







目录
概述
基于代价的优化器引擎可能面临的问题和挑战如下。
- 从可选的单表扫描方式中,挑选什么样的单表扫描方式是最优的?
- 对于两个表连接时,如何连接是最优的?
- 对于多个表连接,连接顺序有多种组合,哪种连接顺序是最优的?
- 对于多个表连接,连接顺序有多种组合,是否要对每种组合都探索?如果不全部探索,怎么找到最优的一种组合?
那么碰到这些问题,我们如何解决呢,这里就引入了一个非常重要的功能叫做代价估算模型(Cost Model),我们用代价估算模型计算出各种情况下执行的代价,然后优化器选择一个代价最小的计划,来作为后续执行的计划。
代价估算模型能估算一个计划的代价大小,依赖一个非常重要的功能统计信息。那么我们先来了解下统计信息的基本概念。
统计信息
优化器统计信息是描述数据库中表和列的元数据信息的集合,它主要用来估计谓词的选择率和中间查询结果的大小,从而用于创建高质量的执行计划的基础。优化器统计信息主要包括行级别的统计信息和列级别的统计信息:
- 行级别的统计信息:包括行的总数、行的平均长度、表在磁盘中占用了多少page等。
- 列级别的统计信息:包括列的最大值、最小值、列中空值个数、列中非空值个数、不同值个数(Number of Distinct Value, 或NDV)和直方图等。
直方图与CBO的关系
从一个行源中评估返回行数所占的比例这就是选择率,选择率在CBO的查询优化中起着重要作用。选择率的取值范围是0到1之间。粗略的讲如果满足谓词条件的只有少量的行记录,那么CBO将更喜欢使用索引扫描,如果谓词条件要从表中获取大量数据那么CBO将更喜欢使用全表扫描。
比如下面的查询获取deptno等于10的所有雇员信息如果返回少量的记录查询将会更倾向于使用索引扫描:
SELECT*FROMempWHEREdeptno = 10;
为了评估选择率(或者换句话说计算出最优执行计划),CBO会使用各种形式的统计信息,配置参数等。以表中列的角度来说,CBO会收集以下统计信息:
- 列中不同值的数量也就是NDV
- 列中的最小值/最大值
- 列中null值的数量
- 数据分布或直方图信息
在没有直方图时,优化器使用基表中记录的列中不同值的数量,列中最小值/最大值和列中null值的数量来计算统计信息。使用这些信息优化器假设数据在列中的最小值和最大值之间是均匀分布的或者说列中每一个不同值的出现次数是相同的。
下面进行举例说明:
创建一个测试表histograms_test它有10000行记录, 表特征如下所示
