







目录
VersionedCollapsingMergeTree表引擎
概述
MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。这种数据片段往复合并的特点,也正是合并树名称的由来。
MergeTree表引擎
表引擎特点
MergeTree作为家族系列最基础的表引擎,主要有以下特点:
- 存储的数据按主键排序。
- 这使得你能够创建一个小型的稀疏索引来加快数据检索。
- 支持数据分区,如果指定了 分区键 的话。
- 在相同数据集和相同结果集的情况下 ClickHouse 中某些带分区的操作会比普通操作更快。查询中指定了分区键时 ClickHouse 会自动截取分区数据。这也有效增加了查询性能。
- 支持数据副本。
- ReplicatedMergeTree 系列的表提供了数据副本功能。更多信息,请参阅 数据副本 一节。
- 支持数据采样,需要的话,你可以给表设置一个采样方法。
建表语句
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],...INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2) ENGINE = MergeTree()ORDER BY expr[PARTITION BY expr][PRIMARY KEY expr][SAMPLE BY expr][TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...][SETTINGS name=value, ...]
建表参数描述
- db: 指定数据库名称,如果当前语句没有包含‘db’,则默认使用当前选择的数据库为‘db’。
- cluster: 指定集群名称,目前固定为default。ON CLUSTER 将在每一个节点上都创建一个本地表。
- type: 该列数据类型,例如 UInt32。
- DEFAULT: 该列缺省值。如果INSERT中不包含指定的列,那么将通过表达式计算它的默认值并填充它。
- MATERIALIZED: 物化列表达式,表示该列不能被INSERT,是被计算出来的;在INSERT语句中,不需要写入该列;在SELECT *查询语句结果集不包含该列。
- ALIAS: 别名列。这样的列不会存储在表中。它的值不能够通过INSERT写入,同时使用SELECT查询星号时,这些列也不会被用来替换星号。但是它们可以用于SELECT中,在这种情况下,在查询分析中别名将被替换。
- 物化列与别名列的区别:物化列是会保存数据,查询的时候不需要计算,而表达式列不会保存数据,查询的时候需要计算,查询时候返回表达式的计算结果
- ENGINE: 引擎名和参数。ENGINE = MergeTree()。MergeTree 引擎没有参数。
- ORDER BY: 排序键。
- 可以是一组列的元组或任意的表达式。例如: ORDER BY (CounterID, EventDate) 。
- 如果没有使用 PRIMARY KEY 显式的指定主键,ClickHouse 会使用排序键作为主键。
- 如果不需要排序,可以使用 ORDER BY tuple(). 参考 选择主键
- PARTITION BY: 分区键 。
- 要按月分区,可以使用表达式 toYYYYMM(date_column) ,这里的 date_column 是一个 Date 类型的列。分区名的格式会是 "YYYYMM" 。
- PRIMARY KEY: 主键,如果要 选择与排序键不同的主键,可选。
- 默认情况下主键跟排序键(由 ORDER BY 子句指定)相同。
- 因此,大部分情况下不需要再专门指定一个 PRIMARY KEY 子句。
- SAMPLE BY: 用于抽样的表达式。
- 如果要用抽样表达式,主键中必须包含这个表达式。例如:
- SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID)) 。
- TTL: 指定行存储的持续时间并定义数据片段在硬盘和卷上的移动逻辑的规则列表,可选。
- 表达式中必须存在至少一个 Date 或 DateTime 类型的列,比如:
- TTL date + INTERVAl 1 DAY
