curd:
修改:
- 索引库和mapping一旦创建无法修改,但可以添加型的字段
- 模板
PUT /索引库名/_mapping { "properties": { "新字段名": { "type": "integer" } } }
查询:
GET /heima
删除:
DELETE /heima
文档操作
新增:
- 模板
POST /索引库名/_doc/文档id { "字段1": "值1", "字段2": "值2", "字段3": { "子属性1": "值3", "子属性2": "值4" } } - 示例
POST /heima/_doc/1 { "info": "黑马程序员Java讲师", "email": "zy@itcast.cn", "name": { "firstName": "云", "lastName": "赵" } } - 文档id要自己指定,不然会随机生成
查询:
GET /heima/_doc/id
删除:
DELETE /heima/_doc/id
修改:
- 全量修改,会删除旧文档,添加新文档
PUT /索引库名/_doc/文档id { "字段1":"值1", "字段2":"值2", //…… } //既能做修改,还能替代新增
2.增量修改
PUT/索引库名/_update/文档id { "doc":{ "字段名":新的值 } }
DSL查询
es提供了基于JSON的DSL来定义查询
-
查询所有:查询出所有数据,一般测试用。例如:
match_all
默认显示10条GET /索引库名/_search { "query":{ "match_all" } } -
全文检索( f u l l t e x t full text fulltext)查询:利用分词器对用户输入内容分词,然后去倒排序引库中匹配。例如:
match_querymulti_match_queryGET /索引库名/_search { "query":{ "match":{ //"FIELD":"TEXT" //"all":"TEXT"(结果是全部) //"all":"华为手机"(分词,包括多靠前) } } } GET /索引库名/_search { "query": { "multi_match": { "query": "华为手机", "fields": ["title", "content", "description"], "type": "best_fields", // 或者 "most_fields", "cross_fields" 等,取决于你的需求 "operator": "AND" // 默认是 OR,这里设置为 AND 表示所有词都必须匹配 } } }
-
精确查询:根据精确词条值查找数据,不会分词,一般是查找 k e y w o r d keyword keyword、数值、日期、 b o o l e a n boolean boolean等类型字段。例如:
-
i
d
s
ids
ids
GET /索引库名/_search { "query": { "ids": { "values": ["1", "2"] } } } -
r
a
n
g
e
range
range
GET /索引库名/_search { "query": { "range": { "date": { "gte": "2024-01-01", "lte": "2024-12-31" "format":"yyyy-MM-dd" } } } } -
t
e
r
m
term
term(精确匹配词条)
GET /索引库名/_search { "query": { "term": { "status": true } } }
-
i
d
s
ids
ids
-
地理(geo)查询:根据经纬度查询。例如:
geo_distanceGET /索引库名/_search { "query": { "geo_distance": { "distance": "10km", "location": { "lat": 40.73, "lon": -74.1 } } } }geo_bounding_boxGET /索引库名/_search { "query": { "geo_bounding_box": { "location": { "top_left": { "lat": 40.77, "lon": -73.95 }, "bottom_right": { "lat": 40.71, "lon": -74.00 } } } } }
