







 本文详细探讨了 Go 语言中的并发模型、Channel 实现原理、数据结构(如 Context、slice 和 Varint 编码)、内存管理和垃圾回收机制、调度器的工作原理以及最佳实践。特别强调了 Channel 的关闭策略、sync 包的使用,以及 Golang 的调度器如何通过 M、P、G 三者协作实现高效的并发执行。文章深入浅出地分析了 Go 语言的诸多核心知识点,对于理解和优化 Go 代码有着极大的帮助。
本文详细探讨了 Go 语言中的并发模型、Channel 实现原理、数据结构(如 Context、slice 和 Varint 编码)、内存管理和垃圾回收机制、调度器的工作原理以及最佳实践。特别强调了 Channel 的关闭策略、sync 包的使用,以及 Golang 的调度器如何通过 M、P、G 三者协作实现高效的并发执行。文章深入浅出地分析了 Go 语言的诸多核心知识点,对于理解和优化 Go 代码有着极大的帮助。
数据结构
Context
Context的调用链: 和链表有点像,只是它的方向相反:Context 指向它的父节点,链表则指向下一个节点
重要概念:(源码位置:src/context/context.go)
主要的context结构: emptyCtx, cancelCtx, timerCtx, valueCtx
parentCancelCtx(parent Context): 往上寻找第一个可以cancel的context
propagateCancel(parent Context, child canceler): 每次依据一个context创建另一个可取消的context时,都要往上去找到第一个可取消的context,然后将当前的canceler挂到那个节点下面,这样当父节点执行取消的时候,所有子节点都要被取消(通过执行创建子节点context时挂载的canceler即可)
cancel(removeFromParent bool, err error) : 只有在当前context执行取消的时候,removeFromParent = true,避免导致重复close done channel), 执行子节点取消的时候(removeFromParent = false)。
1. 当父节点取消的时候,子节点也会取消并且删除父节点挂载的所有子节点的canceler。
2. 当子节点先取消时,需要将父节点的挂载的当前子节点canceler删除,这样可以避免重复调用已经cancel的节点(虽然重复调用cancal是幂等的,已经取消的会记录err,通过判断err是否为nil就知道是否已经cancel了)。
Channel
1. CSP模型
传统的并发模型主要分为 Actor 模型和 CSP 模型,CSP 模型全称为 communicating sequential processes
CSP 模型由并发执行实体(进程,线程或协程)和消息通道组成,实体之间通过消息通道发送消息进行通信。
CSP模型关注的是消息发送的载体,即通道,而不是发送消息的执行实体。
Go 语言的并发模型参考了 CSP 理论,其中执行实体对应的是 goroutine, 消息通道对应的就是 channel
2. channel介绍
channel和 map 类似,make 创建了一个底层数据结构的引用,当赋值或参数传递时,只是拷贝了一个 channel 引用,指向相同的 channel 对象。和其他引用类型一样,channel 的空值为 nil 。使用 == 可以对类型相同的 channel 进行比较,只有指向相同对象或同为 nil 时,才返回 true,channel 一定要初始化后才能进行读写操作,否则会永久阻塞。通过内置的 close 函数对 channel 进行关闭操作。