- 规则的类型 DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'指定了当满足条件(到达指定时间)时所要执行的动作:移除过期的行,还是将数据片段(如果数据片段中的所有行都满足表达式的话)移动到指定的磁盘(TO DISK 'xxx') 或 卷(TO VOLUME 'xxx')。默认的规则是移除(DELETE)。可以在列表中指定多个规则,但最多只能有一个DELETE的规则。
- SETTINGS: 控制 MergeTree 行为的额外参数:
index_granularity — 索引粒度。索引中相邻的『标记』间的数据行数。默认值,8192 。参考数据存储。
index_granularity_bytes — 索引粒度,以字节为单位,默认值: 10Mb。如果想要仅按数据行数限制索引粒度, 请设置为0(不建议)。
enable_mixed_granularity_parts — 是否启用通过 index_granularity_bytes 控制索引粒度的大小。在19.11版本之前, 只有 index_granularity 配置能够用于限制索引粒度的大小。当从具有很大的行(几十上百兆字节)的表中查询数据时候,index_granularity_bytes 配置能够提升ClickHouse的性能。如果你的表里有很大的行,可以开启这项配置来提升SELECT 查询的性能。
use_minimalistic_part_header_in_zookeeper — 是否在 ZooKeeper 中启用最小的数据片段头 。如果设置了 use_minimalistic_part_header_in_zookeeper=1 ,ZooKeeper 会存储更少的数据。更多信息参考『服务配置参数』这章中的 设置描述 。
min_merge_bytes_to_use_direct_io — 使用直接 I/O 来操作磁盘的合并操作时要求的最小数据量。合并数据片段时,ClickHouse 会计算要被合并的所有数据的总存储空间。如果大小超过了 min_merge_bytes_to_use_direct_io 设置的字节数,则 ClickHouse 将使用直接 I/O 接口(O_DIRECT 选项)对磁盘读写。如果设置 min_merge_bytes_to_use_direct_io = 0 ,则会禁用直接 I/O。默认值:10 * 1024 * 1024 * 1024 字节。
merge_with_ttl_timeout — TTL合并频率的最小间隔时间,单位:秒。默认值: 86400 (1 天)。
write_final_mark — 是否启用在数据片段尾部写入最终索引标记。默认值: 1(不建议更改)。
merge_max_block_size — 在块中进行合并操作时的最大行数限制。默认值:8192
storage_policy — 存储策略。参见 使用具有多个块的设备进行数据存储.
min_bytes_for_wide_part,min_rows_for_wide_part 在数据片段中可以使用Wide格式进行存储的最小字节数/行数。你可以不设置、只设置一个,或全都设置。
举个例子说明
创建表语句
CREATE TABLE student_mt (id Int COMMENT 'ID号',sno String COMMENT '学号',name String COMMENT '学生姓名',sex String COMMENT '男,女',cno String COMMENT '课程',score Double COMMENT '分数')ENGINE = MergeTree()PARTITION BY cnoORDER BY sno;
插入语句
insert into student_mt values(1, '0001', 'Abel', '男', '数学', 99 );insert into student_mt values(2, '0002', 'Quella', '女', '语文', 99 );insert into student_mt values(3, '0002', 'Quella', '女', '数学', 90 );insert into student_mt values(4, '0003', 'Bill', '男', '英语', 99 );
查询语句
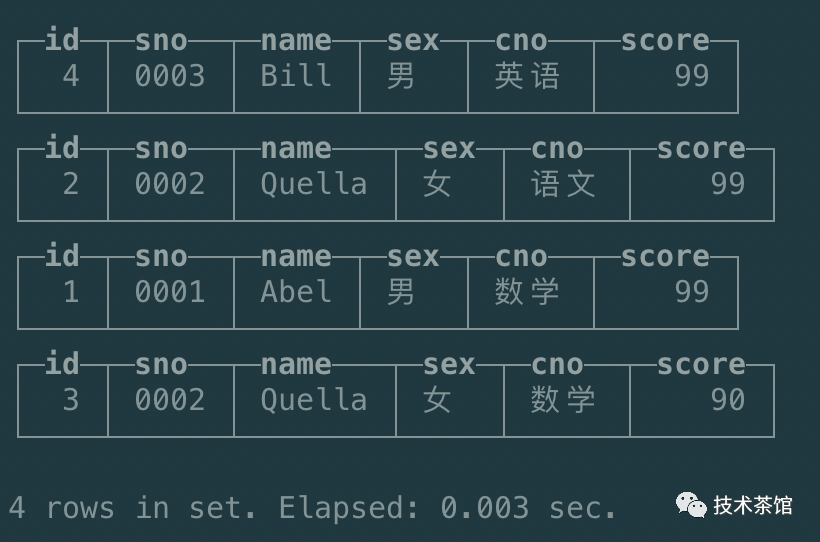
通过上面的执行结果可知,相同的(PARTITION KEY)没有合并在一起,目前有4个数据块。执行下面的命令。
optimize table student_mt;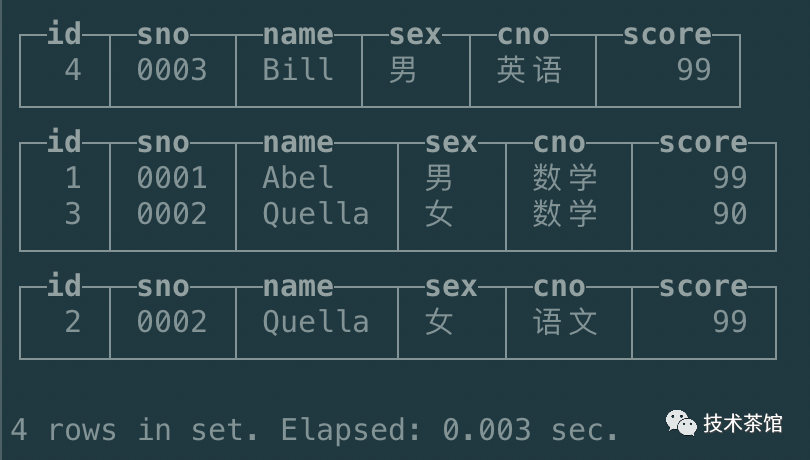