-
复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
-
b
o
o
l
bool
bool
must:所有在这个子句中的查询条件都必须满足。等价于逻辑“AND”。should:这个子句中的查询条件至少有一个要满足。可以设置minimum_should_match参数来指定最少需要匹配多少个should子句。等价于逻辑“OR”。must_not:这个子句中的查询条件都不应满足。用于排除某些条件,不参与算分。filter:这个子句中的查询条件也必须满足,但与must不同的是,它不会影响评分(即不计算相关性得分)。这可以提高性能,因为不需要计算评分。
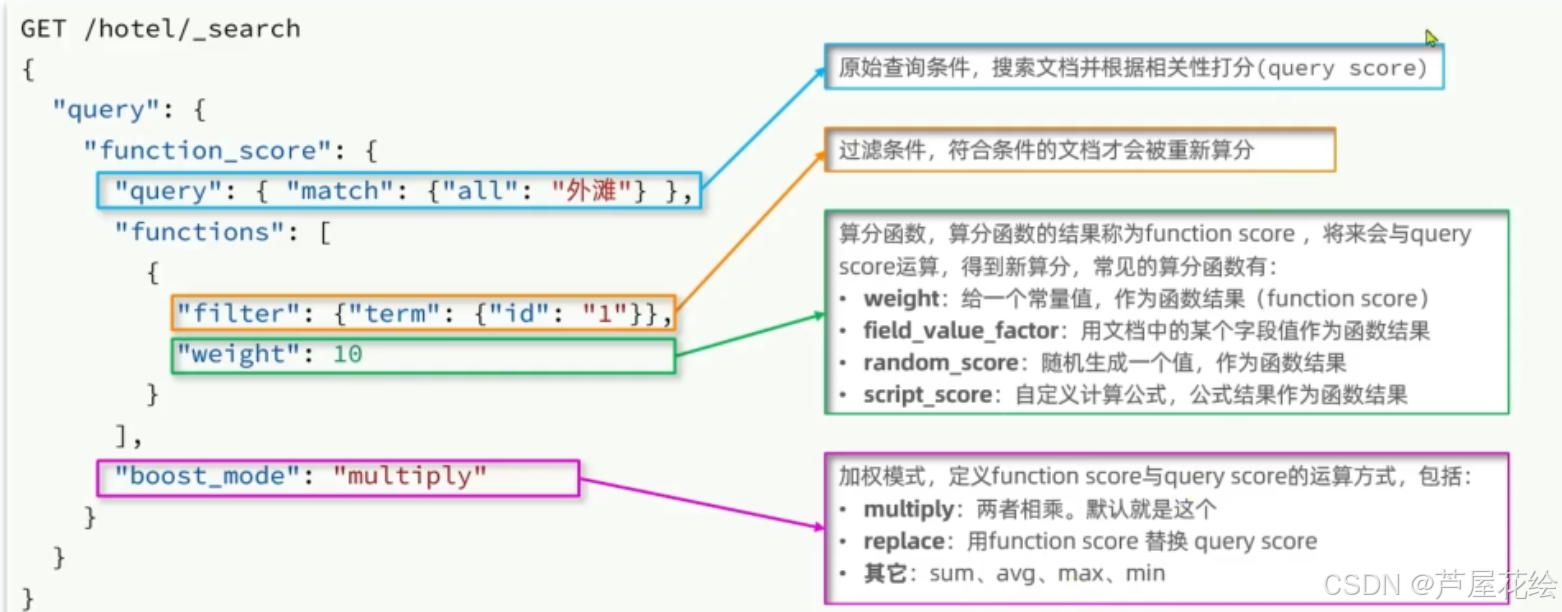
GET /索引库名/_search { "query": { "bool": { "must": [ { "term": { "category": "electronics" } }, { "range": { "price": { "gte": 100, "lte": 500 } } } ], "filter": [ { "term": { "in_stock": true } } ] } } } function_score控制相关性得分weight:直接给定一个固定的权重值。random_score:为每个文档分配一个随机分数。field_value_factor:根据文档中某个字段的值来调整得分。decay_function:随着距离某个中心点(如时间、地理位置)的距离增加而减少得分。script_score:使用自定义脚本来计算得分。
-
b
o
o
l
bool
bool
boost_mode加权模式,定义function score和query score的运算方式,multipy,两者相乘(默认)
初始计分
TF算法
T
F
(
词条频率
)
=
词条出现次数
文档中词条总数
TF(词条频率) = \frac{词条出现次数}{文档中词条总数}
TF(词条频率)=文档中词条总数词条出现次数
可能导致一些常见词汇(如“的”、“是”等)获得较高的分数,即使它们对于文档的主题贡献不大。
后面改为
TF——IDF算法
逆文档频率 (IDF):衡量词条在整个语料库中的普遍重要性。一个词条越不常见,它的IDF值越高。
IDF
(
t
)
=
log
(
总文档数
+
1
包含词条
t
的文档数
+
1
)
+
1
\text{IDF}(t) = \log\left(\frac{\text{总文档数} + 1}{\text{包含词条 } t \text{ 的文档数} + 1}\right) + 1
IDF(t)=log(包含词条 t 的文档数+1总文档数+1)+1
这里的 “+1” 是为了避免分母为零的情况,并且保证所有IDF值都是正数。
TF-IDF
(
t
,
d
)
=
TF
(
t
,
d
)
×
IDF
(
t
)
\text{TF-IDF}(t, d) = \text{TF}(t, d) \times \text{IDF}(t)
TF-IDF(t,d)=TF(t,d)×IDF(t)
现在用的是
BM25
BM25
(
q
,
d
)
=
∑
i
=
1
n
I
D
F
(
q
i
)
⋅
(
k
1
+
1
)
⋅
T
F
(
q
i
,
d
)
T
F
(
q
i
,
d
)
+
k
1
⋅
(
1
−
b
+
b
⋅
∣
d
∣
avgdl
)
\text{BM25}(q, d) = \sum_{i=1}^{n} IDF(q_i) \cdot \frac{(k_1 + 1) \cdot TF(q_i, d)}{TF(q_i, d) + k_1 \cdot (1 - b + b \cdot \frac{|d|}{\text{avgdl}})}