- 有两个列
- 列uniqueVal包含不同值的范围从1到10000
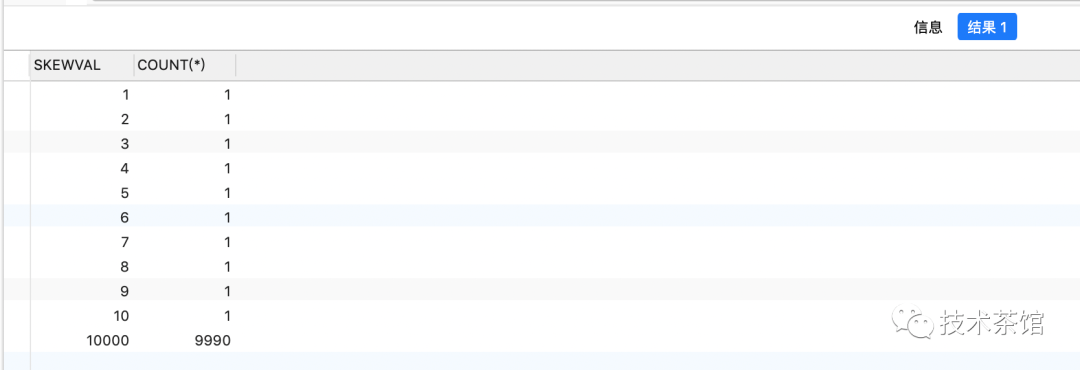
- 列skewVal对于前10行记录的值从1到10,余下的9990行记录都是10000
创建数据,数据分布如下所示
CREATE TABLE histograms_test AS SELECT ROWNUMuniqueVal,10000 skewValFROMdual CONNECT BY LEVEL < = 10000;UPDATE histograms_testSET skewVal = uniqueValWHEREROWNUM < = 10;SELECTskewVal,count( * )FROMhistograms_testGROUP BYskewValORDER BYskewVal;
现在来对表histograms_test收集统计信息但不创建直方图操作SQL如下所示
call dbms_stats.gather_table_stats ( USER, 'histograms_test', method_opt => 'for all columns size 1' );
查看是否收集统计信息成功
SELECT*FROMuser_tab_col_statisticsWHEREtable_name = upper( 'histograms_test' );

density列的数据分两种情况
- 如果没有直方图,列的density统计信息代表了它的选择率它是通过去时1/num_distinct=1/11=0.09090901来计算出来的。
- 在有直方图的情况下, density的计算依赖于直方图的类型和oracle的版本。
density值的范围是0到1之间。当查询使用这个列作谓词条件时优化器将会使用这个列的density统计信息来评估将要返回的行数。公式如下所示
cardinality(基数)=selectivity(选择率)* number of rows(表的行数)
下面来检查一下在谓词条件中列的数据分布存在倾斜而没有直方图的情况下其基数评估的情况:
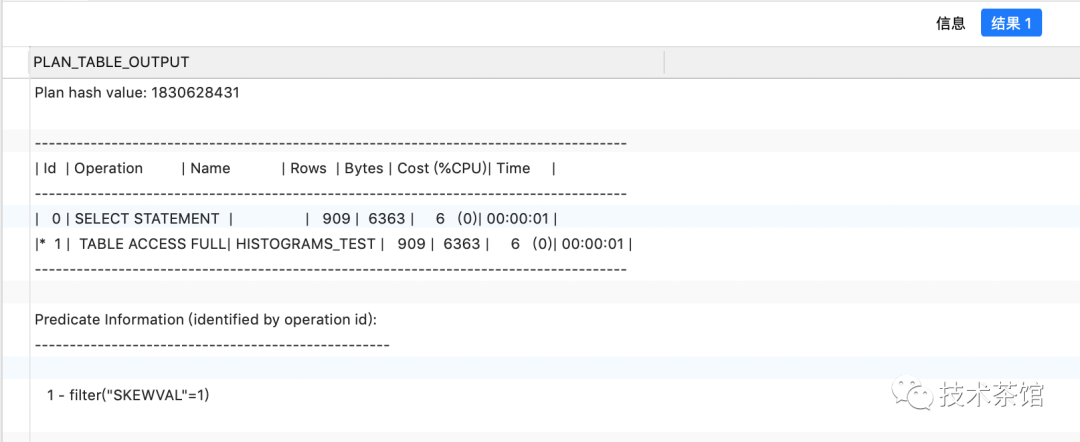
explain plan FOR SELECT*FROMhistograms_testWHEREskewVal = 1;SELECT*FROMTABLE ( dbms_xplan.display );