通过上图可知,我们其中(PARTITION KEY)相同的两个数据块合并到了一起。
ReplacingMergeTree表引擎
表引擎特点
该引擎和 MergeTree 的不同之处在于它会删除排序键值相同的重复项。
数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行,因此无法预先作出计划。有一些数据可能仍未被处理。尽管可以调用 OPTIMIZE 语句发起计划外的合并,但是尽量不要使用这个命令,因为 OPTIMIZE 语句会引发对数据的大量读写。
因此,ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
建表语句
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...) ENGINE = ReplacingMergeTree([ver])[PARTITION BY expr][ORDER BY expr][SAMPLE BY expr][SETTINGS name=value, ...]
建表参数描述
其他参数参考之前的MergeTree表,ReplacingMergeTree 的参数
ver — 版本列。类型为 UInt*, Date 或 DateTime。可选参数。
在数据合并的时候,ReplacingMergeTree 从所有具有相同排序键的行中选择一行留下:
- 如果 ver 列未指定,保留最后一条。
- 如果 ver 列已指定,保留 ver 值最大的版本。
需要注意的是,这里面说的是ReplacingMergeTree在数据合并的时候是依赖于相同排序键留一行,不是主键!!!
举个例子说明
创建表语句
CREATE TABLE student_rmt (id Int COMMENT 'ID号',sno String COMMENT '学号',name String COMMENT '学生姓名',sex String COMMENT '男,女',cno String COMMENT '课程',score Double COMMENT '分数')ENGINE = ReplacingMergeTree()PARTITION BY cnoORDER BY sno;
插入语句
insert into student_rmt values(1, '0001', 'Abel', '男', '数学', 99 );insert into student_rmt values(2, '0002', 'Quella', '女', '语文', 99 );insert into student_rmt values(3, '0002', 'Quella', '女', '数学', 90 );insert into student_rmt values(4, '0003', 'Bill', '男', '英语', 99 );insert into student_rmt values(5, '0003', 'Bill', '男', '英语', 90 );
查询语句

通过上面的执行结果可知,相同OrderBy Key(sno)没有合并。目前有5个数据块。执行下面的命令。
optimize table student_rmt;
再次查询表数据如下
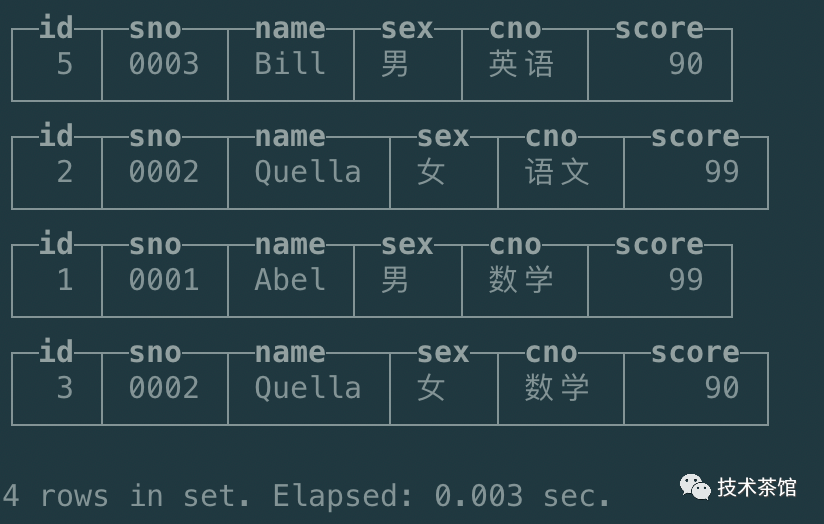
通过上图可知,我们其中OrderBy Key(sno)相同的,后面的数据把前面的数据替换了。
SummingMergeTree表引擎
表引擎特点
该引擎继承自 MergeTree。区别在于,当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度。
我们推荐将该引擎和 MergeTree 一起使用。例如,在准备做报表的时候,将完整的数据存储在 MergeTree 表中,并且使用 SummingMergeTree 来存储聚合数据。这种方法可以使你避免因为使用不正确的主键组合方式而丢失有价值的数据。
建表语句
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...) ENGINE = SummingMergeTree([columns])[PARTITION BY expr][ORDER BY expr][SAMPLE BY expr][SETTINGS name=value, ...]