3. channel 的关闭
关闭 channel 会产生一个广播机制(如何实现?),所有向 channel 读取消息的 goroutine 都会收到消息,这个机制也可以用来控制goroutine的生命周期(配合select使用)
4. channel的类型channel 分为不带缓冲的 channel 和带缓冲的 channel
5. channel 的用法:
range 遍历
channel 也可以使用 range 取值,并且会一直从 channel 中读取数据,直到有 goroutine 对改 channel 执行 close 操作,循环才会结束
6. 单向 channel
可以防止 channel 被滥用,这种防机制发生再编译期间
Pipeline 模式
func build( in <-chan string) <-chan string {
// 可以是带有缓冲的,因为out返回是只读模式,不写就没事,提前close掉,不会影响程序正常运行,
// 主要是防止goroutine泄露,不退出
out := make(chan string)
go func() {
defer close(out)
for c := range in {
out <- "custom build operation func call with paramter 'c' and return new string"
}
}()
return out
}Fall in / Fall out
新增的 merge 函数的核心逻辑就是对输入的每个 channel 使用单独的协程处理,并将每个协程处理的结果都发送到变量 out 中,达到Fall in的目的。总结起来就是通过多个协程并发,把多个 channel 合成一个
func merge(ins … <-chan string) <-chan string {
var wg sync.WaitGroup
out := make(chan string)
// 处理其中某个流的操作
process := func (in <-chan string) {
defer wg.Done()
for c:= range in {
out <- “func(c)"
}
}
wg.Add(len(ins))
// Fall in
for _, in := range ins {
go process(in)
}
// 处理关闭channel的逻辑,以防goroutine泄露
go func() {
wg.Wait()
close(out)
}()
return out
}Channel实现原理
channel 的主要组成有:
一个环形数组实现(主要是针对:有缓冲区的channel) 的队列,用于存储消息元素;
两个链表实现的 goroutine 等待队列,用于存储阻塞在 recv 和 send 操作上的 goroutine;
一个互斥锁,用于各个属性变动的同步;
channel send
逻辑处理顺序
当 channel 未初始化或为 nil 时,向其中发送数据将会永久阻塞
已经关闭的(closed)channel 发送消息会产生 panic
CASE1: 当有 goroutine 在 recv 队列上等待时,跳过缓存队列,将消息直接发给 reciever goroutine