explain plan FOR SELECT*FROMhistograms_testWHEREskewVal = 10000;SELECT*FROMTABLE ( dbms_xplan.display );
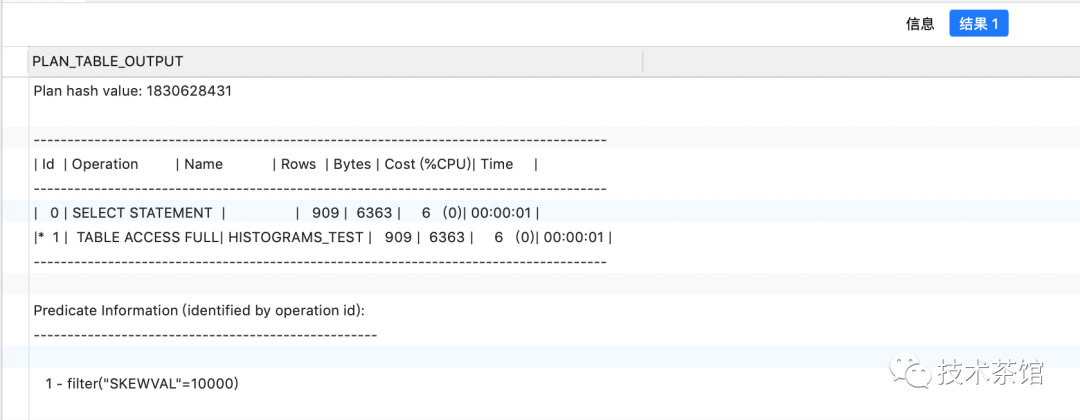
因为oracle假设列skew中的数据是均匀分布的所以基数评估
cardinality=density*num_rows=0.09090901*10000=909.09四舍五入就是909行。但是我们知道skewVal=1的记录只有1行,而skewVal=10000的记录有9990行.这种假设必然导致错误的执行计划.例如,如果我们在列skewVal上创建一个B树索引,oracle将使用对谓词skewVal=10000行使用索引扫描并返回909行记录。
CREATE INDEX histograms_test_index ON histograms_test ( skewVal );call dbms_stats.gather_index_stats ( USER, 'histograms_test_index' );explain plan FOR SELECT*FROMhistograms_testWHEREskewVal = 10000;SELECT*FROMTABLE ( dbms_xplan.display );
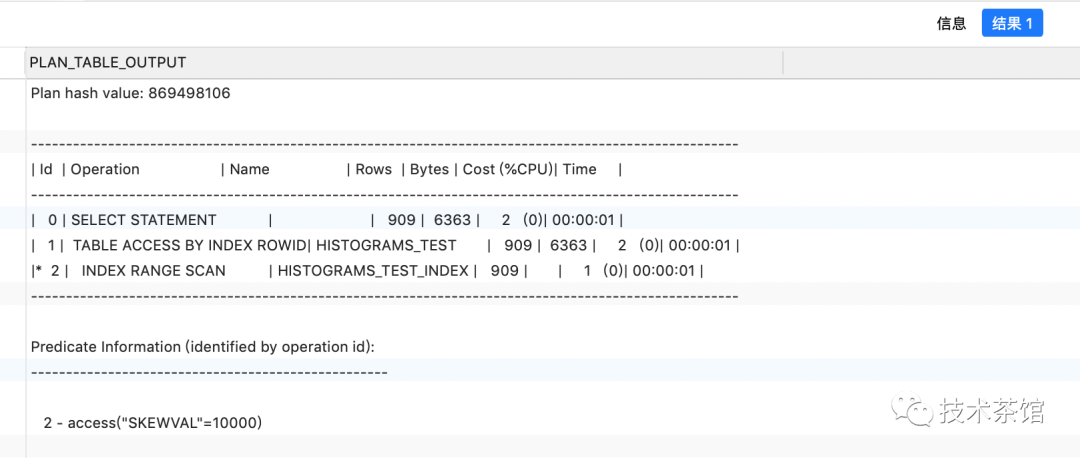
因为我们没有给出关于数据分布的额外信息,CBO假设列中的数据在最小值和最大值之间是均匀分布的所以选择了错误的执行计划。那么如何处理这种情况,这就引入了直方图的概念。
一旦对列创建直方图后,它将告诉CBO列中数据出现的频率。所以在上面的例子中如果对skewVal列创建直方图,它将告诉CBO skewVal=1的值只出现一次,skewVal=10000的值出现了9990次。因此它能让优化器选择最优的执行计划。
直方图
直方图(Histogram)是 RDBMS 中提供的一种基础的统计信息,最典型的用途是估计查询谓词的选择率,以便选择优化的查询执行计划。常见的直方图种类有:等宽直方图、等高直方图、V-优化的直方图,MaxDiff 直方图等等。RDBMS 产品最初使用的直方图非常简单(只有一个桶),后来逐步演化到等宽直方图、等高直方图等。