建表参数描述
其他参数参考之前的MergeTree表,SummingMergeTree 的参数
columns 包含了将要被汇总的列的列名的元组。可选参数。所选的列必须是数值类型,并且不可位于主键中。
- 如果没有指定 `columns`,ClickHouse 会把所有不在主键中的数值类型的列都进行汇总。
举个例子说明
创建表语句
CREATE TABLE student_smt (id Int COMMENT 'ID号',sno String COMMENT '学号',name String COMMENT '学生姓名',sex String COMMENT '男,女',cno String COMMENT '课程',score Double COMMENT '分数',school String COMMENT '学校')ENGINE = SummingMergeTree(score)PARTITION BY schoolORDER BY (sno, name);
插入语句
insert into student_smt values(1, '0001', 'Abel', '男', '数学', 99, '北京大学');insert into student_smt values(2, '0002', 'Quella', '女', '语文', 99, '清华大学');insert into student_smt values(3, '0002', 'Quella', '女', '数学', 90, '清华大学' );insert into student_smt values(4, '0003', 'Bill', '男', '英语', 99, '北京大学');
查询语句

通过上面的执行结果可知,相同的OrderBy Key没有合并。目前有4个数据块。执行下面的命令。
optimize table student_smt;
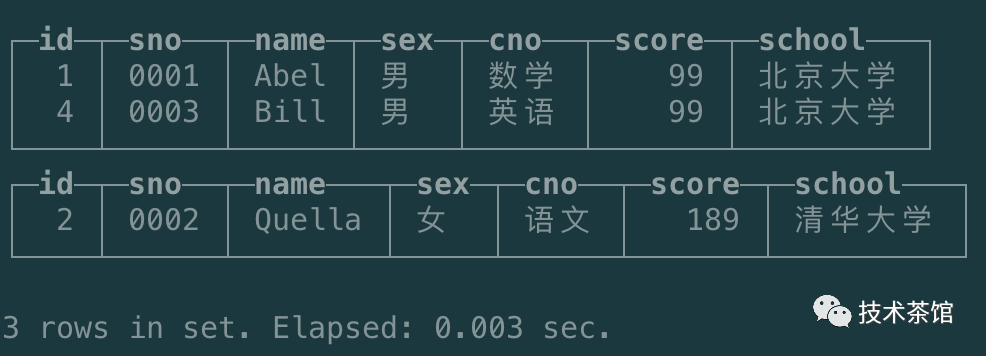
通过上图可知,我们其中OrderBy Key相同的,把score列的数据聚合在一起了。
AggregatingMergeTree表引擎
表引擎特点
该引擎继承自 MergeTree,并改变了数据片段的合并逻辑。 ClickHouse 会将一个数据片段内所有具有相同主键(准确的说是 排序键)的行替换成一行,这一行会存储一系列聚合函数的状态。
可以使用 AggregatingMergeTree 表来做增量数据的聚合统计,包括物化视图的数据聚合。
引擎使用以下类型来处理所有列:
- AggregateFunction
- SimpleAggregateFunction
AggregatingMergeTree 适用于能够按照一定的规则缩减行数的情况。
建表语句
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...) ENGINE = AggregatingMergeTree()[PARTITION BY expr][ORDER BY expr][SAMPLE BY expr][TTL expr][SETTINGS name=value, ...]