BM25(q,d)=∑i=1nIDF(qi)⋅TF(qi,d)+k1⋅(1−b+b⋅avgdl∣d∣)(k1+1)⋅TF(qi,d)
其中:
- q q q 表示查询, d d d 表示文档。
- q i q_i qi 是查询 q q q 中的第 i i i 个词条。
- n n n 是查询中的词条数量。
- I D F ( q i ) IDF(q_i) IDF(qi) 是词条 q i q_i qi 的逆文档频率,用于衡量词条的重要性。
- T F ( q i , d ) TF(q_i, d) TF(qi,d) 是词条 q i q_i qi 在文档 d d d 中的词频。
- |d| 是文档 d d d 的长度(以词条数计)。
- avgdl \text{avgdl} avgdl 是语料库中文档的平均长度。
-
k
1
k_1
k1 和
b
b
b 是两个可调参数,通常
k
1
k_1
k1 取值范围为
[1.2, 2.0], b b b 取值为 0.75 左右。
搜索结果处理
定义排序
可以不按照_score排序,可排序字段有:keyword类型,数值类型,地理坐标类型,日期类型
GET /hotels/_search
{
"query": {
"match_all": {}
},
"sort": [
{ "price": "asc" }
]
}
GET /hotels/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"location": "31.040699,121.618075", // 用户的位置
"order": "asc",
"unit": "km"
}
}
]
}
分页处理
通过修改 from 和 size 参数来控制
-
默认值:
- f r o m = 0 from=0 from=0
- s i z e = 10 size=10 size=10
-
工作原理:分页是先查出 1 到 f r o m + s i z e from+size from+size 的结果,然后截取从 f r o m from from 开始的 s i z e size size 条记录。
-
深度分页问题:由于ES是分布式的,查询时每个分片会先查找 1 1 1 到 f r o m + s i z e from+size from+size 的数据,再进行排序和截取。如果 f r o m + s i z e from+size from+size 过大,会导致内存和CPU消耗增加,因此ES设定了结果集查询的上限为 10000 10000 10000。
深度分页解决方案
- Scroll API
- 适用场景:适合一次性拉取大量数据。
- 工作原理:存储查询状态,允许逐步获取大批量数据而不必重复扫描前几页的数据。
- 优点:避免了深度分页带来的性能问题。
- 缺点:返回的结果无序,需要额外处理以保持顺序,消耗内存,数据不能实时更新。
- Search After(推荐)
- 适用场景:适合按顺序逐页读取数据。
- 工作原理:基于游标(上一页最后一个文档的排序字段值)进行分页,避免使用
from和size参数。 - 优点:减少结果集,减少了内存使用,优化了性能。
- 缺点:不能跳页查询,必须依次获取每一页。
高亮处理
高亮:将搜索关键字突显出来
- 后端将搜索结果中的关键字用标签标记
- 前端去给标签加css样式
GET /_search
{
"query": {
"match": {
"content": "搜索关键字"
}
},
"highlight": {
"fields": {
"content": {
"pre_tags" : ["<em class='highlight'>"],
"post_tags" : ["</em>"]
}
}
}
}
em也是默认的
em.highlight {
background-color: #ffffcc; /* 浅黄色背景 */
font-weight: bold; /* 加粗字体 */
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