等宽直方图
等宽直方图列中的不同值被划到相同数量的桶中。每一个桶中存储的都是相同的值,也就是说等宽直方图的桶数等于列的不同值的个数。buckets=ndv
下面对skewVal创建等宽直方图,并查看数据是怎么存放到数据字典视图中的
--对列skewVal创建了有11个桶的直方图call dbms_stats.gather_table_stats(user,'histograms_test',method_opt=>'for columns skewVal size 11');
查看数据字典中直方图数据
SELECTcolumn_name,endpoint_number,endpoint_valueFROMuser_tab_histogramsWHEREtable_name = upper('histograms_test')AND column_name = upper('skewVal');
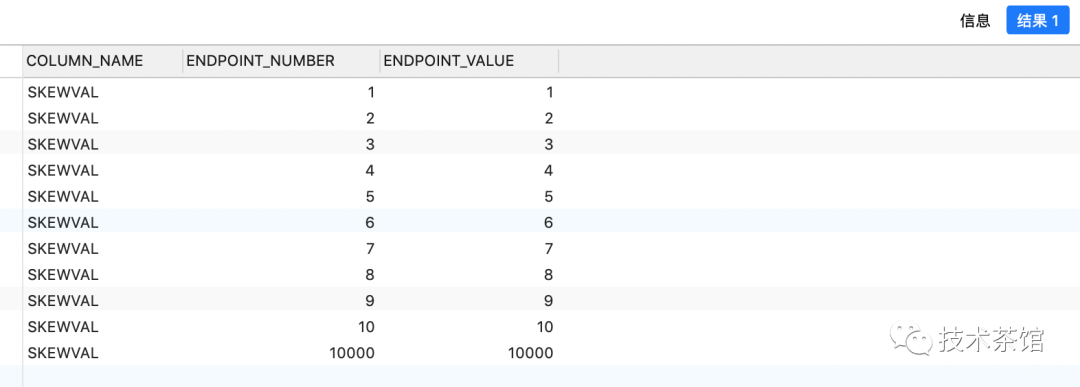
- column_name 显示的是列名称
- endpoint_value显示的是真实的列值
- endpoint_number显示的是累积的行数或者是累积的频率
为了计算一个特定列值的频率需使用与它相关的endpoint_number值减去它之前的累积值。如下所示
对于endpoint_value为5的值,它的endpoint_number为5,之前的endpoint_number为4,因上skewVal=5的记录只有5-4=1行.类似的对于endpoint_value为10000的值它的endpoint_number为10000它之前的endpoint_number为10,所以skewVal=10000的记录有10000=10=9990行。
使用下面的sql来解释说明数据字典中的直方图信息:
SELECTendpoint_value AS column_value,endpoint_number AS cummulative_frequency,endpoint_number - lag ( endpoint_number, 1, 0 ) over ( ORDER BY endpoint_number ) AS frequencyFROMuser_tab_histogramsWHEREtable_name = upper('histograms_test')AND column_name = upper('SKEWVAL');