建表参数描述
无
举个例子说明
创建表语句
CREATE TABLE student_amt (id Int COMMENT 'ID号',sno String COMMENT '学号',name String COMMENT '学生姓名',sex String COMMENT '男,女',cno String COMMENT '课程',score AggregateFunction(sum, Double) COMMENT '分数',school String COMMENT '学校')ENGINE = AggregatingMergeTree()PARTITION BY schoolORDER BY (sno, name);
插入语句
insert into student_amt values(1, '0001', 'Abel', '男', '数学', 99, '北京大学');
如果按照上面的方式,插入数据则会报下面的错误。

所以AggregatingMergeTree这种表引擎只能支持Insert Select这句插入的语法,并且涉及到的聚合列需使用带有 -State- 聚合函数。如下所示
insert into student_amt select 1, '0001', 'Abel', '男', '数学', sumState(toFloat64(99)), '北京大学';insert into student_amt select 2, '0002', 'Quella', '女', '语文', sumState(toFloat64(99)), '清华大学';insert into student_amt select 3, '0002', 'Quella', '女', '数学', sumState(toFloat64(90)), '清华大学' ;insert into student_amt select 4, '0003', 'Bill', '男', '英语', sumState(toFloat64(99)), '北京大学';
查询语句

通过上面的执行结果可知,score列的结果都是乱码,并且也没有合并。这是因为AggregatingMergeTree这种表引擎查询数据时,则需要调用相应的-Merge函数。如下所示
select sno, name, sumMerge(score) from student_amt group by sno, name;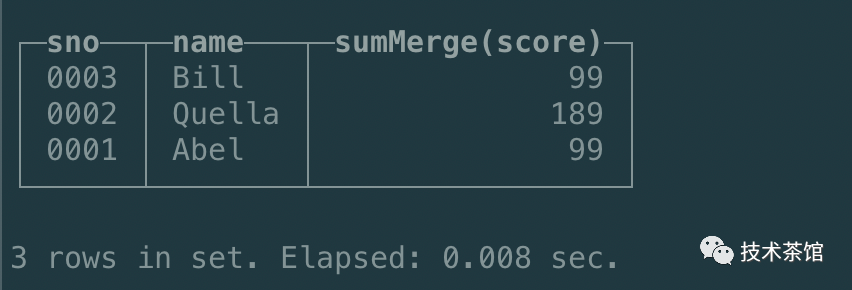
物化视图使用方式
创建MergeTree基础表
-- 创建一个MereTree引擎的学生表CREATE TABLE student_mt (id Int COMMENT 'ID号',sno String COMMENT '学号',name String COMMENT '学生姓名',sex String COMMENT '男,女',cno String COMMENT '课程',score Double COMMENT '分数',school String COMMENT '学校')ENGINE = MergeTree()PARTITION BY schoolORDER BY (sno, name);
创建物化视图
-- 创建一个物化视图CREATE MATERIALIZED VIEW materialized_view_student_amtENGINE = AggregatingMergeTree()PARTITION BY snoORDER BY (sno, name)AS SELECTsno, name, sumState(score) as ScoreFROM student_mtGROUP BY sno, name;
向基础表中插入数据
insert into student_mt values(1, '0001', 'Abel', '男', '数学', 99, '北京大学');insert into student_mt values(2, '0002', 'Quella', '女', '语文', 99, '清华大学');insert into student_mt values(3, '0002', 'Quella', '女', '数学', 90, '清华大学' );insert into student_mt values(4, '0003', 'Bill', '男', '英语', 99, '北京大学');
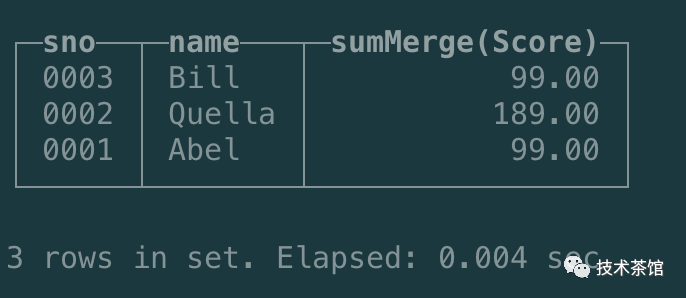
使用物化视图
SELECTsno,name,sumMerge(Score)FROM materialized_view_student_amtGROUP BYsno,name
GraphiteMergeTree表引擎
表引擎特点
该引擎用来对 Graphite数据进行瘦身及汇总。对于想使用CH来存储Graphite数据的开发者来说可能有用。
如果不需要对Graphite数据做汇总,那么可以使用任意的CH表引擎;但若需要,那就采用 GraphiteMergeTree 引擎。它能减少存储空间,同时能提高Graphite数据的查询效率。
建表语句
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](Path String,Time DateTime,Value <Numeric_type>,Version <Numeric_type>...) ENGINE = GraphiteMergeTree(config_section)[PARTITION BY expr][ORDER BY expr][SAMPLE BY expr][SETTINGS name=value, ...]