CASE2: 缓存队列未满,则将消息复制到缓存队列上
CASE3: 缓存队列已满,将goroutine 加入 send 队列
send几种情况说明:
有 goroutine 阻塞在 channel recv 队列上,此时缓存队列为空,直接将消息发送给 reciever goroutine,只产生一次复制
当 channel 缓存队列有剩余空间时,将数据放到队列里,等待接收,接收后总共产生两次复制
当 channel 缓存队列已满时,将当前 goroutine 加入 send 队列并阻塞。
channel recieve
逻辑处理顺序
从 nil 的 channel 中接收消息,永久阻塞
CASE1: 从已经 close 且为空的 channel recv 数据,返回空值
CASE2: send 队列不为空 (发送者先开启了,接受者后开启导致的)
缓存队列为空,直接从 sender recv 元素
缓存队列不为空,此时只有可能是缓存队列已满,从队列头取出元素,并唤醒 sender 将元素写入缓存队列尾部。由于为环形队列,因此,队列满时只需要将队列头复制给 reciever,同时将 sender 元素复制到该位置,并移动队列头尾索引,不需要移动队列元素
CASE3: 缓存队列不为空,直接从队列取元素,移动队头索引
CASE4: 缓存队列为空,将 goroutine 加入 recv 队列,并阻塞(调用gopark 会使当前 goroutine 休眠)
Channel总结
无缓冲的 channel 是同步的,而有缓冲的 channel 是非同步的
两处会引起panic的操作:
1.关闭一个 nil channel 将会发生 panic, 2. 给一个已经关闭的 channel 发送数据,引起 panic
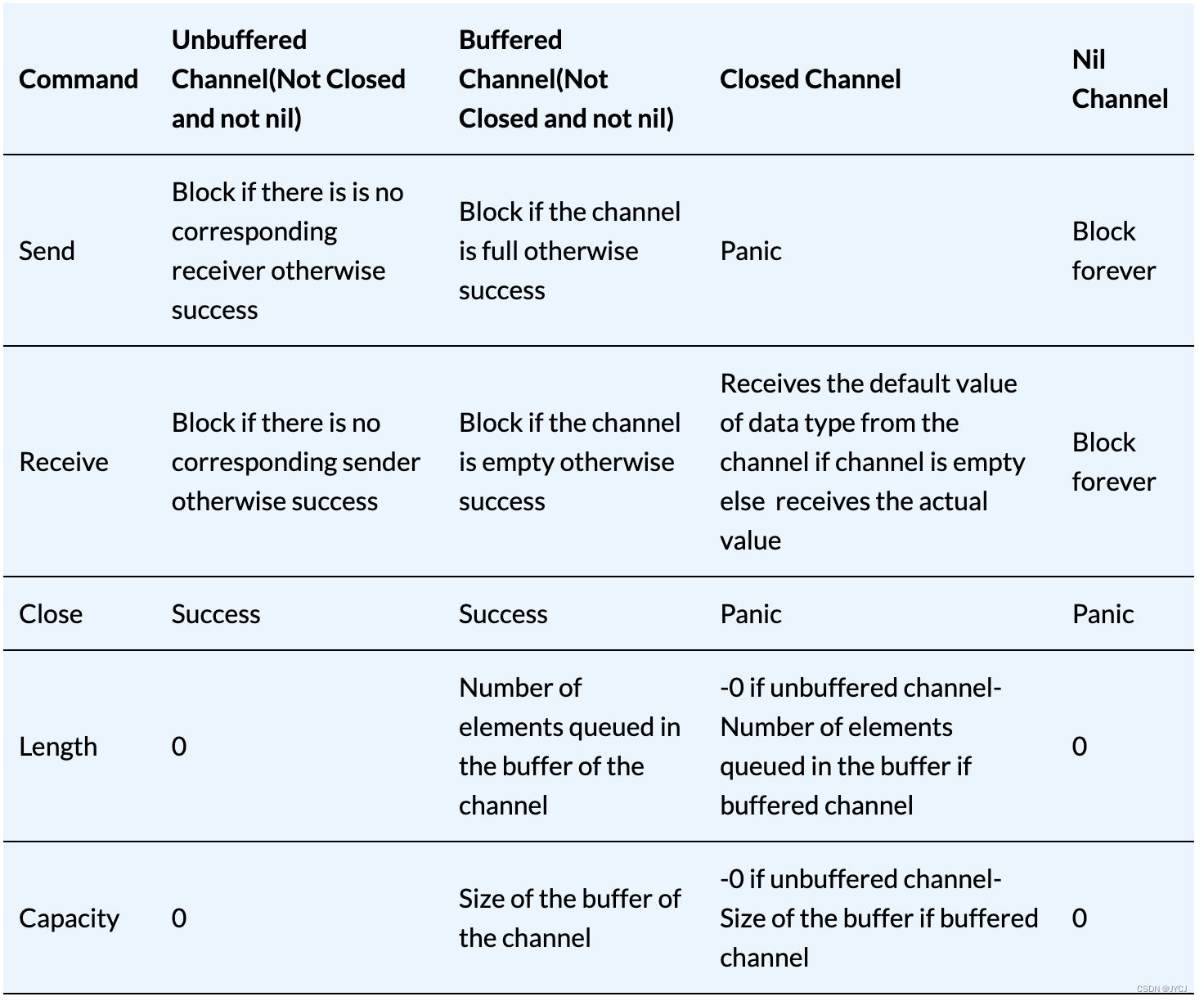
如何优雅的关闭channel
原则:don’t close (or send values to) closed channels
根据 sender 和 receiver 的个数,分下面几种情况:
一个 sender,一个 receiver
一个 sender, M 个 receiver
N 个 sender,一个 reciver
N 个 sender, M 个 receiver
第1,2种情形下
只有一个 sender 的情况就不用说了,直接从 sender 端关闭就好了,没有问题。重点关注第 3,4 种情况。
第 3 种情形下
优雅关闭 channel 的方法是:
the only receiver says “please stop sending more” by closing an additional signal channel。
解决方案:就是增加一个传递关闭信号的 channel(stopCh),receiver 通过信号 channel 下达关闭stopCh channel 指令。senders 监听到关闭信号后,停止发送数据。
需要说明的是,可以不明确去关闭 dataCh。在 Go 语言中,对于一个 channel,如果最终没有任何 goroutine 引用它,不管 channel 有没有被关闭,最终都会被 gc 回收。所以,在这种情形下,所谓的优雅地关闭 channel 就是不关闭 channel,让 gc 代劳。
第 4 种情形下
优雅关闭 channel 的方法是:
any one of them says “let’s end the game” by notifying a moderator to close an additional signal channel。
