







 超级会员免费看
超级会员免费看
1 简介
在本节中,我们重新拾起是什么让一个文本不同与其他文本这样的问题, 并使用程序自动寻找特征词汇和文字表达。
正如在上一节中那样,可以通过复制它们到 Python 解释器中来尝试Python 语言的新特征。
在这之前,你可能会想通过预测下面的代码的输出来检查你对上一节的理解。你可以使用解释器来检查你是否正确。如果你不确定如何做这个任务, 你最好在继续之前复习一下上一节的内容。

2 频率分布
我们如何能自动识别文本中最能体现文本的主题和风格的词汇?试想一下,要找到一本书中使用最频繁的 50 个词你会怎么做?
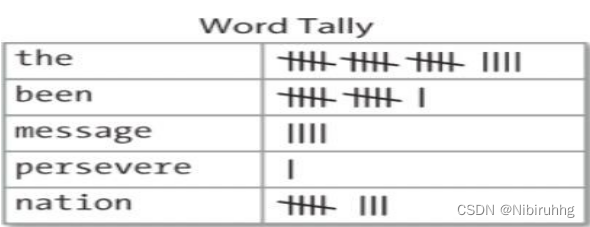
上表被称为频率分布,它告诉我们在文本中的每一个词项的频率。一般情况下, 它能计数任何观察得到的事件。这是一个“分布”因为它告诉我们文本中词标识符的总数是如何分布在词项中的。因为我们经常需要在语言处理中使用频率分布,NLTK 中内置了它们。
【例3 - 1 】使用 Freq Dist 寻找《白鲸记》中最常
 本文探讨了如何使用Python的NLTK库进行简单的统计分析,以识别文本中的关键词汇和表达。通过频率分布,我们可以找到文本中最常出现的词,进一步了解文本的主题。同时,文章介绍了如何筛选长词和检测词语搭配,以深入挖掘文本信息。
本文探讨了如何使用Python的NLTK库进行简单的统计分析,以识别文本中的关键词汇和表达。通过频率分布,我们可以找到文本中最常出现的词,进一步了解文本的主题。同时,文章介绍了如何筛选长词和检测词语搭配,以深入挖掘文本信息。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