建表参数描述
含有Graphite数据集的表应该包含以下的数据列:
- 指标名称(Graphite sensor),数据类型:String
- 指标的时间度量,数据类型: DateTime
- 指标的值,数据类型:任意数值类型
- 指标的版本号,数据类型: 任意数值类型
以上列必须设置在汇总参数配置中。
这里需要注意的是
ClickHouse以最大的版本号保存行记录,若版本号相同,保留最后写入的数据。
GraphiteMergeTree 参数
- config_section - 配置文件中标识汇总规则的节点名称
举个例子说明
主要处理图数据的表引擎。还不知道杂用,就暂时不说明了。
CollapsingMergeTree表引擎
表引擎特点
该引擎继承于 MergeTree,并在数据块合并算法中添加了折叠行的逻辑。
CollapsingMergeTree 会异步的删除(折叠)这些除了特定列 Sign 有 1 和 -1 的值以外,其余所有字段的值都相等的成对的行。没有成对的行会被保留。
因此,该引擎可以显著的降低存储量并提高 SELECT 查询效率。
CollapsingMergeTree同样是以ORDER BY排序键作为判断数据唯一性的依据。
需要注意的是
CollapsingMergeTree对于写入数据的顺序有着严格要求,否则导致无法正常折叠。
如果数据的写入程序是单线程执行的,则能够较好地控制写入顺序;如果需要处理的数据量很大,数据的写入程序通常是多线程执行的,那么此时就不能保障数据的写入顺序了。在这种情况下,CollapsingMergeTree的工作机制就会出现问题。但是可以通过VersionedCollapsingMergeTree的表引擎得到解决。
建表语句
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...) ENGINE = CollapsingMergeTree(sign)[PARTITION BY expr][ORDER BY expr][SAMPLE BY expr][SETTINGS name=value, ...]
建表参数描述
CollapsingMergeTree 参数
- sign — 类型列的名称: 1 是«状态»行,-1 是«取消»行。
列数据类型 — Int8。
举个例子说明
创建表语句
CREATE TABLE student_cmt(`id` Int COMMENT 'ID号',`sno` String COMMENT '学号',`name` String COMMENT '学生姓名',`sex` String COMMENT '男,女',`cno` String COMMENT '课程',`score` Decimal32(2) COMMENT '分数',`school` String COMMENT '学校',`sign` Int8)ENGINE = CollapsingMergeTree(sign)PARTITION BY schoolORDER BY (sno, name)
插入语句
insert into student_cmt values(1, '0002', 'Quella', '女', '语文', 99, '清华大学', 1);--删除之前的数据(通过sign抵消了)insert into student_cmt values(2, '0002', 'Quella', '女', '数学', 90, '清华大学', -1 );--再次插入新的数据insert into student_cmt values(1, '0002', 'Quella', '女', '语文', 100, '清华大学', 1);
查询语句
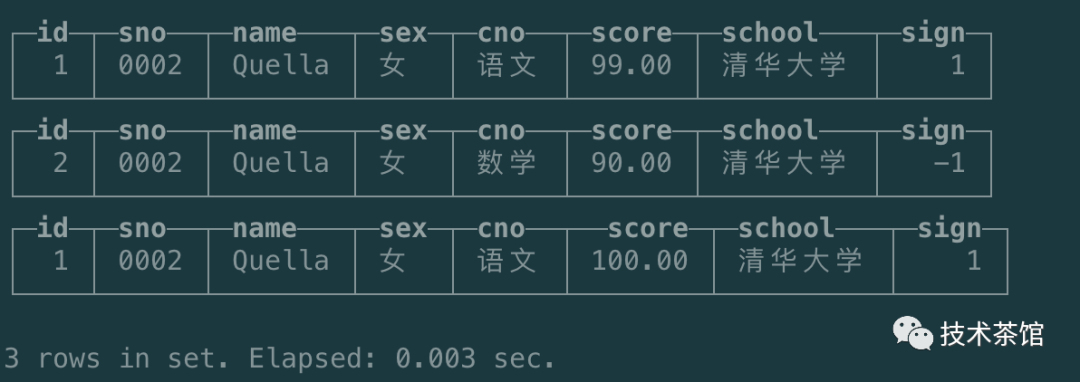
进行立即合并
optimize table student_cmt;
再次查询后的结果

VersionedCollapsingMergeTree表引擎
表引擎特点
这个引擎:
- 允许快速写入不断变化的对象状态。
- 删除后台中的旧对象状态。 这显着降低了存储体积。
引擎继承自 MergeTree 并将折叠行的逻辑添加到合并数据部分的算法中。 VersionedCollapsingMergeTree 用于相同的目的 折叠树 但使用不同的折叠算法,允许以多个线程的任何顺序插入数据。 特别是, Version 列有助于正确折叠行,即使它们以错误的顺序插入。 相比之下, CollapsingMergeTree 只允许严格连续插入。
建表语句
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...) ENGINE = VersionedCollapsingMergeTree(sign, version)[PARTITION BY expr][ORDER BY expr][SAMPLE BY expr][SETTINGS name=value, ...]