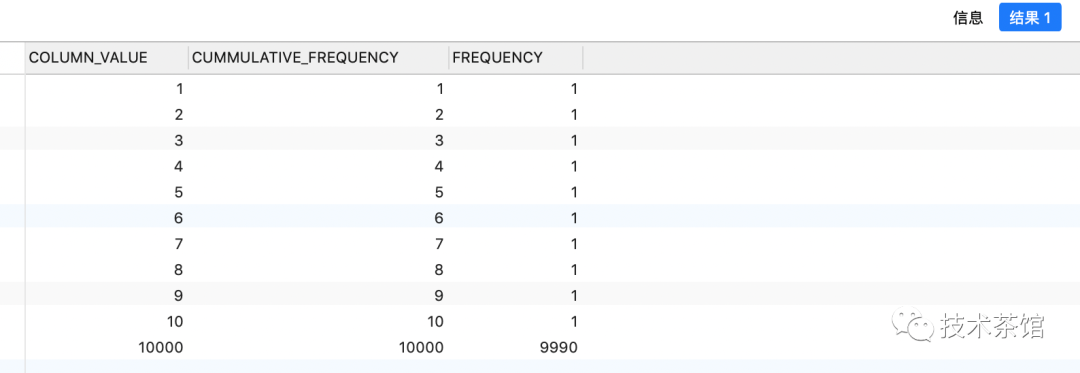
累积频率来代替单个频率在范围扫描时是特别有用的,对于像 where skewVal < =10这样的谓词。
我们对skewVal列创建了直方图再来查看之前的查询有什么不同:
SELECTcolumn_name,num_distinct,density,histogramFROMuser_tab_col_statisticsWHEREtable_name = upper('histograms_test');
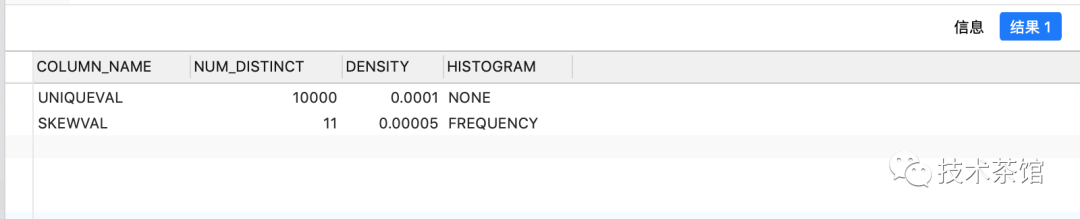
- column_name: 列名称;
- num_distinct: 该列中唯一值的数量;
- density列的统计信息用来估计 equi-join predicates和 equality predicates的选择性。density用0到1之间的一个小数来表达。当其值越接近与1,代表的该列的选择性越差,越接近与0,代表该列的选择性越高。当列的选择性越高,那么谓词查询时返回的rows 越少,这样查询的效率就高列的选择性是用来决定执行计划的一个重要部分;
- histogram: 表明是否有直方图统计信息,如果有是哪种类型,none表示没有,frequency表示频率类型,height balanced表示平均分布类型;
explain plan FOR SELECT*FROMhistograms_testWHERESKEWVAL = 10000;select * from table(dbms_xplan.display);
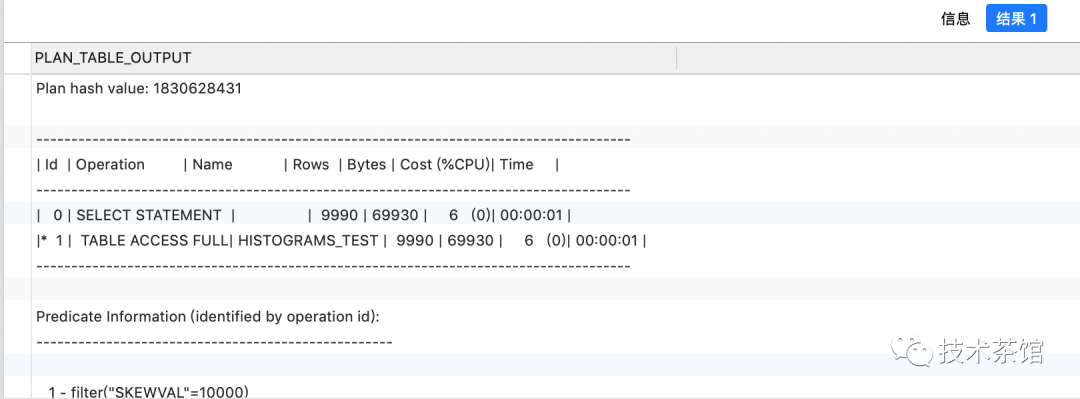
explain plan FOR SELECT*FROMhistograms_testWHERESKEWVAL = 1;select * from table(dbms_xplan.display);
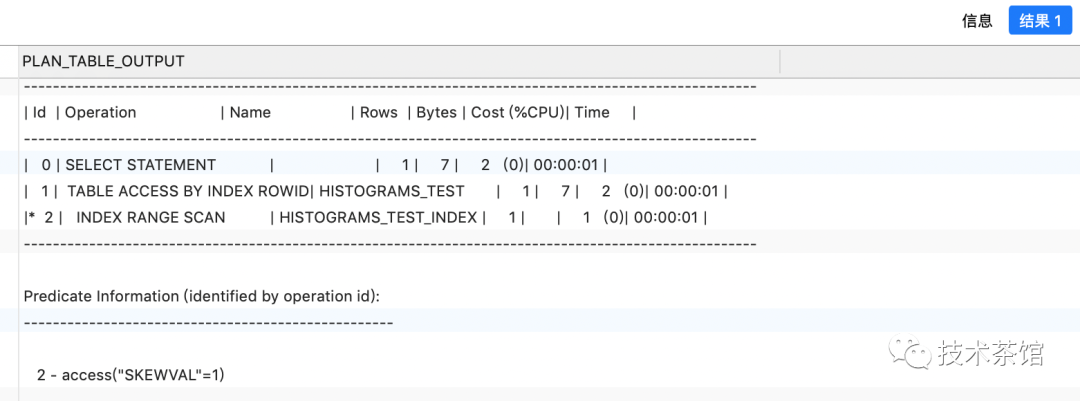
现在优化器对于谓词skewVal=10000选择了全表扫描且能精确计算出它的基数9990。注意现在skewVal列的density值变成了0.00005也就是1/(2*num_rows)或者0.5/num_rows。
等宽(singleton)直方图,每个桶只有一个值,保存该值和累积的频率。