这里有 M 个 receiver,如果直接还是采取第 3 种解决方案,由 receiver 直接关闭 stopCh 的话,就会重复关闭一个 channel,导致 panic。因此需要增加一个中间人(可以是后台协程,从带缓冲的channel中监听数据,读到数据前阻塞,有数据后立刻执行关闭stopCh操作,然后协程退出,只关闭了一次),M 个 receiver 都向它发送关闭 stopCh 的“请求”,中间人收到第一个请求后,就会直接下达关闭 stopCh 的指令(通过关闭 stopCh,这时就不会发生重复关闭的情况,因为 stopCh 的关闭只有中间人一个)。另外,这里的 N 个 sender 也可以向中间人发送信号关闭 stopCh 的请求。
slice
扩容算法
1. 如果需要的最小容量比2倍原有容量大,那么就取需要的容量;
2. 如果原有 slice 长度(len)小于 1024 那么每次就扩容为原来的2倍;
3. 如果原 slice 长度(len)大于等于 1024 那么每次扩容就扩为原来的1.25倍;
4. 除此之外扩容容量计算完成之后,还会进行一次内存对齐操作 )( 按照上面三条原则计算得到cap size后 * 8 取最接近 {0,8,16,32,48,64,80,96,112, …} 中的某个数 = capmem , 然后,new cap size =capmem / 8
注意: 可以使用 s2 = s1[:127:127] 的方式,重新构造一个与之前slice无关的新slice
大端小端字节序(两种存储数据的方式)
在计算机系统中,内存地址是按照一定规则排列的,通常是从低地址向高地址递增。这种地址排列方式被称为“从低地址到高地址的顺序”,也称为“小端序”(Little Endian)
例如,对于一个 32 位整数 0x12345678,它在内存中的存储方式如下所示:
地址 | 值
-----------------------
0x1000 | 0x78
0x1001 | 0x56
0x1002 | 0x34
0x1003 | 0x12可以看到,该整数的低字节(最右边的字节)存储在内存的低地址处,而高字节(最左边的字节)存储在内存的高地址处。
除了小端序,还有一种内存地址的排列方式是“从高地址到低地址的顺序”,也称为“大端序”(Big Endian)。在大端序中,整数的高字节存储在内存的低地址处,而低字节存储在内存的高地址处。这种内存地址的排列方式常用于一些网络协议和嵌入式系统中。
在 Golang 中,默认使用小端序。可以通过 encoding/binary 包中的函数来实现不同序的二进制数据的转换。
总结:
大端模式(Big Endian):高位字节排放在内存的低地址端,低位字节排放在内存的高地址端;
小端模式(Little Endian):低位字节排放在内存的低地址端,高位字节排放在内存的高地址端;
字节序列最小单位是一个字节
如何区分大小端
func IsLittleEndian() bool{
var value int32 = 1 // 占4byte 转换成16进制 0x00 00 00 01
// 大端(16进制):00 00 00 01
// 小端(16进制):01 00 00 00
pointer := unsafe.Pointer(&value)
pb := (*byte)(pointer)
if *pb != 1{
return false
}