建表参数描述
VersionedCollapsingMergeTree(sign, version)
- sign — 指定行类型的列名: 1 是一个 “state” 行, -1 是一个 “cancel” 行
列数据类型应为 Int8. - version — 指定对象状态版本的列名。
列数据类型应为 UInt*.
举个例子说明
创建表语句
CREATE TABLE student_vcmt(`id` Int COMMENT 'ID号',`sno` String COMMENT '学号',`name` String COMMENT '学生姓名',`sex` String COMMENT '男,女',`cno` String COMMENT '课程',`score` Decimal32(2) COMMENT '分数',`school` String COMMENT '学校',`sign` Int8,`version` Int8)ENGINE = VersionedCollapsingMergeTree(sign, version)PARTITION BY schoolORDER BY (sno, name)
插入语句
--乱序插入数据insert into student_vcmt values(2, '0002', 'Quella', '女', '数学', 90, '清华大学', -1, 1);insert into student_vcmt values(1, '0002', 'Quella', '女', '语文', 99, '清华大学', 1, 1);--再次插入新的数据insert into student_vcmt values(1, '0002', 'Quella', '女', '语文', 100, '清华大学', 1, 2);
查询语句
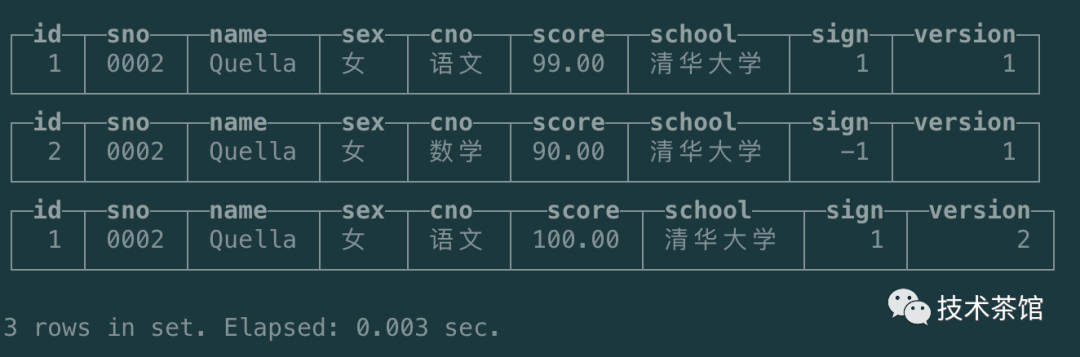
进行立即合并
optimize table student_vcmt;
再次查询后的结果

可见上面虽然在插入数据乱序的情况下,依然能够实现折叠的效果。之所以能够达到这种效果,是因为在定义version字段之后,VersionedCollapsingMergeTree会自动将version作为排序条件并增加到ORDER BY的末端,就上述的例子而言,最终的排序字段为ORDER BY sno, name,version desc。
结论
在ClickHouse的整个体系里面,MergeTree表引擎绝对是重中之重,总之非常重要。所以这个文章主要描述了,MergeTree系列相关表引擎的功能和特点,这些特点在不同的场景下为ClickHouse数据库提供非常好的性能。了解这些表引擎也能为我们后续分析源码或者更好的使用ClickHouse数据库做铺垫。
参考资料
- https://clickhouse.tech/docs/zh/

分享大数据行业的一些前沿技术和手撕一些开源库的源代码
微信公众号名称:技术茶馆
微信公众号ID : Night_ZW


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