等高直方图
等高直方图,于 1984 年在 Accurate estimation of the number of tuples satisfying a condition 文献中提出。相比于等宽直方图,等高直方图在最坏情况下也可以很好的保证误差。所谓的等高直方图,就是落入每个桶里的值数量尽量相等。
举个例子,比方说对于给定的集合 {1.6, 1.9, 1.9, 2.0, 2.4, 2.6, 2.7, 2.7, 2.8, 2.9, 3.4, 3.5},并且生成 4 个桶,那么最终的等高直方图就会如下图所示,包含四个桶 [1.6, 1.9], [2.0, 2.6], [2.7, 2.8],[2.9, 3.5],其桶高度均为 3。
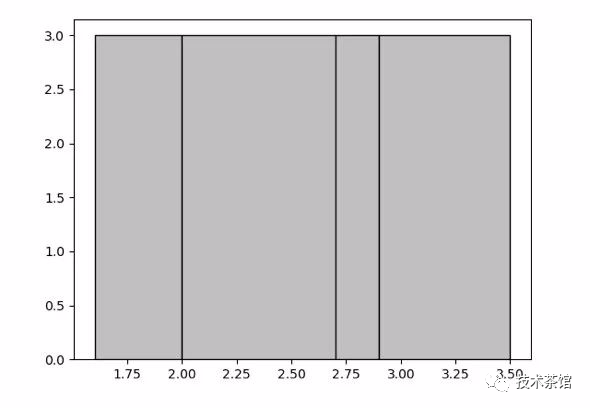
等高(equi-height),每个桶保存上下限,累积频率以及不同值的个数。
等宽直方图VS等高直方图
- 列中不同值的个数小于直方图的桶数采用的是等宽的直方图。
- 列中不同值的个数大于直方图的桶数采用的是等高的直方图。
直方图的目的
默认情况下,优化器假定列的不同值之间是均匀分布的。对于包含数据倾斜列(列中数据的分布不均匀的列),直方图使优化器能够为涉及这些列的过滤或连接谓词生成更准确的基数的估计值,从而生成更精确的执行计划。
结论
本文介绍了统计信息相关的内容,数据库统计信息在SQL优化起到重要作用。统计信息可以让数据库优化器找到比较好的执行路径。直方图是对基本数据的估计,任何直方图都不是精确的。一般在生产环境下以最小代价获取统计数据是基本前提。通常情况下从备库获取统计数据、只统计最近数据、采取抽样的方式获取数据、不抽取原始数据,只对数据的hash值进行统计。
参考资料
- 《数据库查询优化器的艺术:原理解析与SQL性能优化》
- https://zhuanlan.zhihu.com/p/39139693
-
《高性能MySQL》
-
https://jira.mariadb.org/browse/MDEV-4145
- https://mariadb.com/kb/en/histogram-based-statistics/

微信公众号名称:技术茶馆
微信公众号ID : Night_ZW

















 585
585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