return true
}
// 运行结果:ture大小端字节序转化
func SwapEndianUin32(val uint32) uint32 {
return (val & 0xff000000) >> 24 | (val & 0x00ff0000) >> 8 | (val & 0x0000ff00) << 8 | (val & 0x000000ff) <<24
}Varint编码
无符号整数
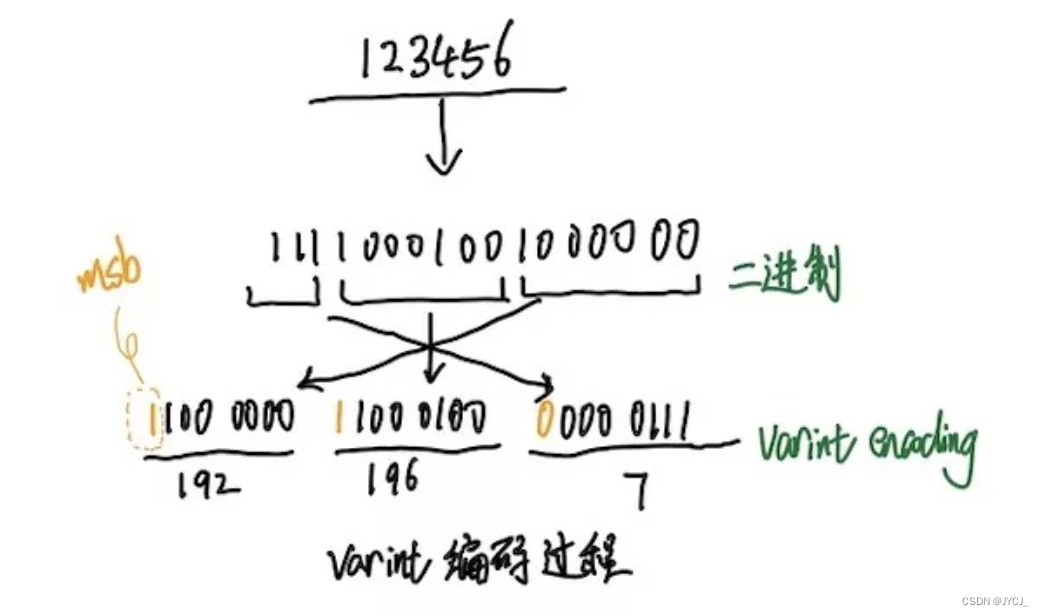
protocol buffer中大量使用了varint编码, Varint是一种使用一个或多个字节序列化整数的方法,会把整数编码为变长字节。
对于32位无符号整型数据经过Varint编码后需要1~5个字节,小的数字使用1个byte,大的数字使用5个bytes。
64位无符号整型数据编码后占用1~10个字节。
在实际场景中小数字的使用率远远多于大数字,因此通过Varint编码对于大部分场景都可以起到很好的压缩效果 。除了最后一个字节外,varint编码中的每个字节都设置了最高有效位(most significant bit - msb),msb为1则表明后面的字节还是属于当前数据的,如果是0那么这是当前数据的最后一个字节数据。
varint编码示意图:
代码实现
package main
import (
"encoding/binary"
"fmt"
)
// Varint 编码,返回编码后的字节数组
func encodeVarint(x uint64) []byte {
var buf [binary.MaxVarintLen64]byte
n := binary.PutUvarint(buf[:], x)
return buf[:n]
}
// Varint 解码,接收一个字节数组,返回解码后的 uint64 数据
func decodeVarint(buf []byte) uint64 {
x, _ := binary.Uvarint(buf)
return x
}
func main() {
// 测试数据
x := uint64(123456789)
y := uint32(987654321)
// 编码
encodedBufX := encodeVarint(x)
encodedBufY := encodeVarint(uint64(y))
// 解码
decodedX := decodeVarint(encodedBufX)
decodedY := uint32(decodeVarint(encodedBufY))
fmt.Printf("原始数据: %d, %d\n编码后数据: %v, %v\n解码后数据: %d, %d\n", x, y, encodedBufX, encodedBufY, decodedX, decodedY)
}
有符号整数
如果要对有符号整数类型进行变长编码,需要先将其转换成无符号整数类型,然后再进行编码。具体来说,可以通过 ZigZag 编码(也称为符号扩展编码)来实现这个转换。ZigZag 编码可以将一个有符号整数转换为一个无符号整数,同时保留了其相对大小,这样可以在编码时不失去原始信息。
代码实现
// 将 int64 编码为 varint 格式的 byte 数组
func encodeVarint64(value int64) []byt 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











